[JPoint 2017] Распределяй и властвуй — 2: Потоки данных наносят ответный удар
A presentation at Joker in in Moscow, Russia by Viktor Gamov

Распределяй и Властвуй -2: Потоки данных наносят ответный удар @gamussa @hazelcast #jpoint

Stream v. Batch

Кто?

Кто? Solutions Architect

Кто? Solutions Architect Developer Advocate

Кто? Solutions Architect Developer Advocate @gamussa везде в интернете

Кто? Solutions Architect Developer Advocate @gamussa везде в интернете А ты зафоловил меня, $userName ©

Part Deux?


Disclaimer: Нам пишут
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Нам пишут ? Из названия не было понятно, что это пропоганда хазлкаста, что не правильно. * авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Нам пишут ? Из названия не было понятно, что это пропоганда хазлкаста, что не правильно. * авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Нам пишут ? Из названия не было понятно, что это пропоганда хазлкаста, что не правильно. * авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Нам пишут ? Из названия не было понятно, что это пропоганда хазлкаста, что не правильно. ✓ Все так 😏
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Нам пишут ? Из названия не было понятно, что это пропоганда хазлкаста, что не правильно. ✓ Все так 😏 ✓ Читайте абстракт ✓ Как и Вы, я здесь в коммандировке
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Ham пишут
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Ham пишут ? Спикер … уделяет время лишь одному банальному примеру подсчёта слов в файле с использованием фреймворка их компании. * авторская орфография сохранена @gamussa @hazelcast #jpoint


Пакетная Обработка Данные в состоянии покоя @gamussa @hazelcast #jpoint

Данные и запросы Происхождение и обработка @gamussa @hazelcast #jpoint

@gamussa @hazelcast #jpoint

@gamussa @hazelcast #jpoint

Данньые… @gamussa @hazelcast #jpoint

Данньые… @gamussa @hazelcast #jpoint

Данньые… ✓ … привязаны ко времени ✓ … immutable по своей сути @gamussa @hazelcast #jpoint

CRUD -> CR Мариванна, в углу скр..© @gamussa @hazelcast #jpoint

Обработка – это запрос @gamussa @hazelcast #jpoint

Обработка – это запрос Функция по полному набору данных @gamussa @hazelcast #jpoint

Обработка – это запрос Функция по полному набору данных Проекции @gamussa @hazelcast #jpoint

Обработка – это запрос Функция по полному набору данных Проекции Агрегации @gamussa @hazelcast #jpoint

Обработка – это запрос Функция по полному набору данных Проекции Агрегации Joins @gamussa @hazelcast #jpoint
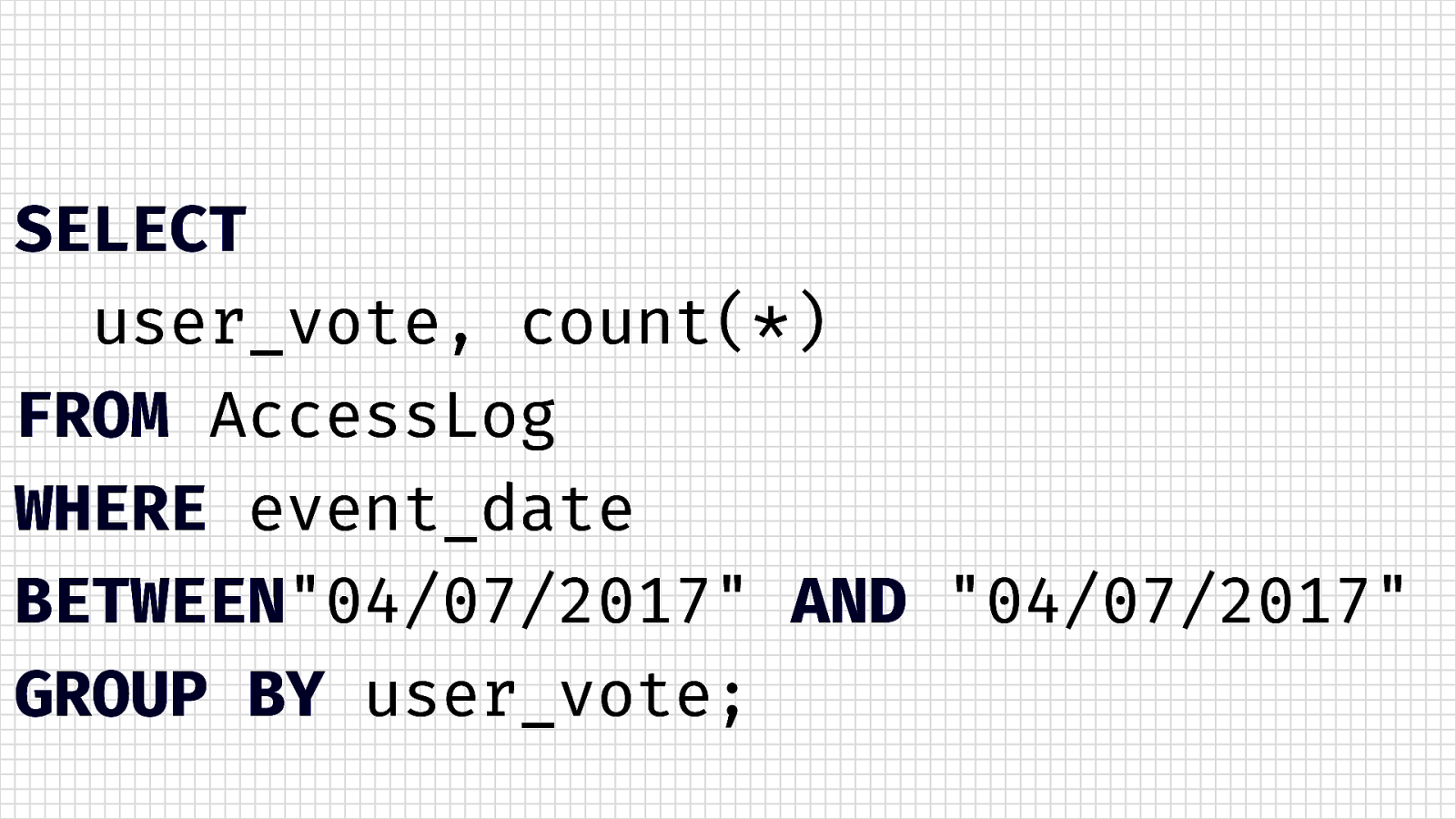
SELECT user_vote, count(*) FROM AccessLog WHERE event_date BETWEEN”04/07/2017” AND “04/07/2017” GROUP BY user_vote;
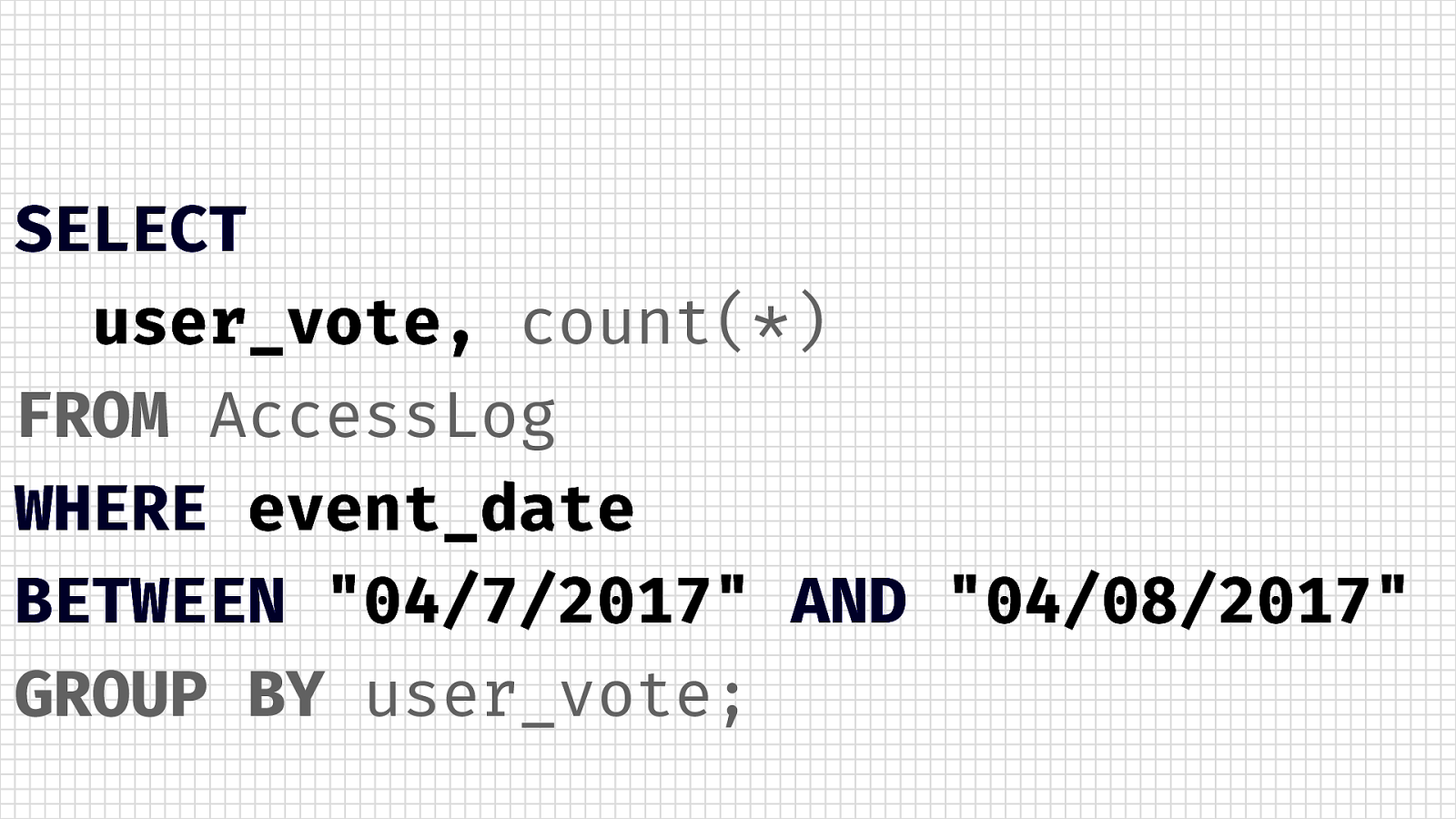
SELECT user_vote, count(*) FROM AccessLog WHERE event_date BETWEEN “04/7/2017” AND “04/08/2017” GROUP BY user_vote;
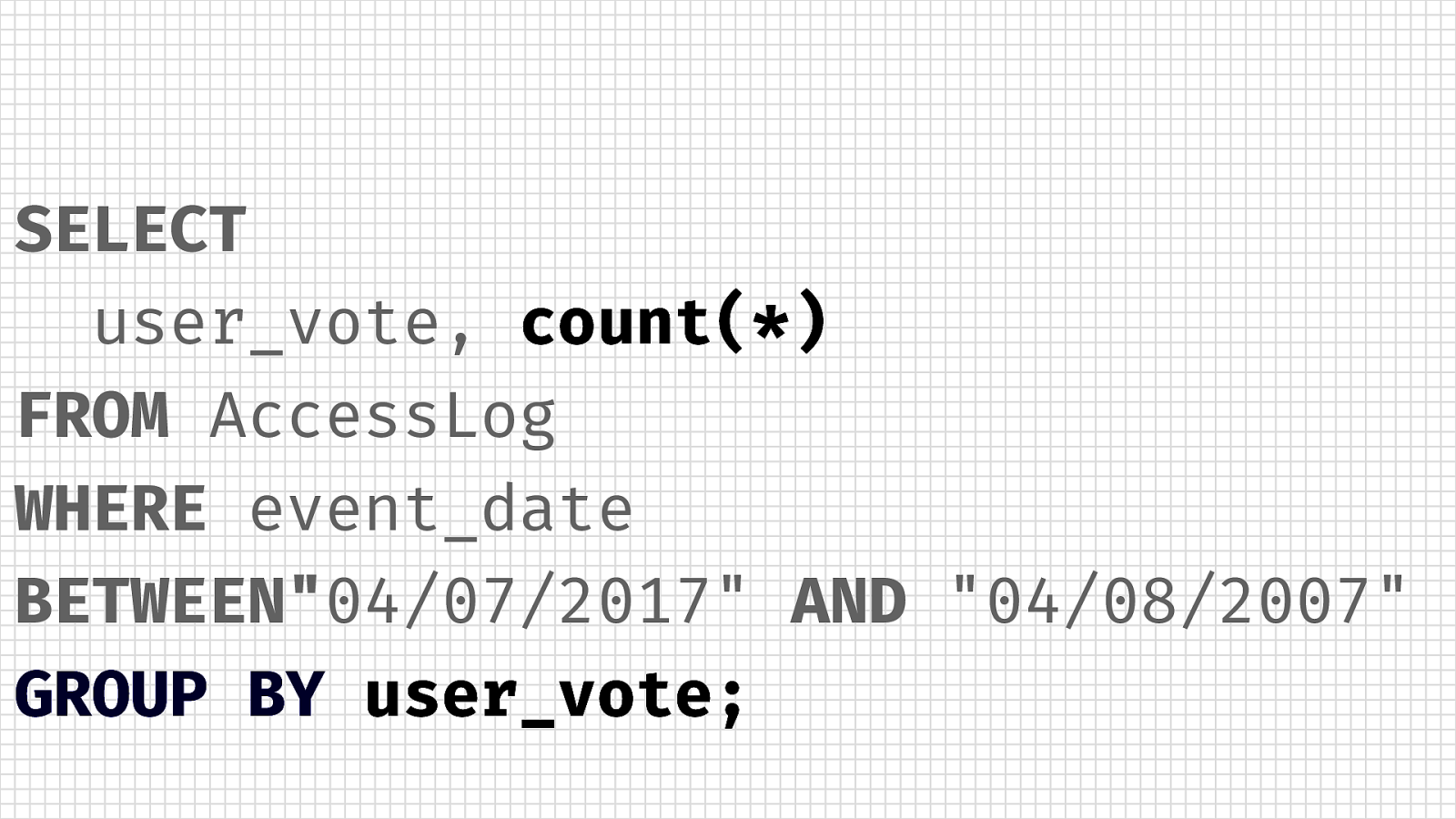
SELECT user_vote, count(*) FROM AccessLog WHERE event_date BETWEEN”04/07/2017” AND “04/08/2007” GROUP BY user_vote;

private static void countVotes(IMap<String, Vote> userVotes) { // execute the aggregation and print the result long countVotes = userVotes .aggregate(Aggregators.<String, Vote>count()); }


Lambda architecture origins http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html @gamussa @hazelcast #jpoint
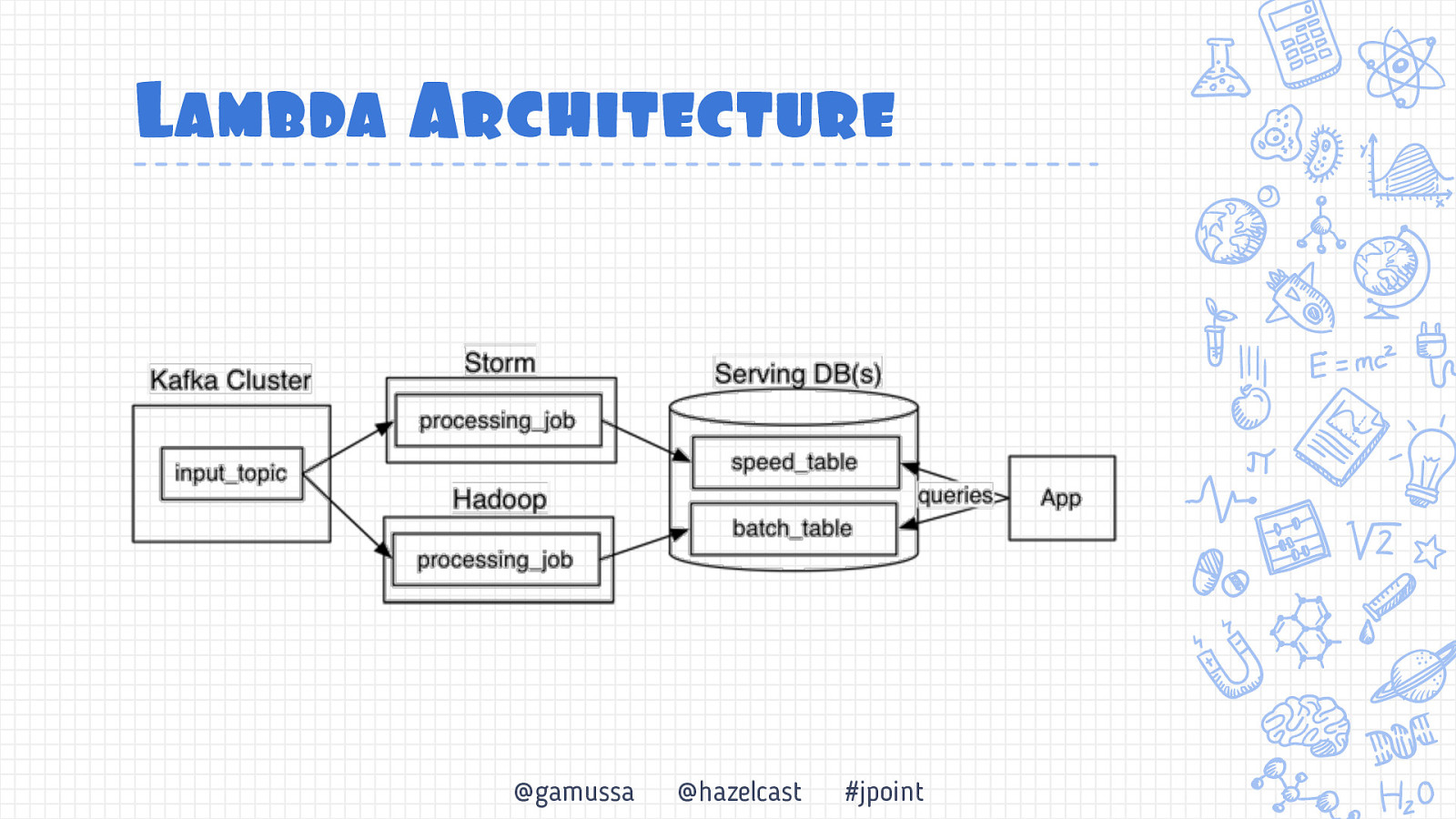
Lambda Architecture @gamussa @hazelcast #jpoint

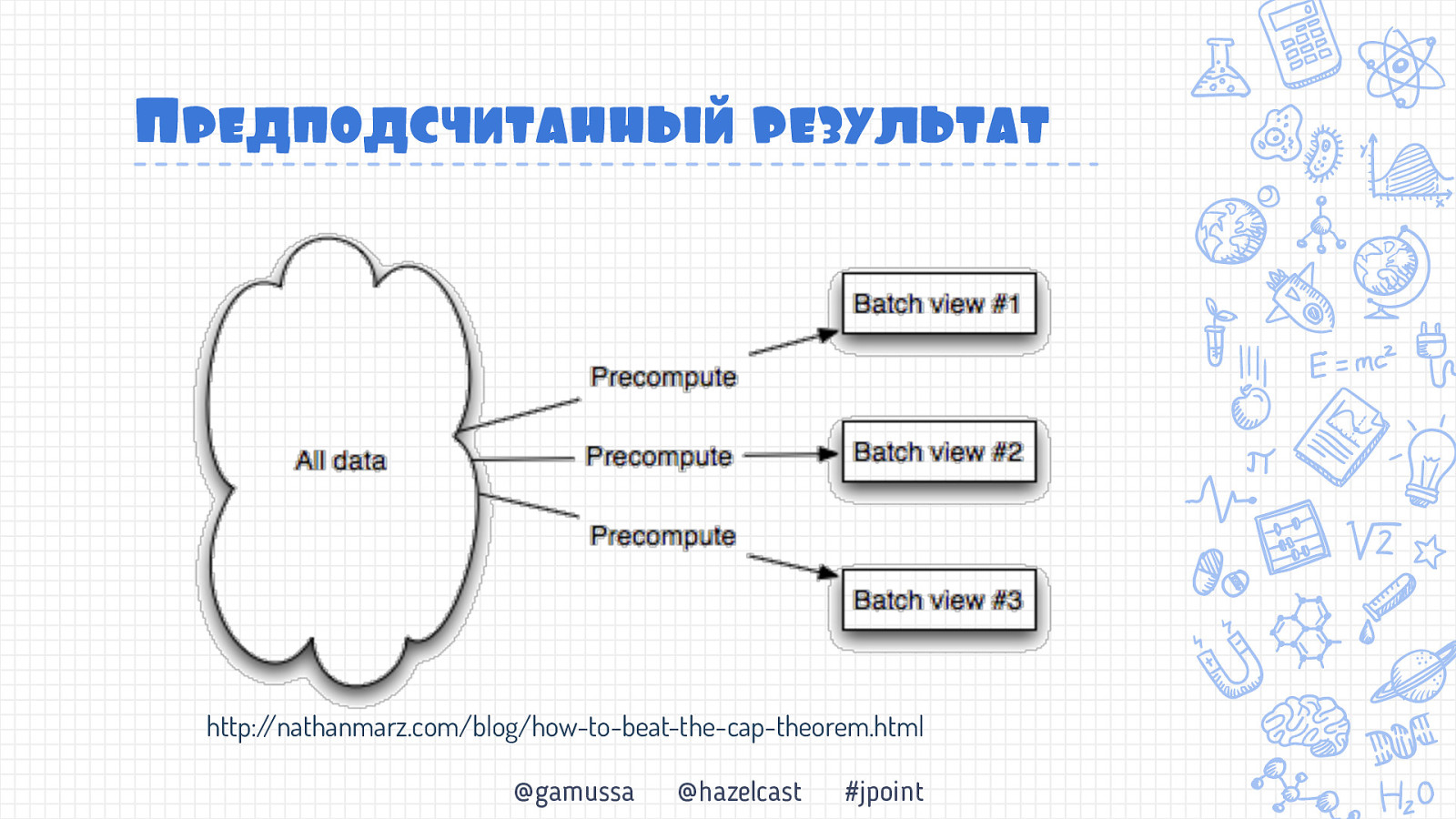
Предподсчитанньый результат http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html @gamussa @hazelcast #jpoint
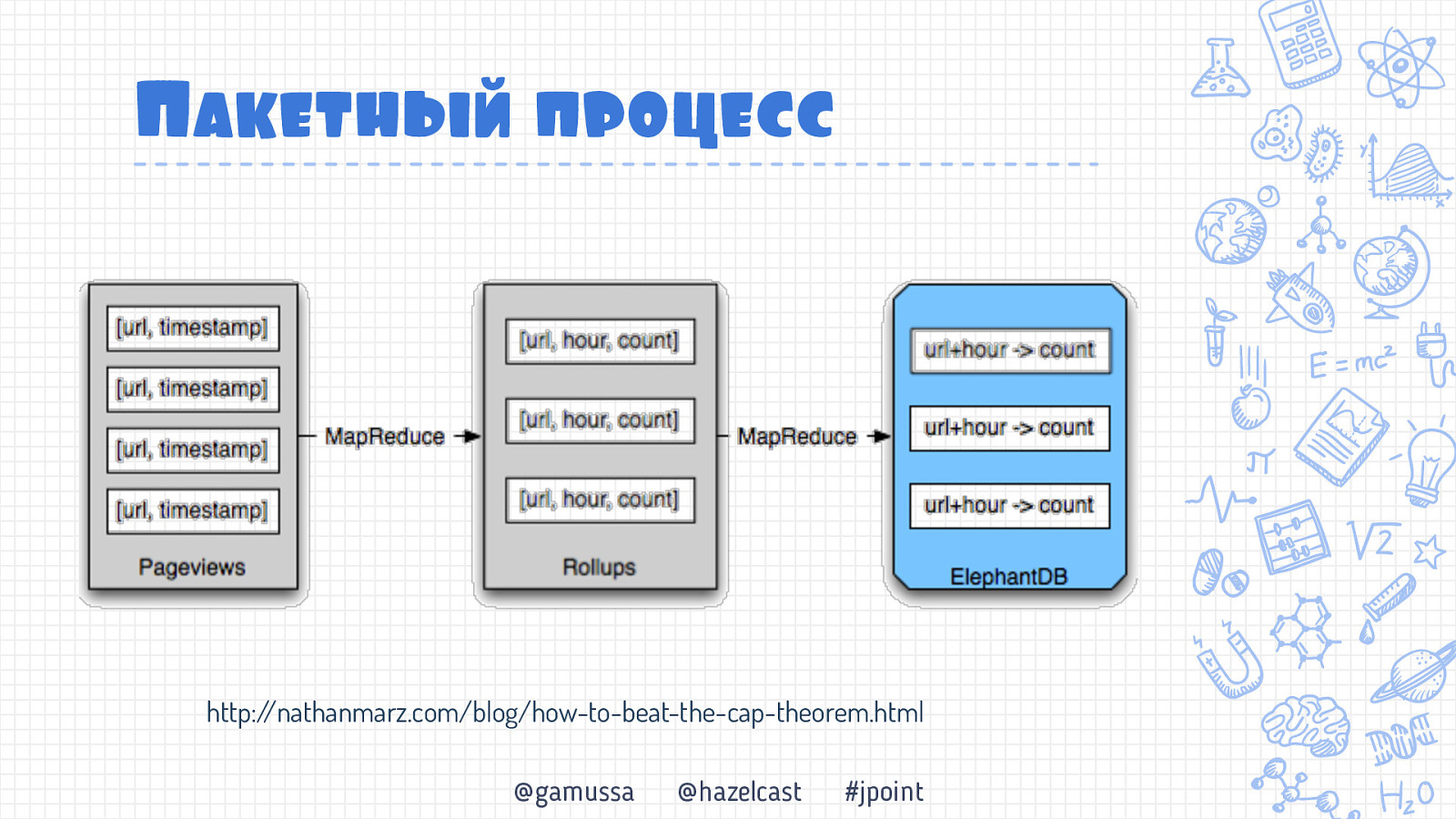
Пакетньый процесс http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html @gamussa @hazelcast #jpoint


Хранилище вьыдачи @gamussa @hazelcast #jpoint

Хранилище вьыдачи Очень легко читать @gamussa @hazelcast #jpoint

Хранилище вьыдачи Очень легко читать K,V – в идеале @gamussa @hazelcast #jpoint

Хранилище вьыдачи Очень легко читать K,V – в идеале Очень быстро читать @gamussa @hazelcast #jpoint

Хранилище вьыдачи Очень легко читать K,V – в идеале Очень быстро читать хранить в памяти @gamussa @hazelcast #jpoint

Хранилище вьыдачи Очень легко читать K,V – в идеале Очень быстро читать хранить в памяти хранить предподсчитанный результат @gamussa @hazelcast #jpoint

Данные слишком важны, чтобы хранить их на одной машине

Oracle Coherence @gamussa @hazelcast #jpoint

Oracle Coherence In-memory data grid @gamussa @hazelcast #jpoint

Oracle Coherence In-memory data grid Распределенные кэши @gamussa @hazelcast #jpoint

Oracle Coherence In-memory data grid Распределенные кэши Коммерческий продукт @gamussa @hazelcast #jpoint

Infinispan @gamussa @hazelcast #jpoint

Infinispan In-memory data grid @gamussa @hazelcast #jpoint

Infinispan In-memory data grid распределённые кэши @gamussa @hazelcast #jpoint

Infinispan In-memory data grid распределённые кэши Лицензия Apache v2 @gamussa @hazelcast #jpoint

Еще хотелки… @gamussa @hazelcast #jpoint

Еще хотелки… Простота @gamussa @hazelcast #jpoint

Еще хотелки… Простота знакомый API @gamussa @hazelcast #jpoint

Еще хотелки… Простота знакомый API встраиваемость @gamussa @hazelcast #jpoint

Еще хотелки… Простота знакомый API встраиваемость Cloud Native @gamussa @hazelcast #jpoint

Еще хотелки… Простота знакомый API встраиваемость Cloud Native @gamussa @hazelcast #jpoint

Псс, парень, Hazelcast IMDG, не хочешь? Ну очень быстрый грид © @gamussa @hazelcast #jpoint

Hazelcast IMDG, ьерем? @gamussa @hazelcast #jpoint

Hazelcast IMDG, ьерем? In-memory Data Grid @gamussa @hazelcast #jpoint

Hazelcast IMDG, ьерем? In-memory Data Grid Распределенные Кэши (IMap, JCache) Проекции, Агрегации Java колекции (IList, ISet, IQueue) Система обмена сообщений (Topic, RingBuffer) Вычисления (ExecutorService, M-R) @gamussa @hazelcast #jpoint


@gamussa @hazelcast #oraclecode
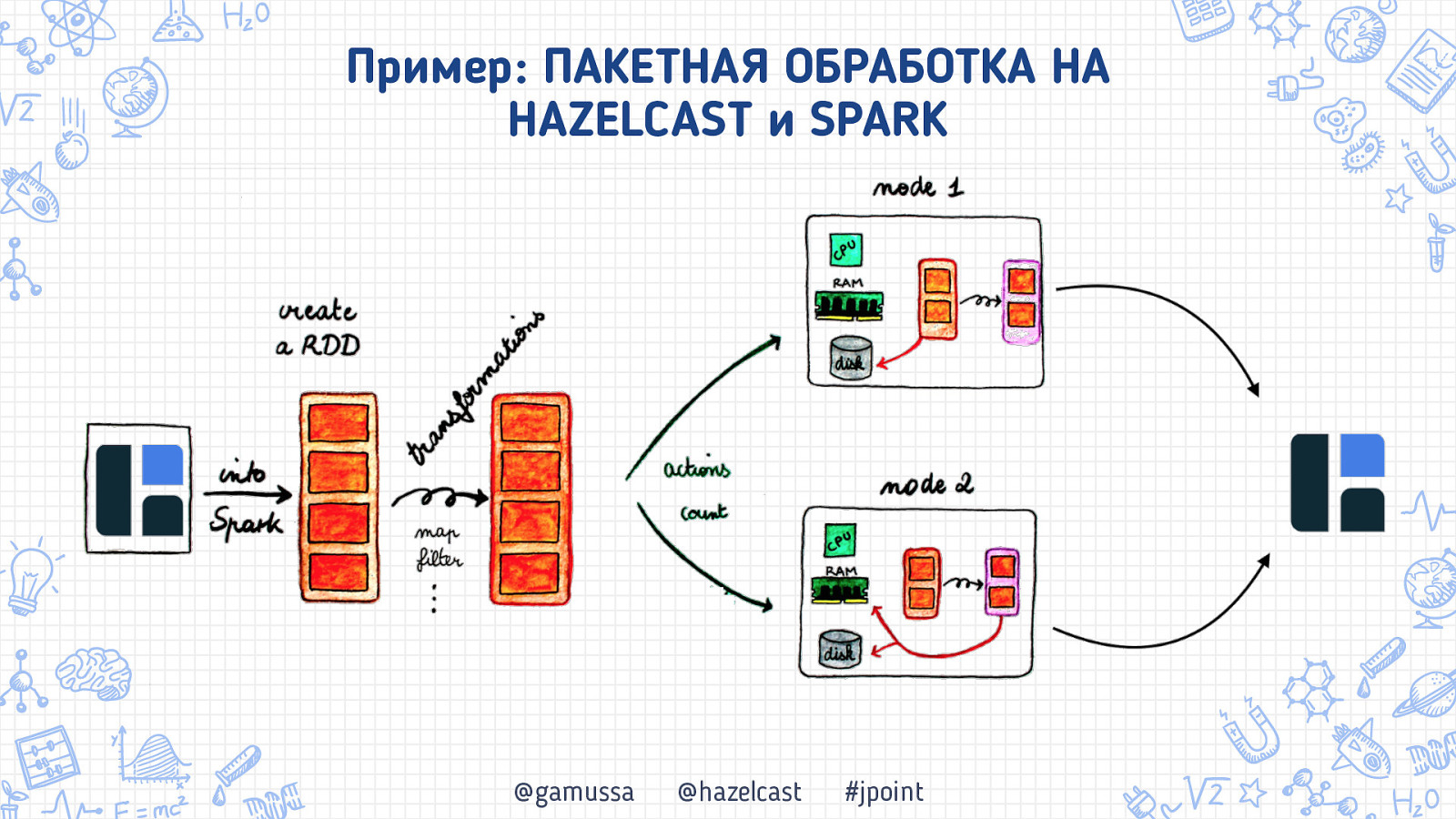
Пример: ПАКЕТНАЯ ОБРАБОТКА НА HAZELCAST и SPARK @gamussa @hazelcast #jpoint

ДАННЫЕ НЕ ДОЛЖНЫ ОБНОВЛЯТЬСЯ ВО ВРЕМЯ ЧТЕНИЯ @gamussa @hazelcast #jpoint

ПОЧЕМУ? @gamussa @hazelcast #jpoint

ПРИ РАСШИРЕНИИ, MAP ПЕРЕРАСПРЕДЕЛЯЕТ ДАННЫЕ ВНУТРИ КОНТЕЙНЕРА @gamussa @hazelcast #jpoint

КУРСОР НЕ УКАЗЫВАЕТ НА КОРРЕКТНУЮ ЗАПИСЬ. МОГУТ ВОЗНИКАТЬ ДУБЛИКАТЫ ИЛИ ДАННЫЕ ПРОПАДАТЬ @gamussa @hazelcast #jpoint

Потоковая обработка Данные в движении @gamussa @hazelcast #jpoint

Hazelcast Jet Считаем ваши слова. Быстро. В памяти @gamussa @hazelcast #jpoint
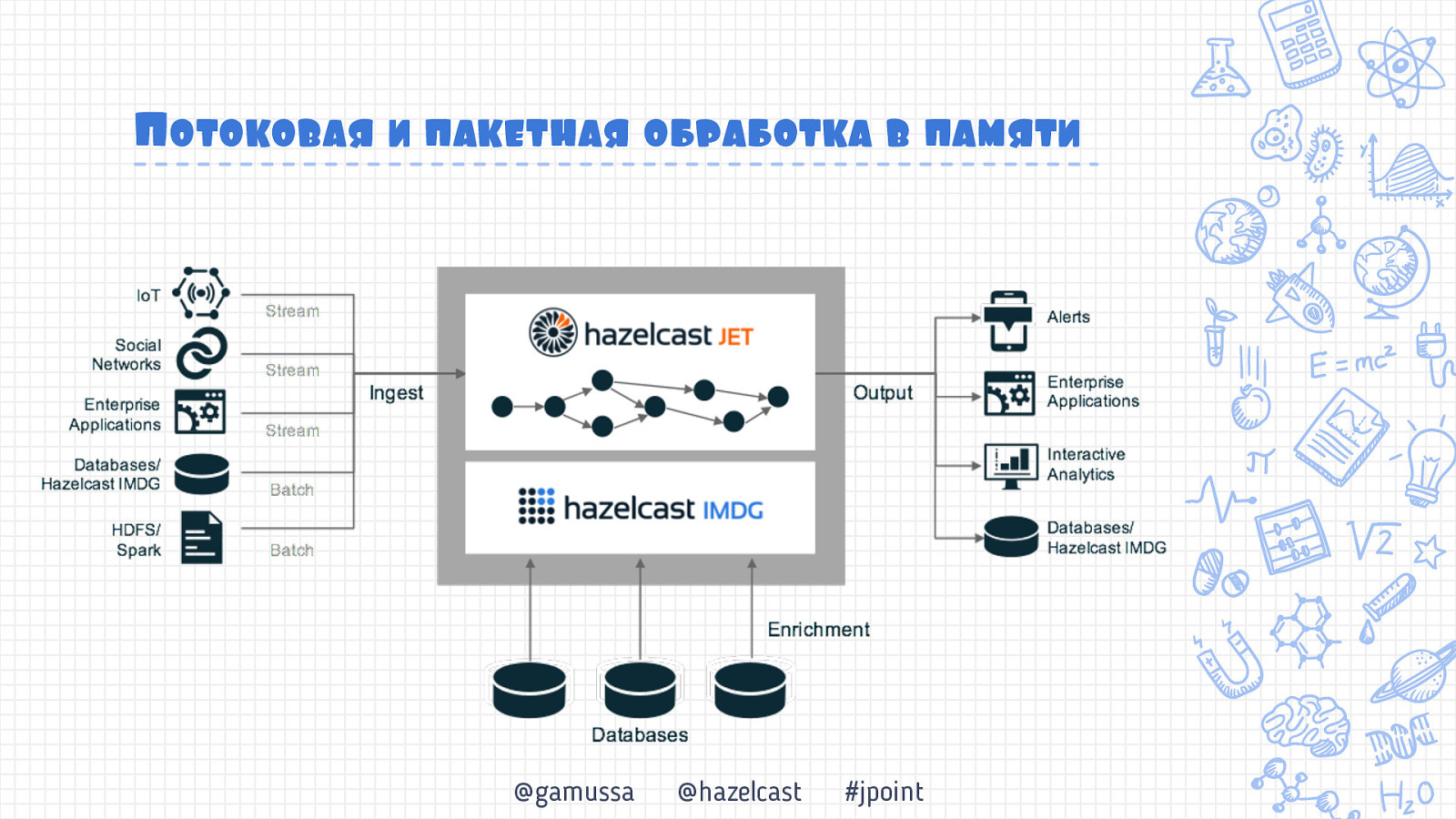
Потоковая и пакетная обработка в памяти @gamussa @hazelcast #jpoint
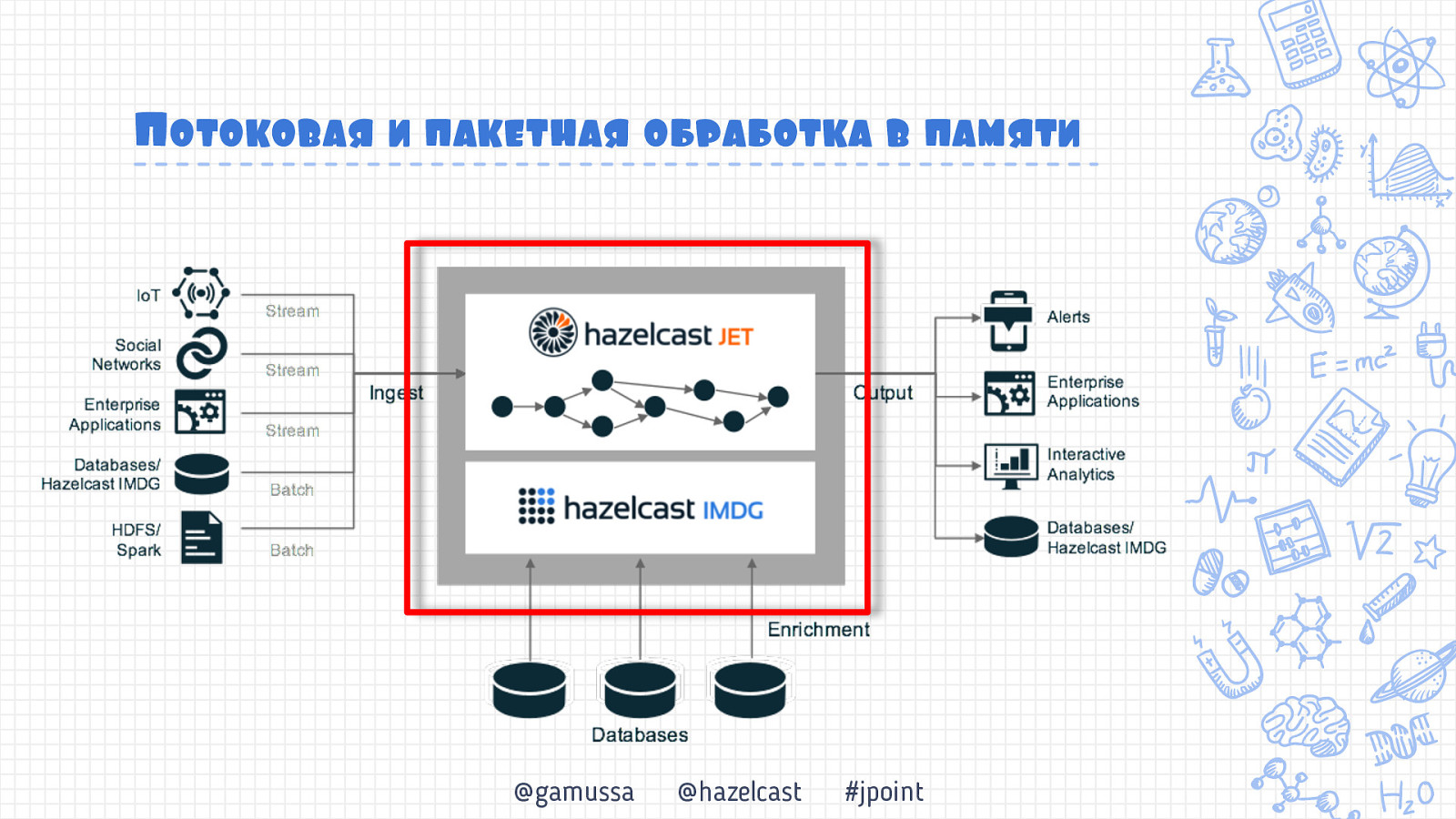
Потоковая и пакетная обработка в памяти @gamussa @hazelcast #jpoint
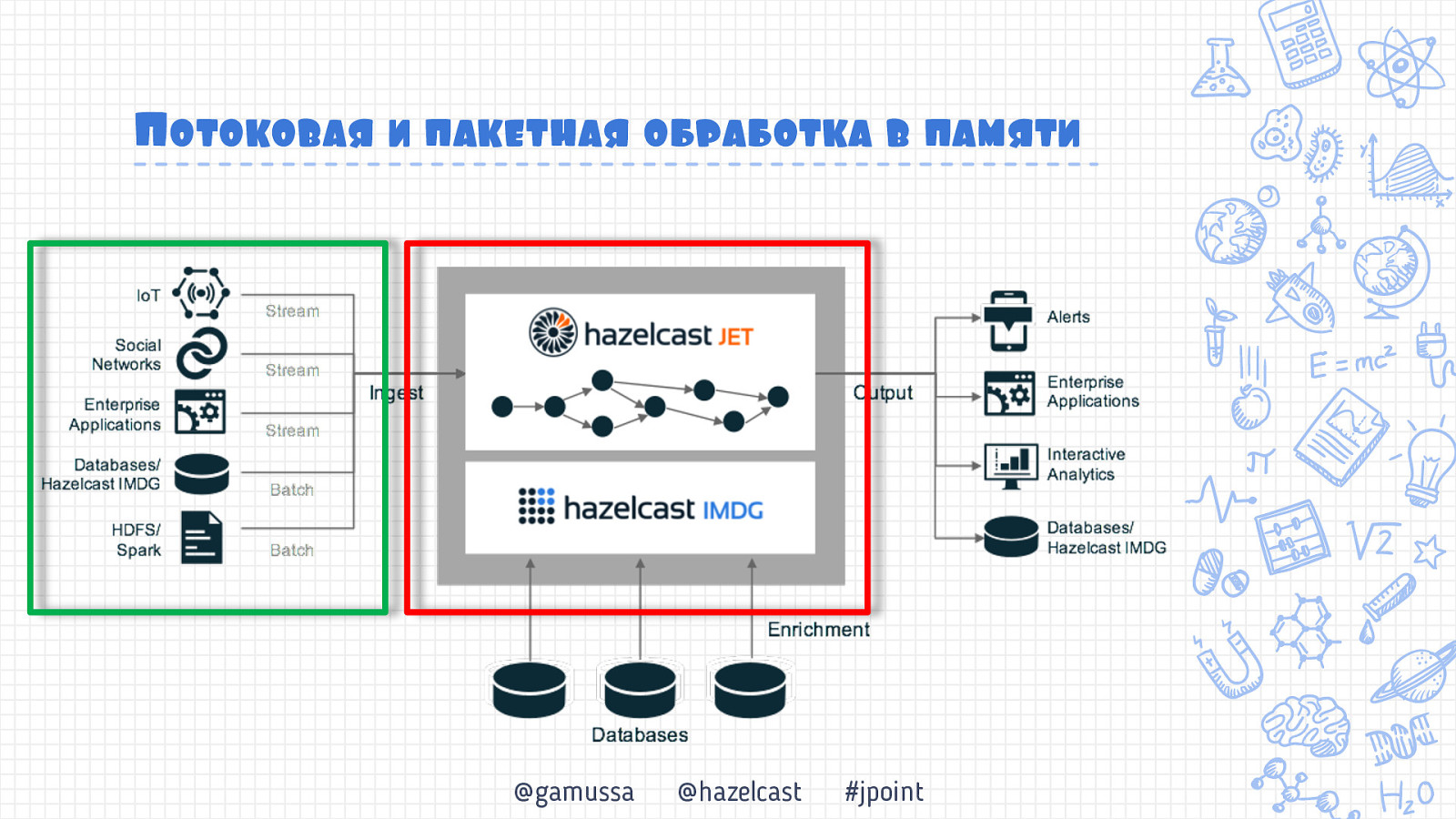
Потоковая и пакетная обработка в памяти @gamussa @hazelcast #jpoint
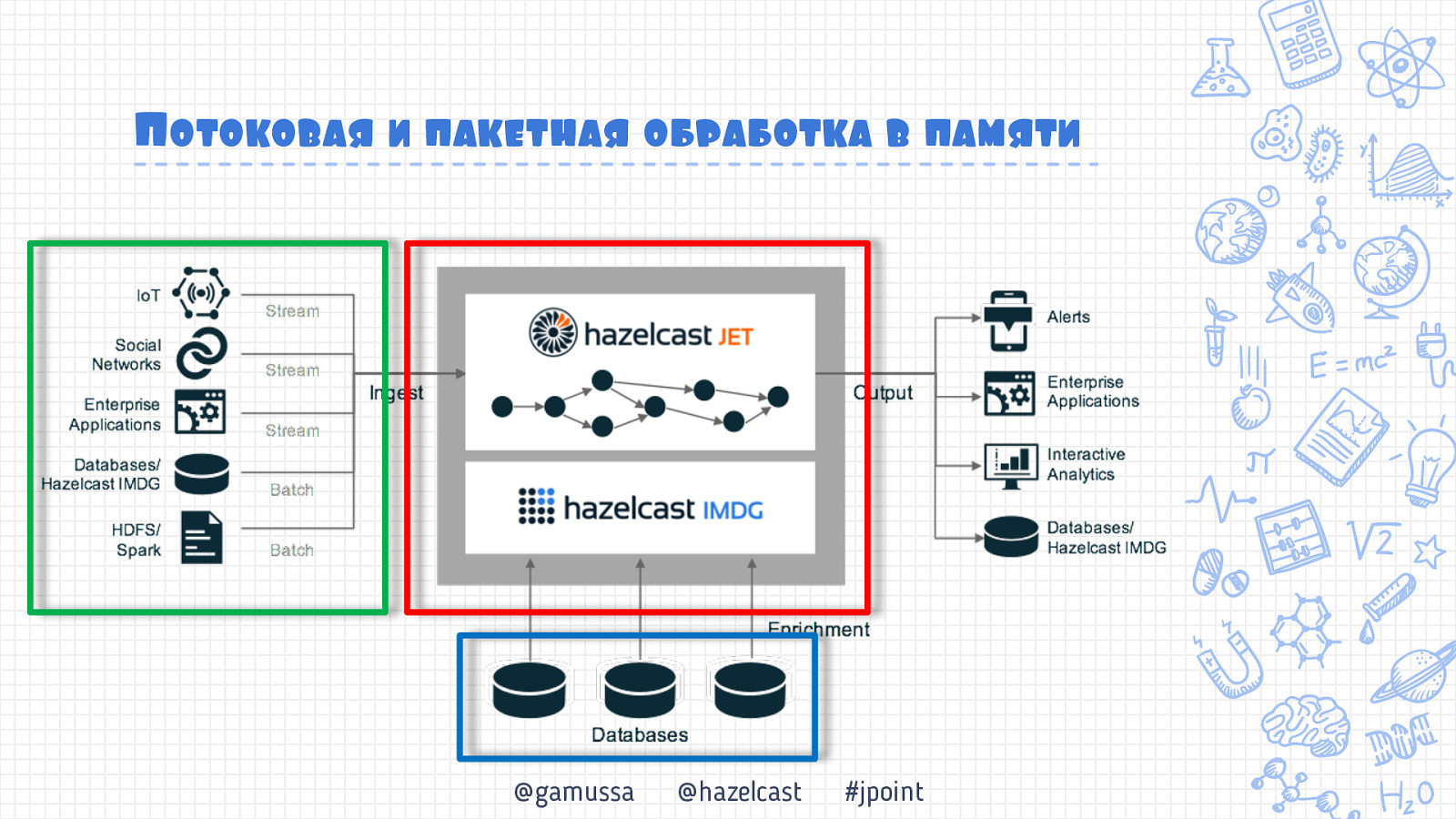
Потоковая и пакетная обработка в памяти @gamussa @hazelcast #jpoint
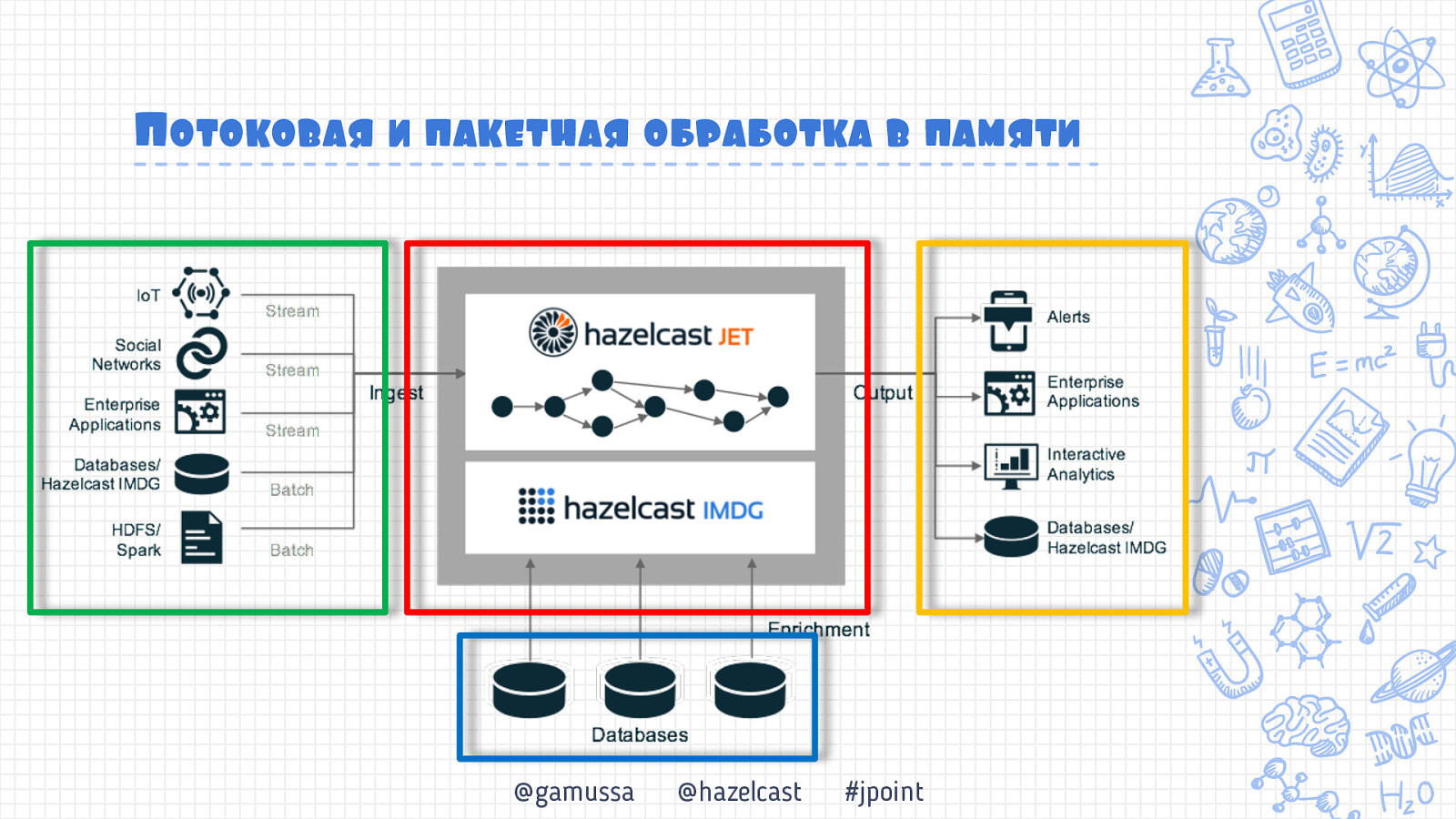
Потоковая и пакетная обработка в памяти @gamussa @hazelcast #jpoint

Jet против мира Big Data @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость data affinity @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость data affinity cooperative multitasking @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость data affinity cooperative multitasking Hazelcast IMDG @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость data affinity cooperative multitasking Hazelcast IMDG распределенные данные @gamussa @hazelcast #jpoint

Jet против мира Big Data Простота в разработке в развертывании (даже в облаках) Скорость data affinity cooperative multitasking Hazelcast IMDG распределенные данные discovery @gamussa @hazelcast #jpoint
Когда пьытаешься объяснить современньый мир Big Data @gamussa @hazelcast #jpoint

Локальность и привязка данньых @gamussa @hazelcast #jpoint

Локальность и привязка данньых Скорость и низкие задержки @gamussa @hazelcast #jpoint

Локальность и привязка данньых Скорость и низкие задержки данные и вычисления расположены на одной ноде @gamussa @hazelcast #jpoint

Локальность и привязка данньых Скорость и низкие задержки данные и вычисления расположены на одной ноде Привязка к структуре партиций @gamussa @hazelcast #jpoint
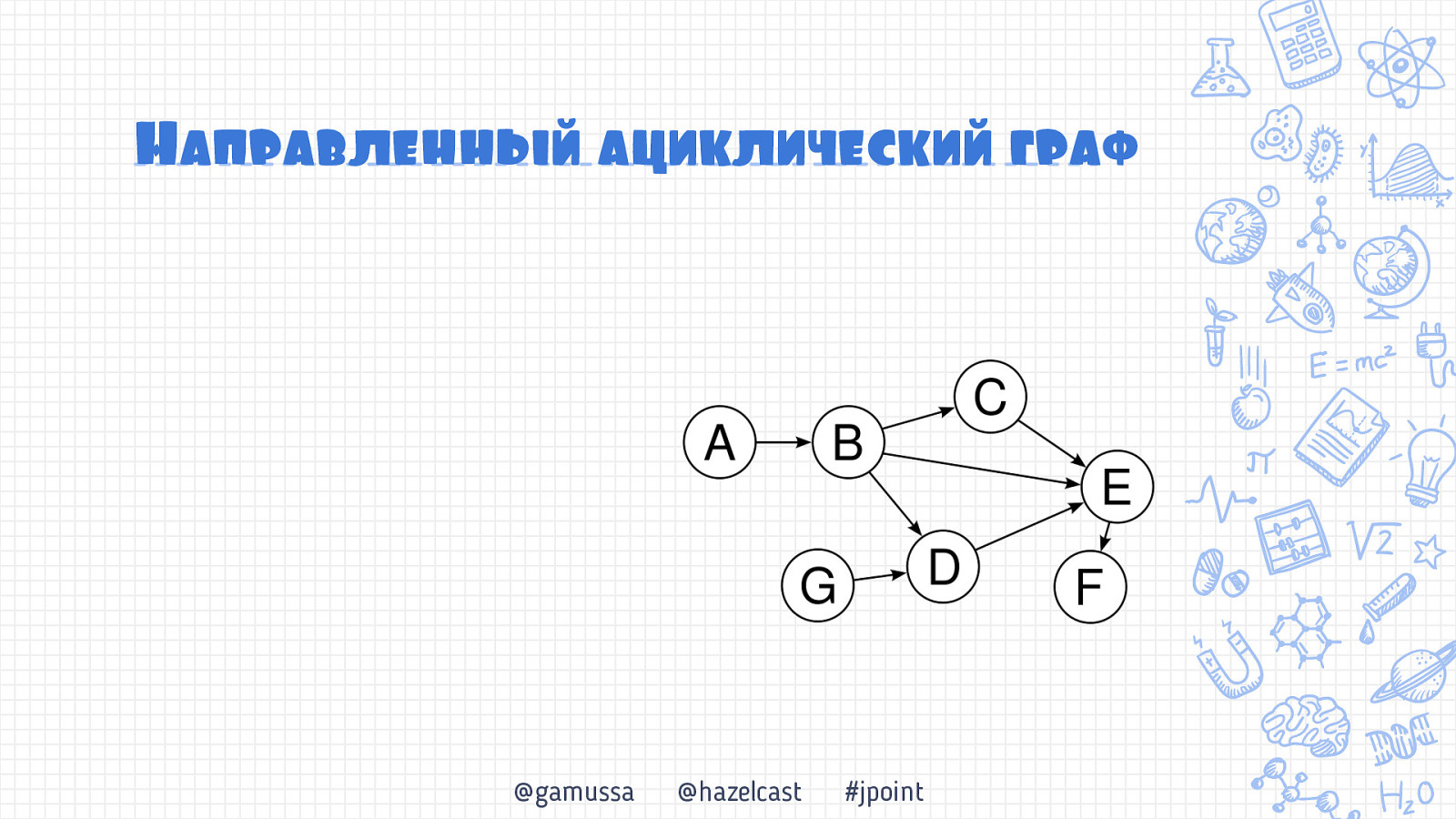
Направленньый ациклический граф @gamussa @hazelcast #jpoint
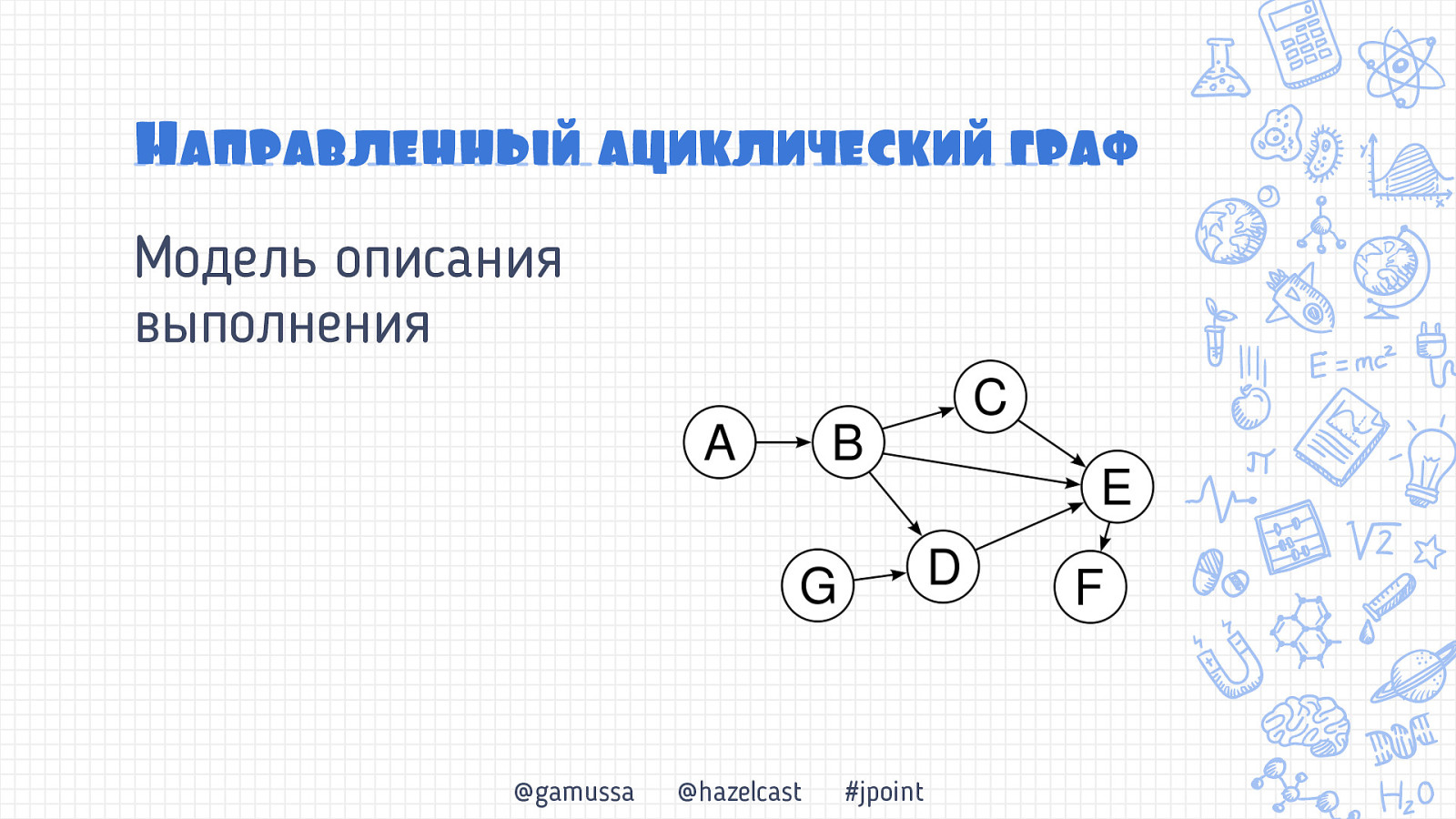
Направленньый ациклический граф Модель описания выполнения @gamussa @hazelcast #jpoint
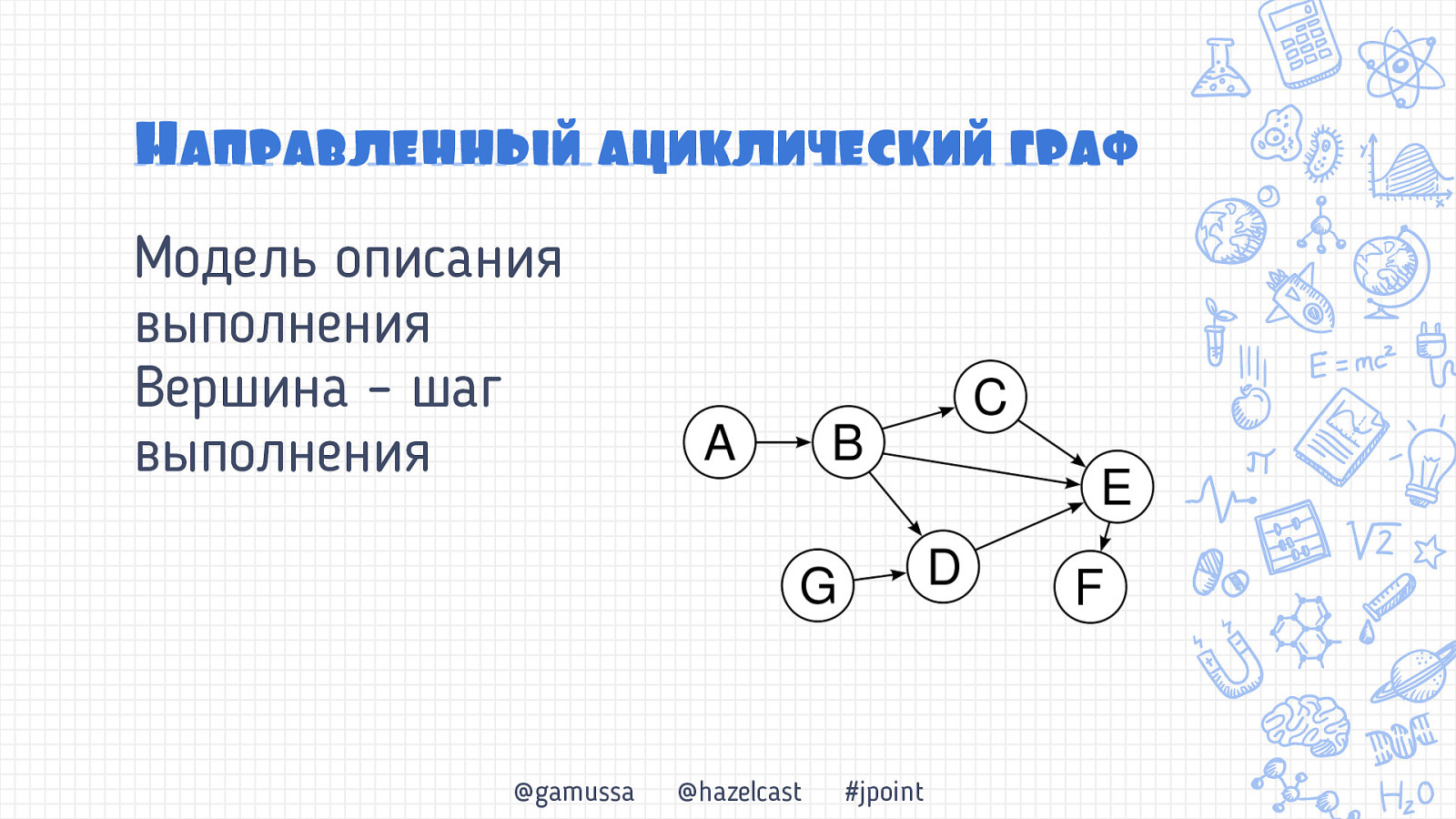
Направленньый ациклический граф Модель описания выполнения Вершина – шаг выполнения @gamussa @hazelcast #jpoint
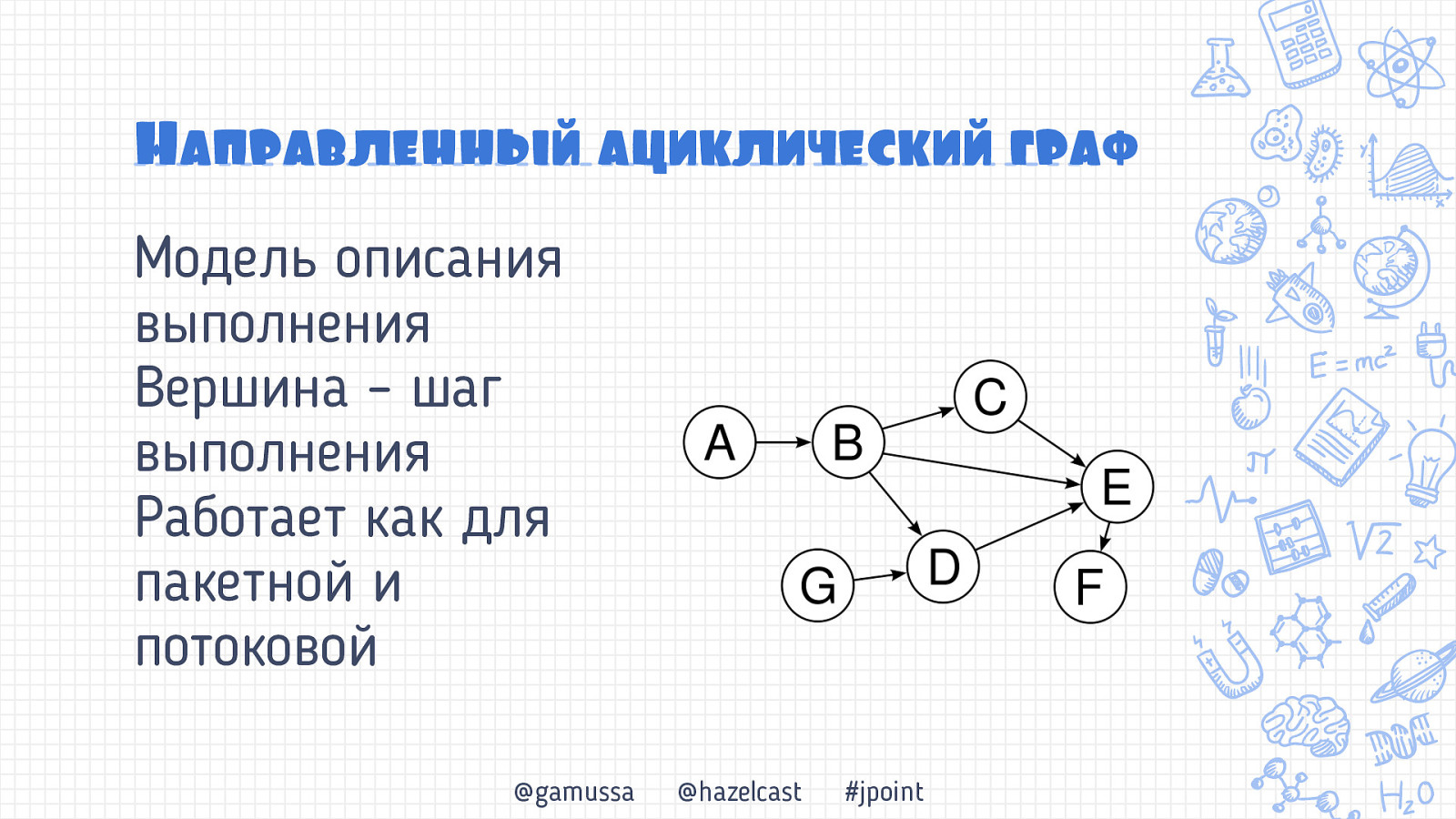
Направленньый ациклический граф Модель описания выполнения Вершина – шаг выполнения Работает как для пакетной и потоковой @gamussa @hazelcast #jpoint

Исполнение графа @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком Каждая вершина графа исполняется набором tasklet-ов @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком Каждая вершина графа исполняется набором tasklet-ов Ограниченное число «настоящих» потоков @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком Каждая вершина графа исполняется набором tasklet-ов Ограниченное число «настоящих» потоков ~ кол-во процессоров @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком Каждая вершина графа исполняется набором tasklet-ов Ограниченное число «настоящих» потоков ~ кол-во процессоров Work-stealing между потоками @gamussa @hazelcast #jpoint

Исполнение графа Каждая нода кластера исполняет граф целиком Каждая вершина графа исполняется набором tasklet-ов Ограниченное число «настоящих» потоков ~ кол-во процессоров Work-stealing между потоками Back pressure между вершинами @gamussa @hazelcast #jpoint

Cooperative Multithreading @gamussa @hazelcast #jpoint

Cooperative Multithreading Cooperative Processors выполняются в цикле, который выполняется в native треде @gamussa @hazelcast #jpoint

Cooperative Multithreading Cooperative Processors выполняются в цикле, который выполняется в native треде нет переключения контекста привязка к ядру процессора @gamussa @hazelcast #jpoint

Cooperative Multithreading Cooperative Processors выполняются в цикле, который выполняется в native треде нет переключения контекста привязка к ядру процессора Каждый tasklet выполняет небольшой небольшую часть работы (<1ms) @gamussa @hazelcast #jpoint

Cooperative Multithreading Cooperative Processors выполняются в цикле, который выполняется в native треде нет переключения контекста привязка к ядру процессора Каждый tasklet выполняет небольшой небольшую часть работы (<1ms) @gamussa @hazelcast #jpoint

Cooperative Multithreading @gamussa @hazelcast #jpoint

Cooperative Multithreading 1 поток может выполнять ~1000 tasklet @gamussa @hazelcast #jpoint

Cooperative Multithreading 1 поток может выполнять ~1000 tasklet Если нечего делать, тред @gamussa @hazelcast #jpoint

Cooperative Multithreading 1 поток может выполнять ~1000 tasklet Если нечего делать, тред Ребра графа имплементированы с помощью RingBuffer – single producer / single consumer @gamussa @hazelcast #jpoint

Cooperative Multithreading 1 поток может выполнять ~1000 tasklet Если нечего делать, тред Ребра графа имплементированы с помощью RingBuffer – single producer / single consumer @gamussa @hazelcast #jpoint

ТОпологии Что нам стоит кластер построить @gamussa @hazelcast #jpoint

Топологии @gamussa @hazelcast #jpoint
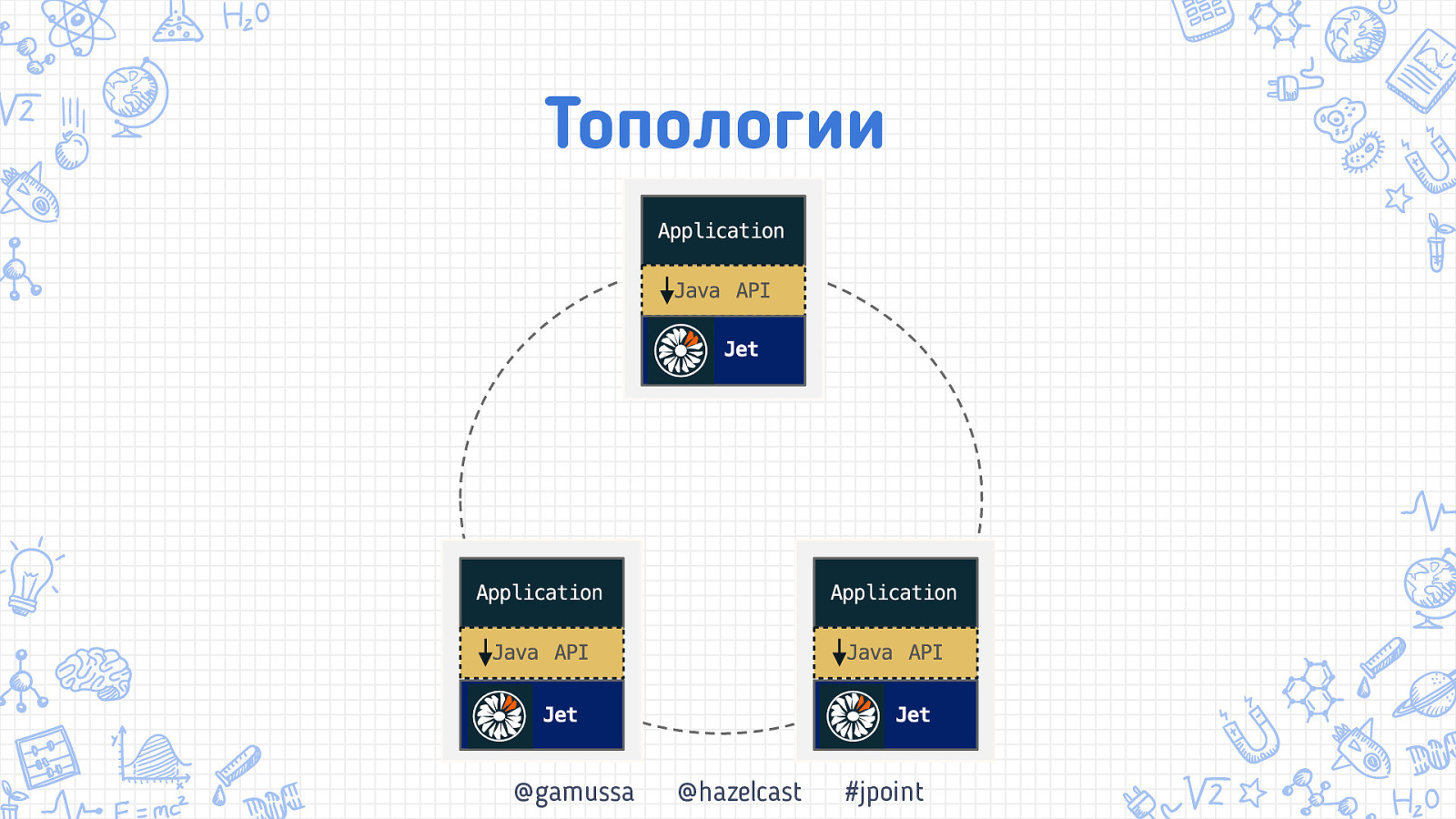
Топологии @gamussa @hazelcast #jpoint
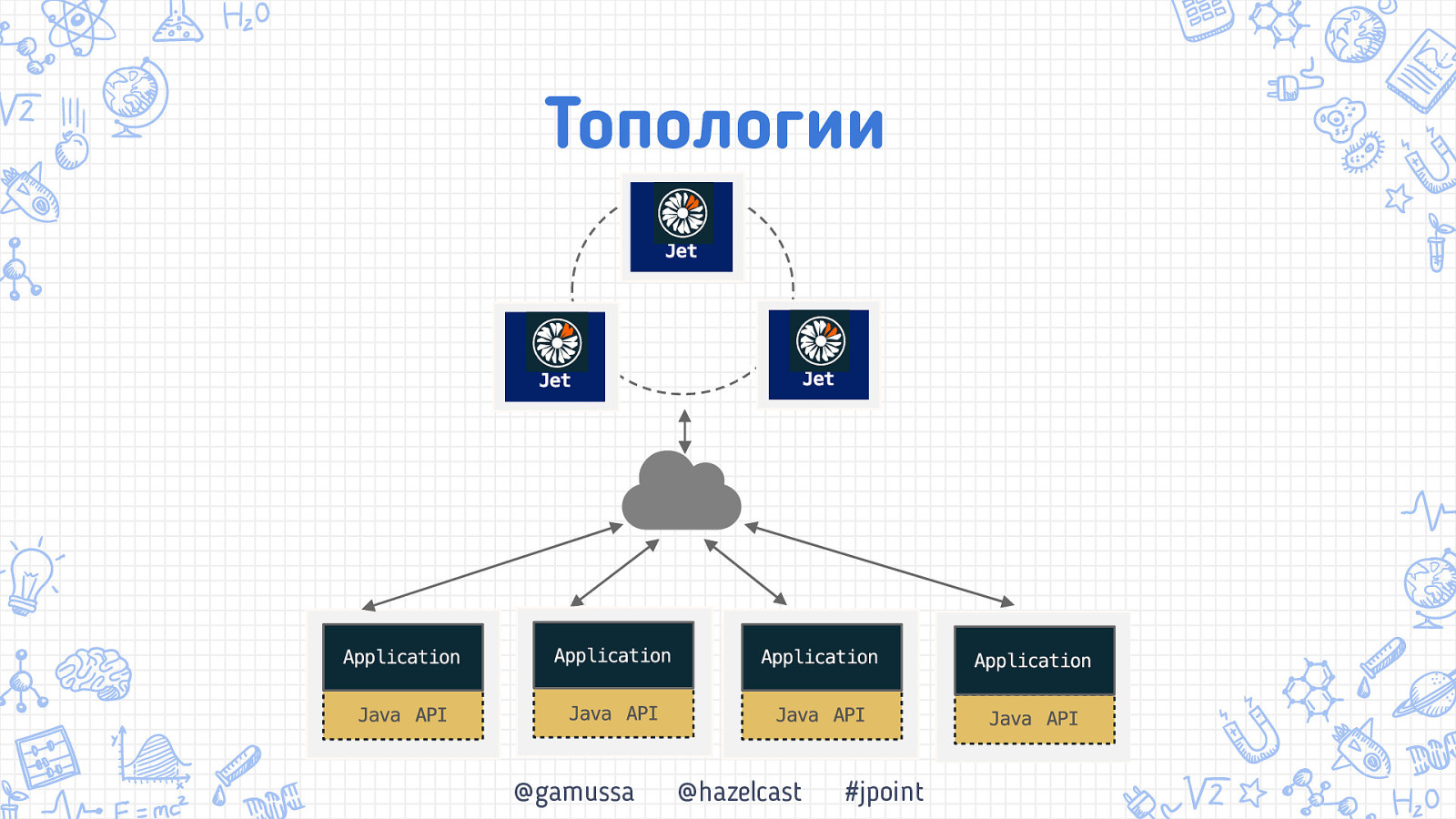
Топологии @gamussa @hazelcast #jpoint
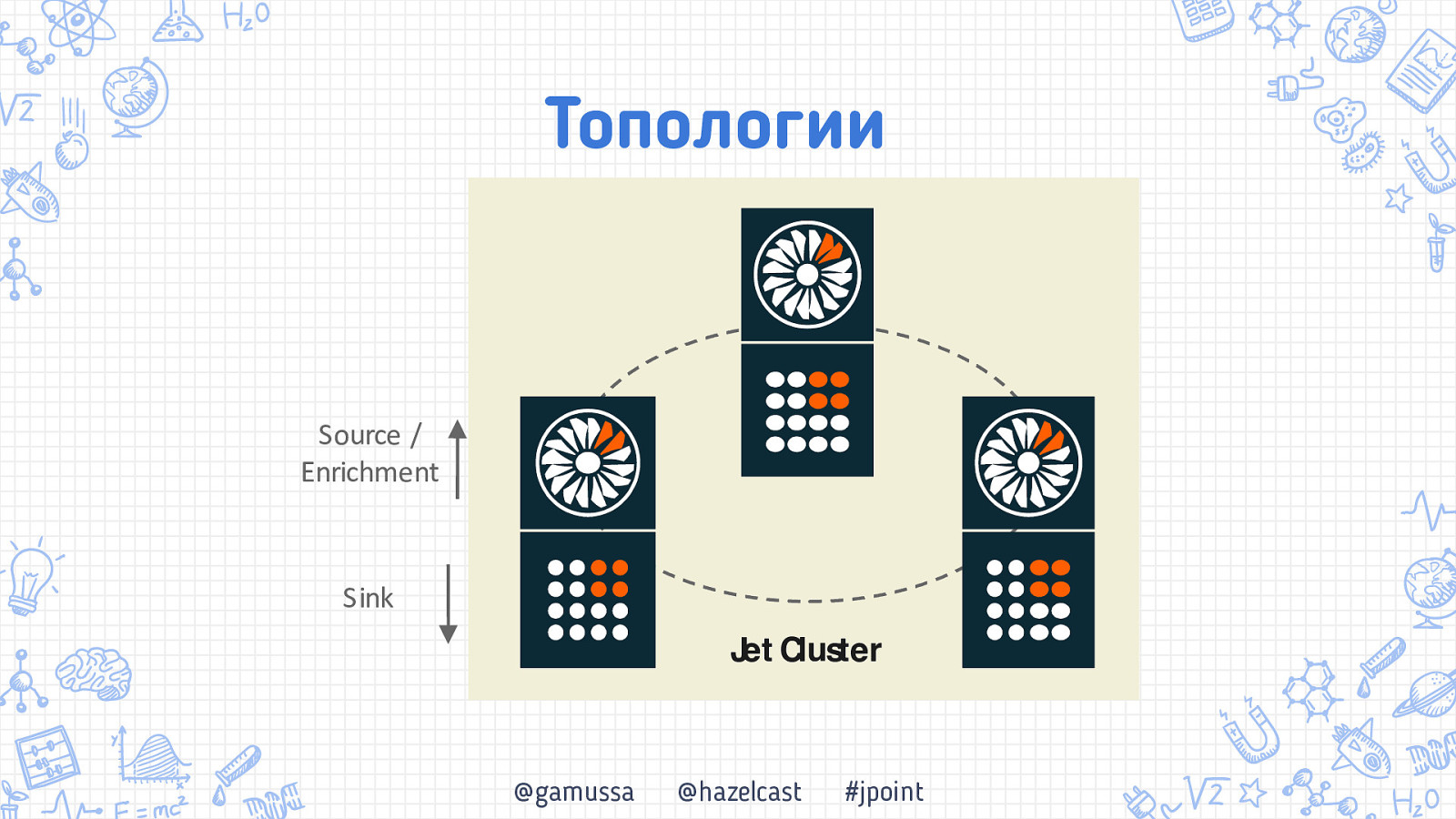
Топологии Source / Enrichment Sink Jet!Cluster @gamussa @hazelcast #jpoint
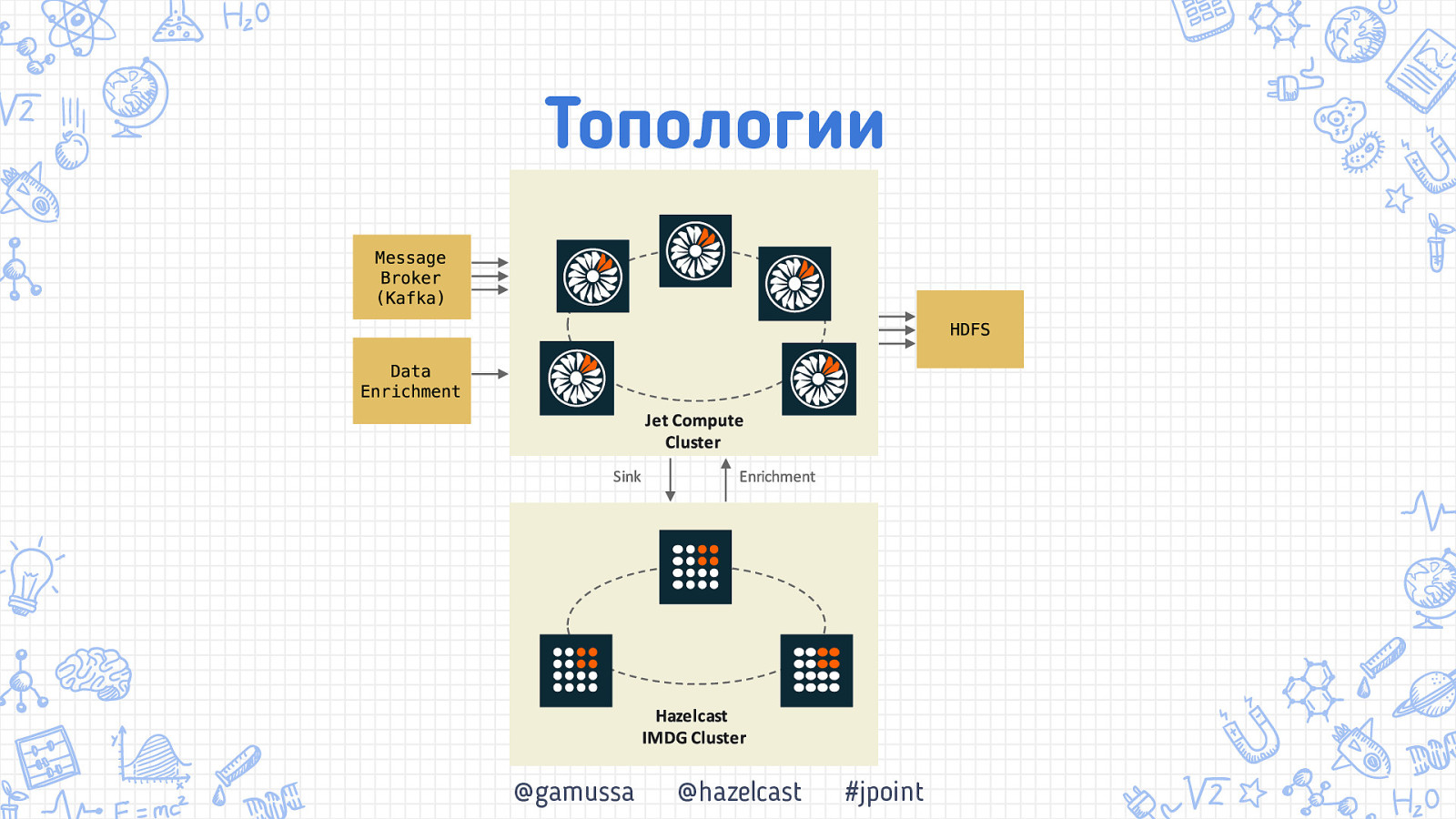
Топологии @gamussa @hazelcast #jpoint

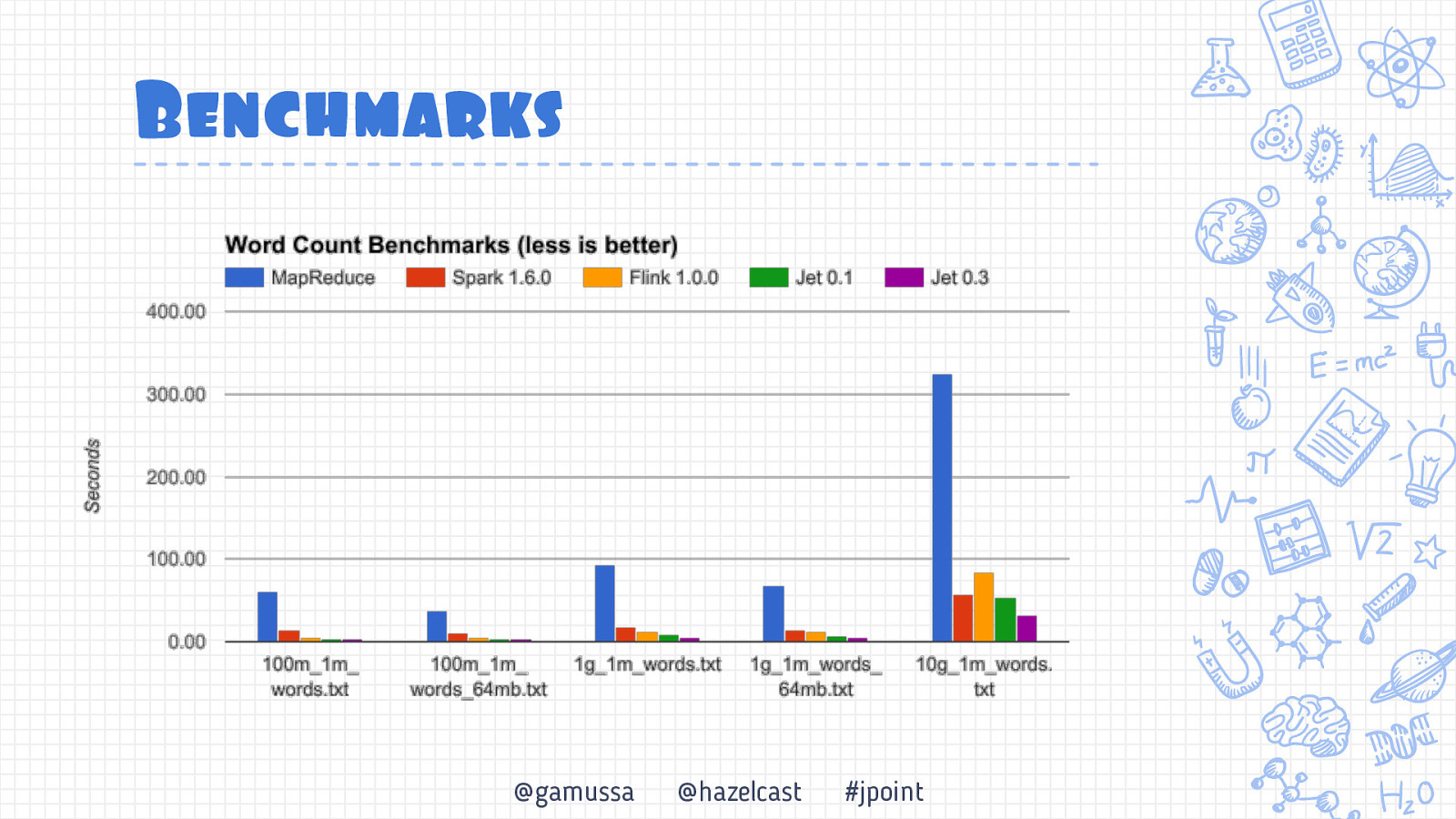
Benchmarks @gamussa @hazelcast #jpoint
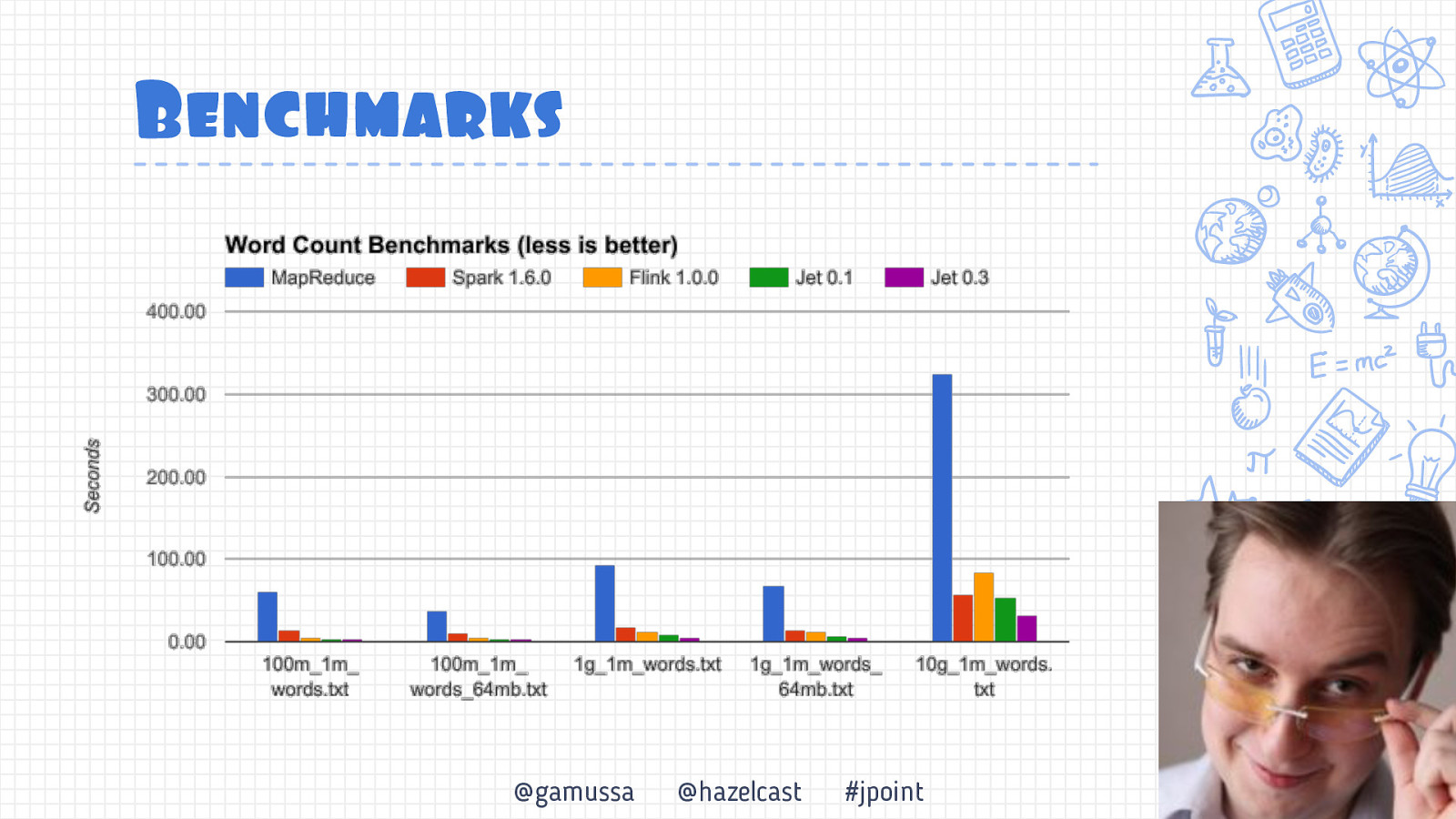
Benchmarks @gamussa @hazelcast #jpoint

Демо @gamussa @hazelcast #jpoint

Disclaimer: Ham пишут
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Ham пишут ? Про фэйлы нод в хазелкасие хотелось бы услышать откровений и примеры из жизни.
- авторская орфография сохранена @gamussa @hazelcast #jpoint

Disclaimer: Ham пишут ? Про фэйлы нод в хазелкасие хотелось бы услышать откровений и примеры из жизни.
- авторская орфография сохранена @gamussa @hazelcast #jpoint

проблемы Текущее состояние @gamussa @hazelcast #jpoint

Проблемьы @gamussa @hazelcast #jpoint

Проблемьы Устойчивость к сбоям @gamussa @hazelcast #jpoint

Проблемьы Устойчивость к сбоям Работа с «бесконечными» данными @gamussa @hazelcast #jpoint

Проблемьы Устойчивость к сбоям Работа с «бесконечными» данными Неупорядоченные и «опоздавшие» события @gamussa @hazelcast #jpoint

I FOUND YOUR LACK OF FAULT TOLERANCE disturbing

Бэкапьы Консистентный бэкап системы Обработка «At-least once» vs «Exactly once» Снэпшот распределенной системы +1 10 @gamussa @hazelcast #jpoint

Бэкапьы Консистентный бэкап системы Обработка «At-least once» vs «Exactly once» Снэпшот распределенной системы 10 @gamussa @hazelcast #jpoint

Бэкапьы Консистентный бэкап системы Обработка «At-least once» vs «Exactly once» Снэпшот распределенной системы 10 11 @gamussa @hazelcast #jpoint

Бэкапьы Консистентный бэкап системы Обработка «At-least once» vs «Exactly once» Снэпшот распределенной системы 11 10 11 @gamussa @hazelcast #jpoint
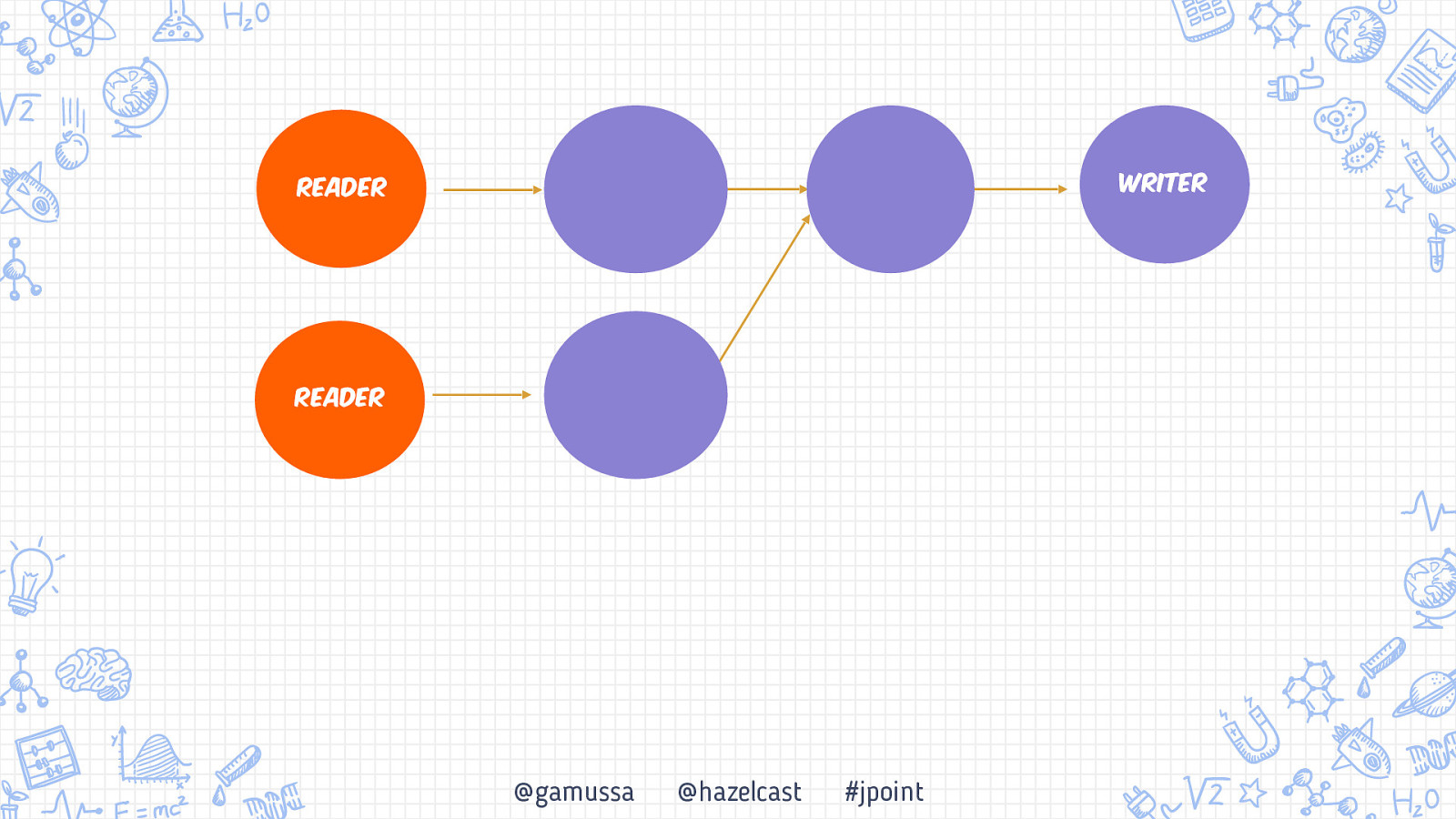
Writer Reader Reader @gamussa @hazelcast #jpoint
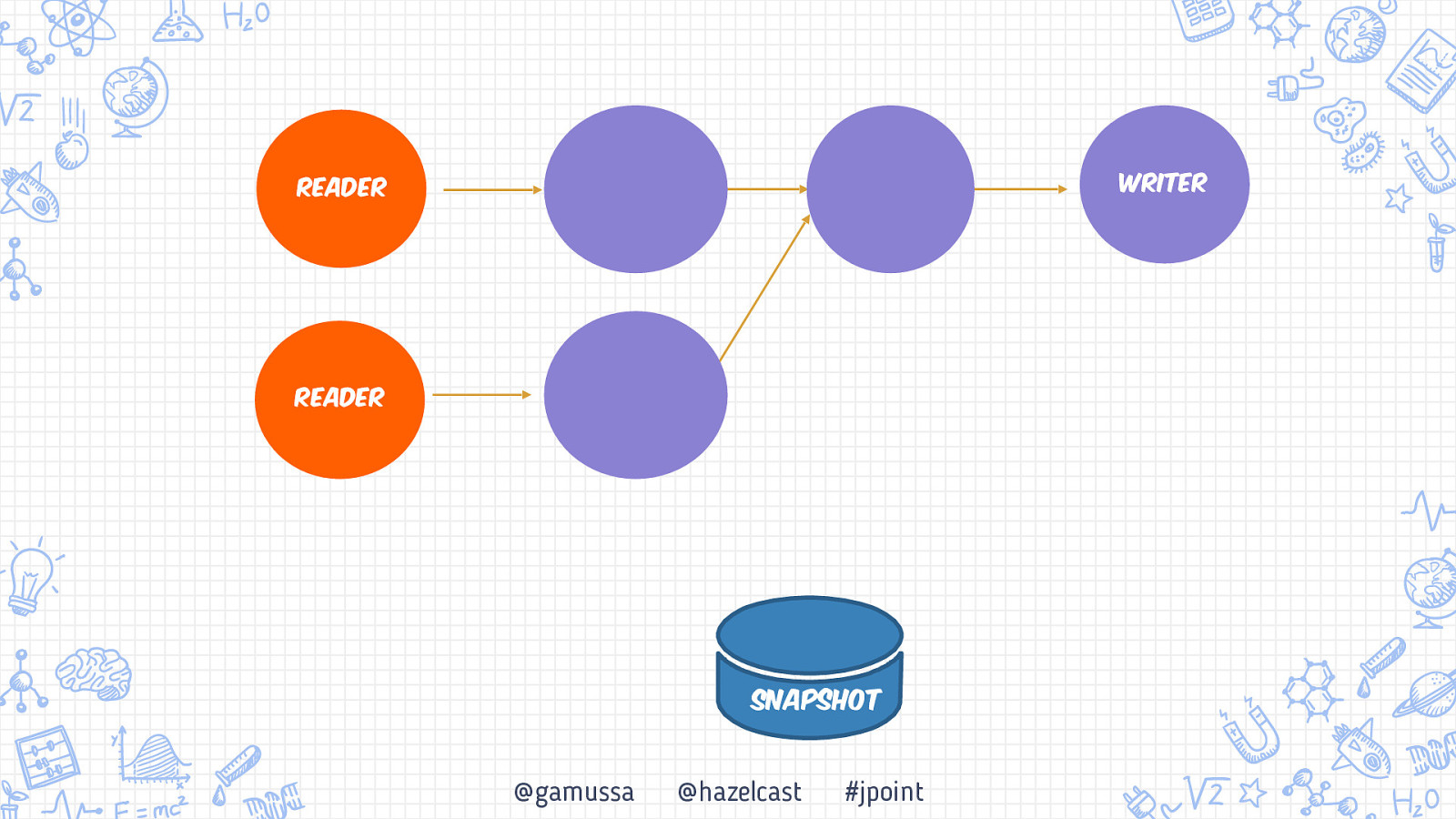
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
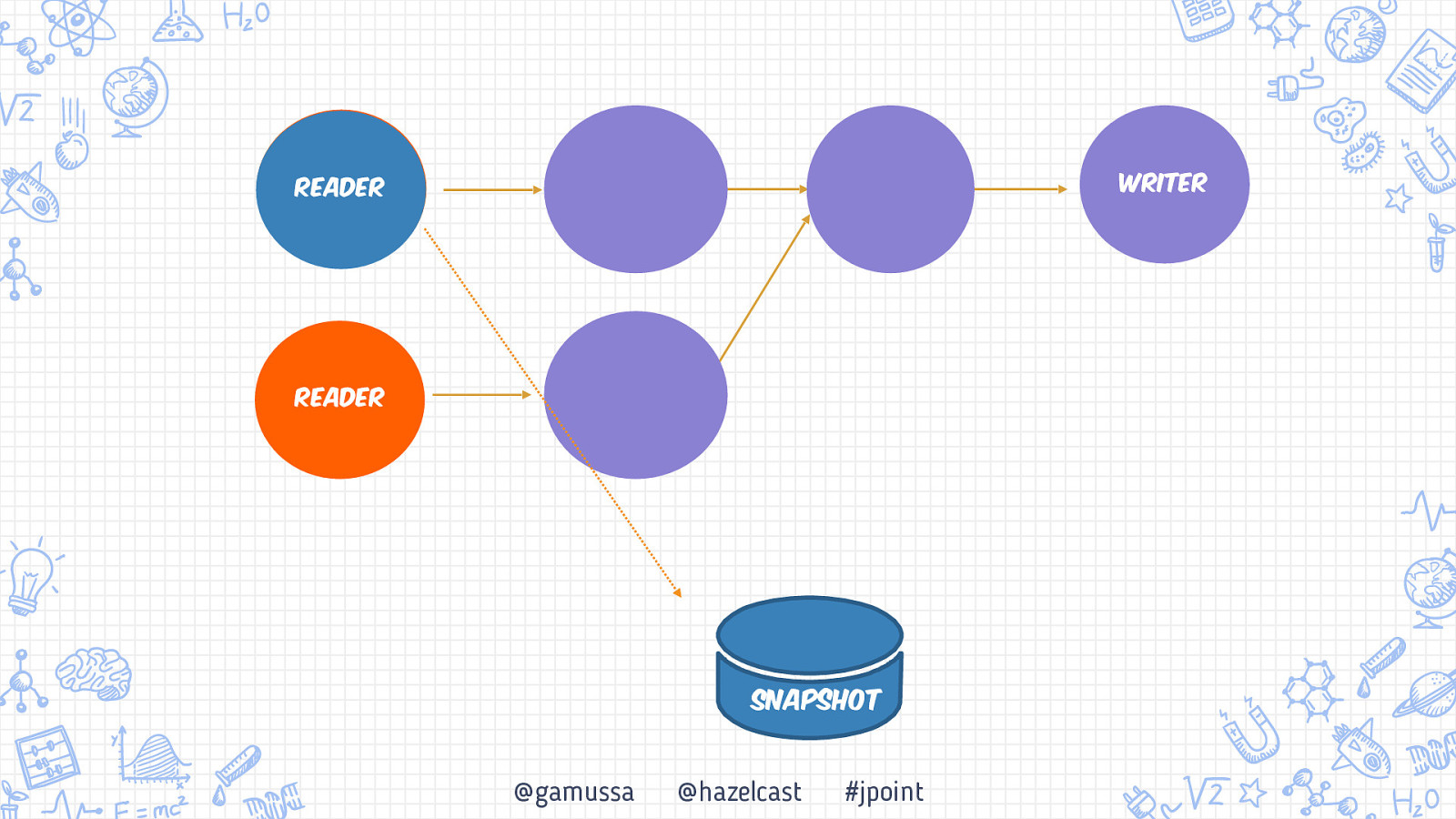
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
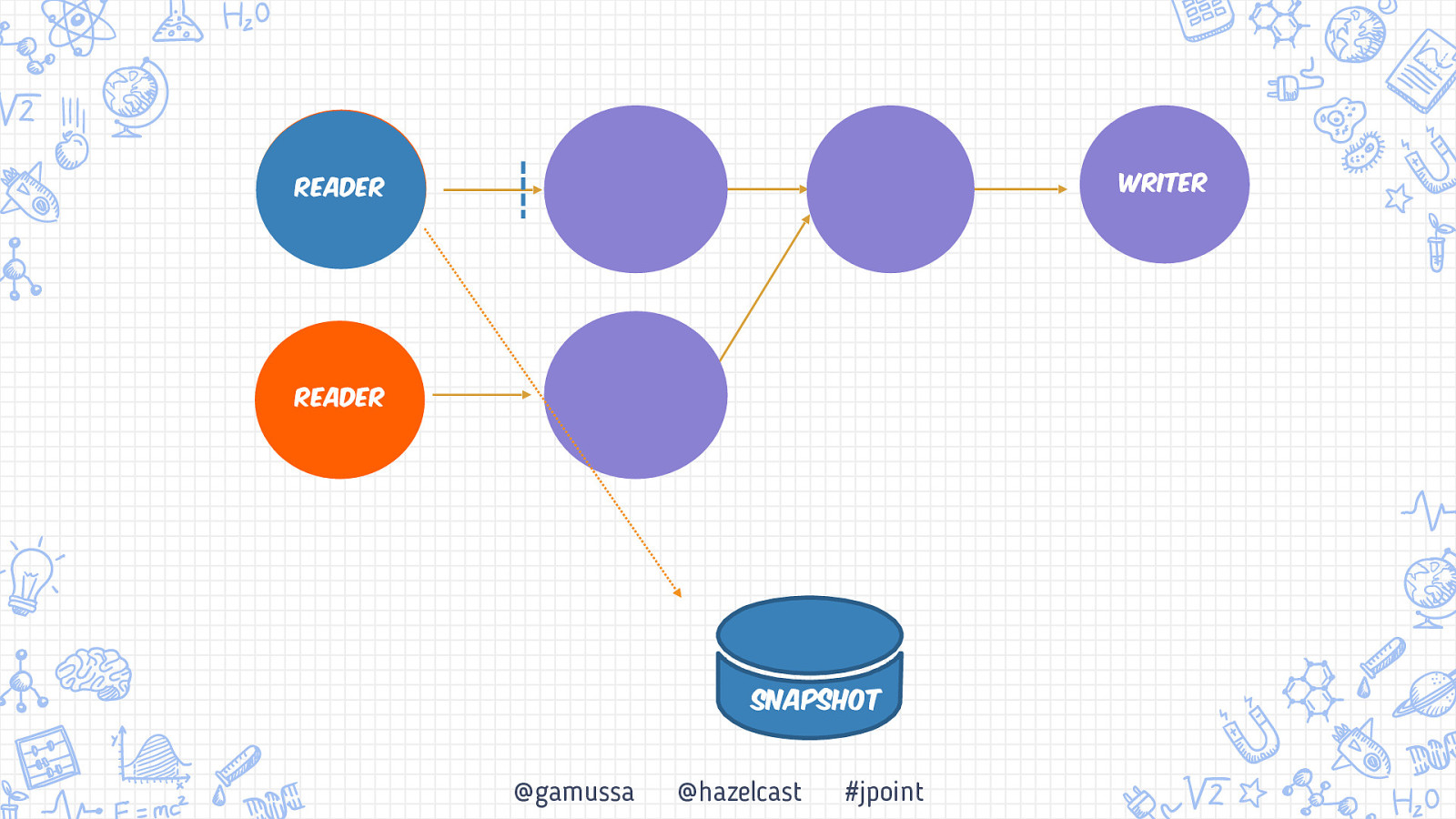
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
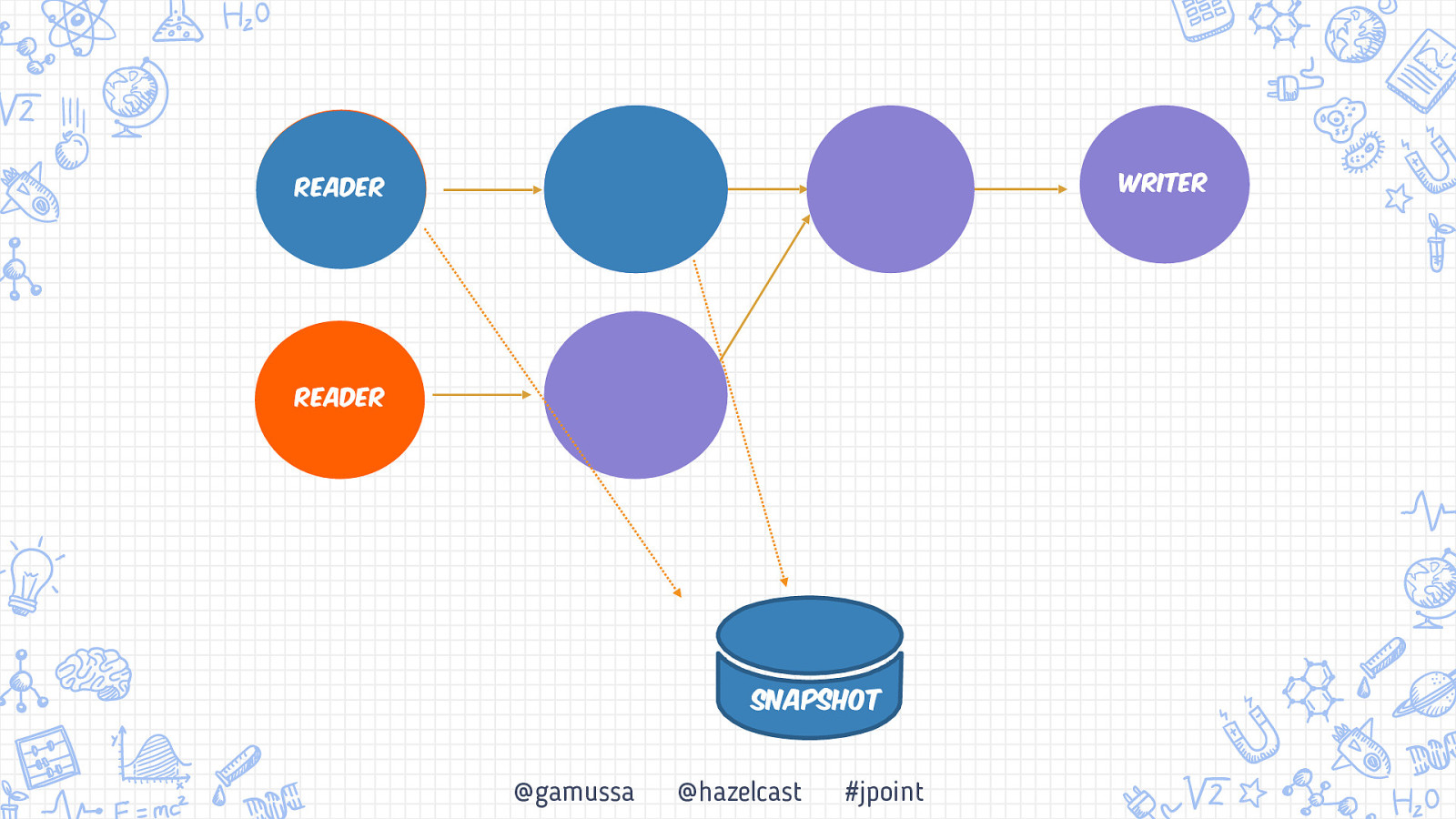
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
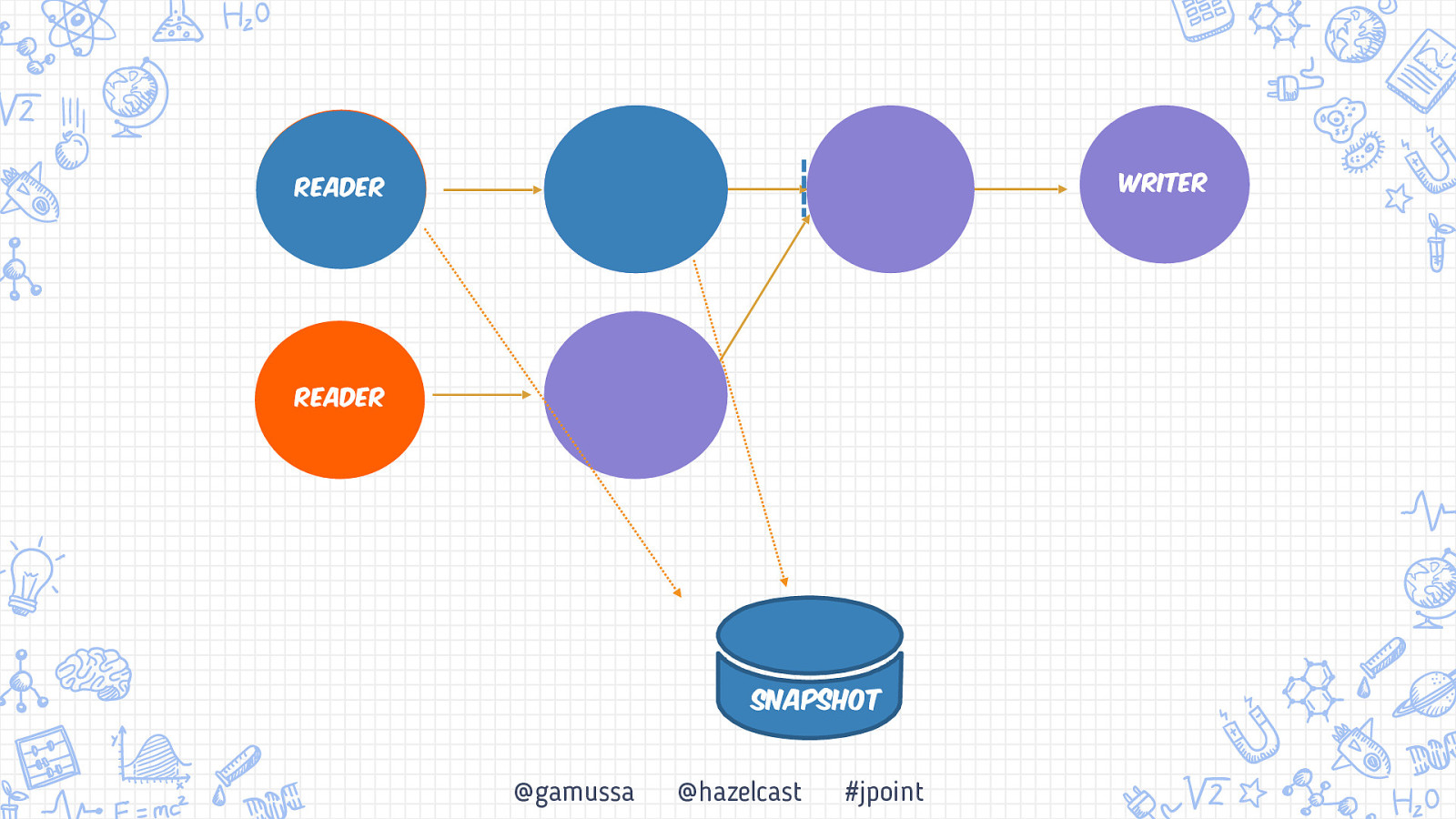
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
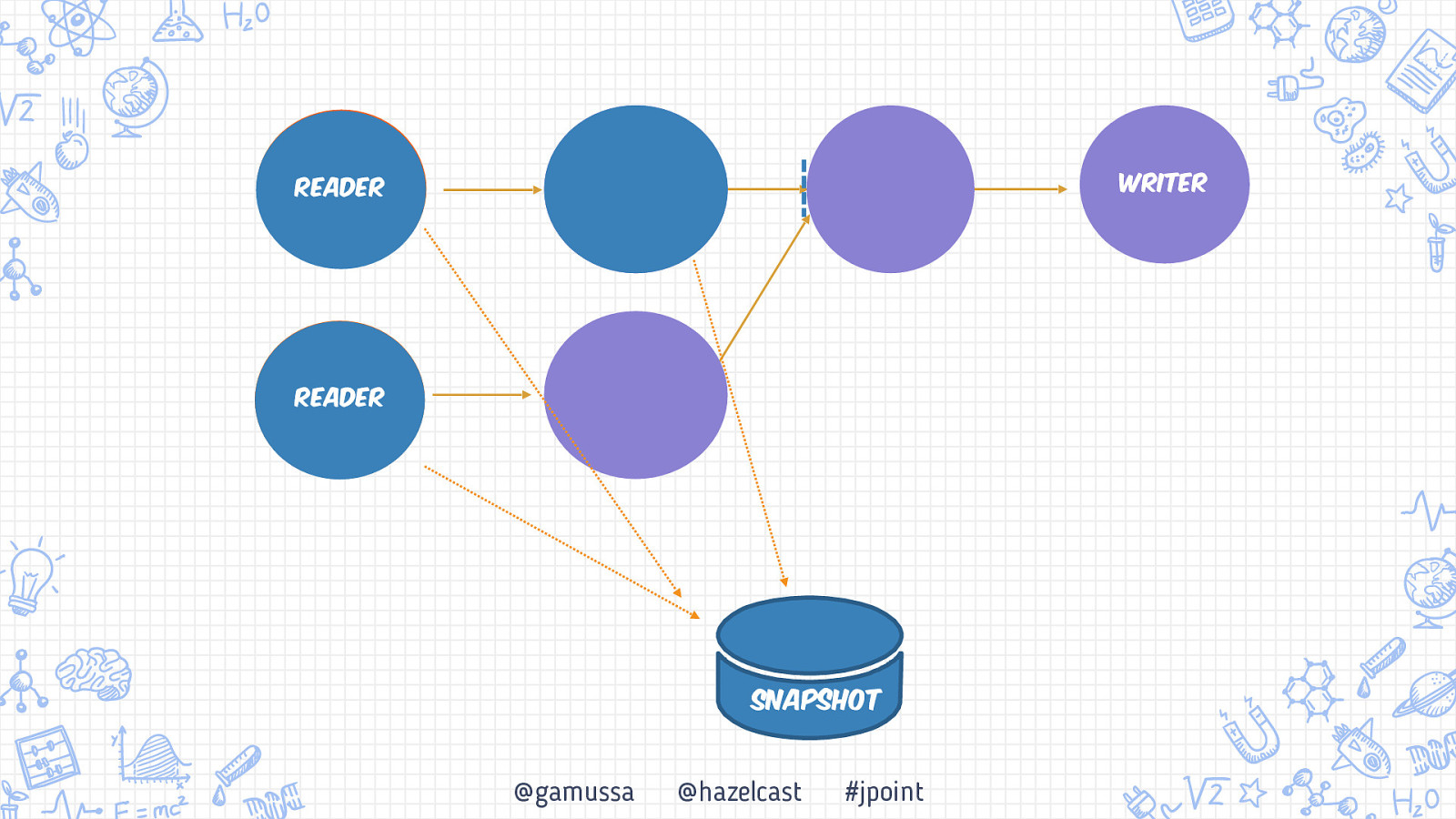
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
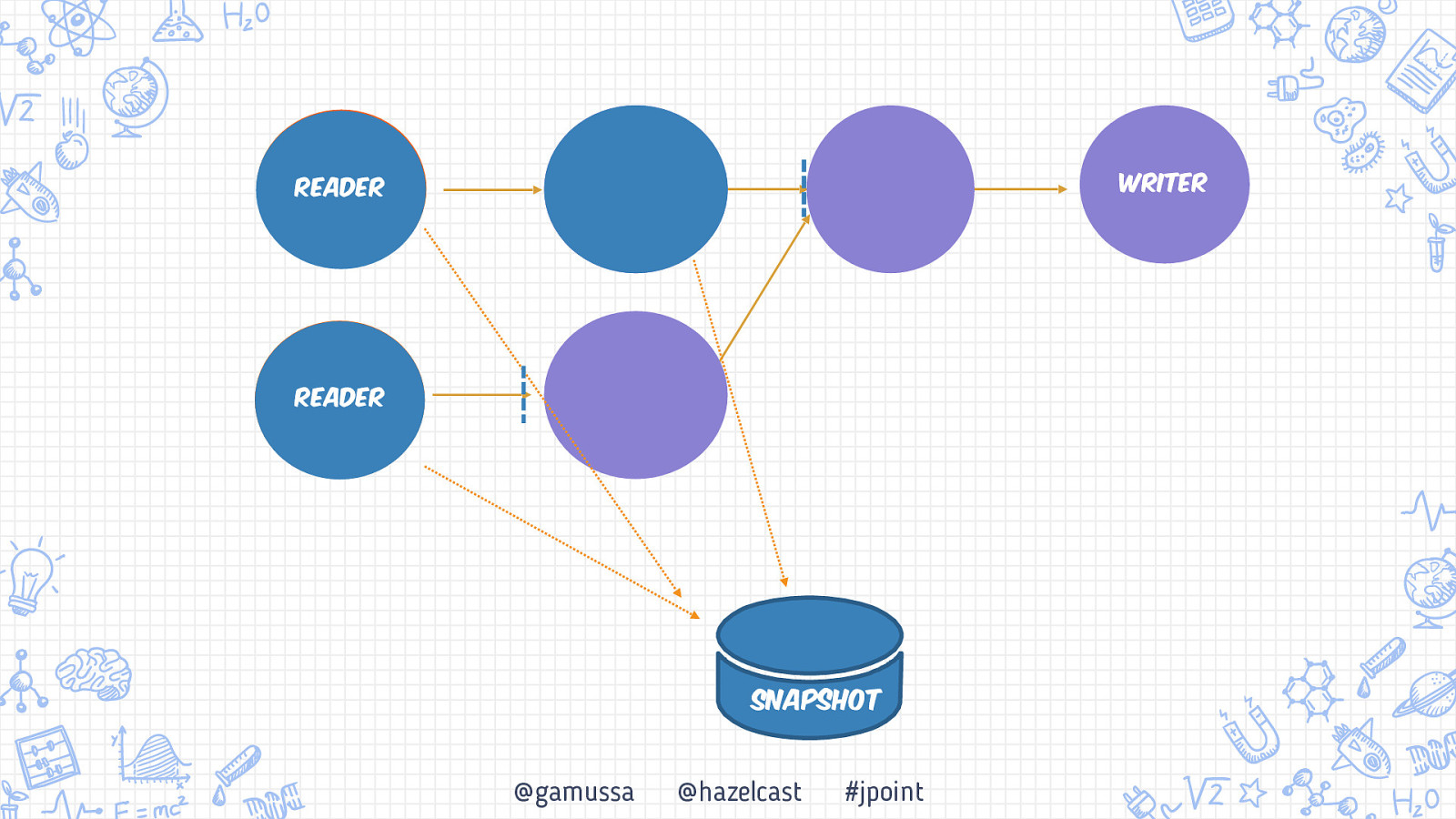
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
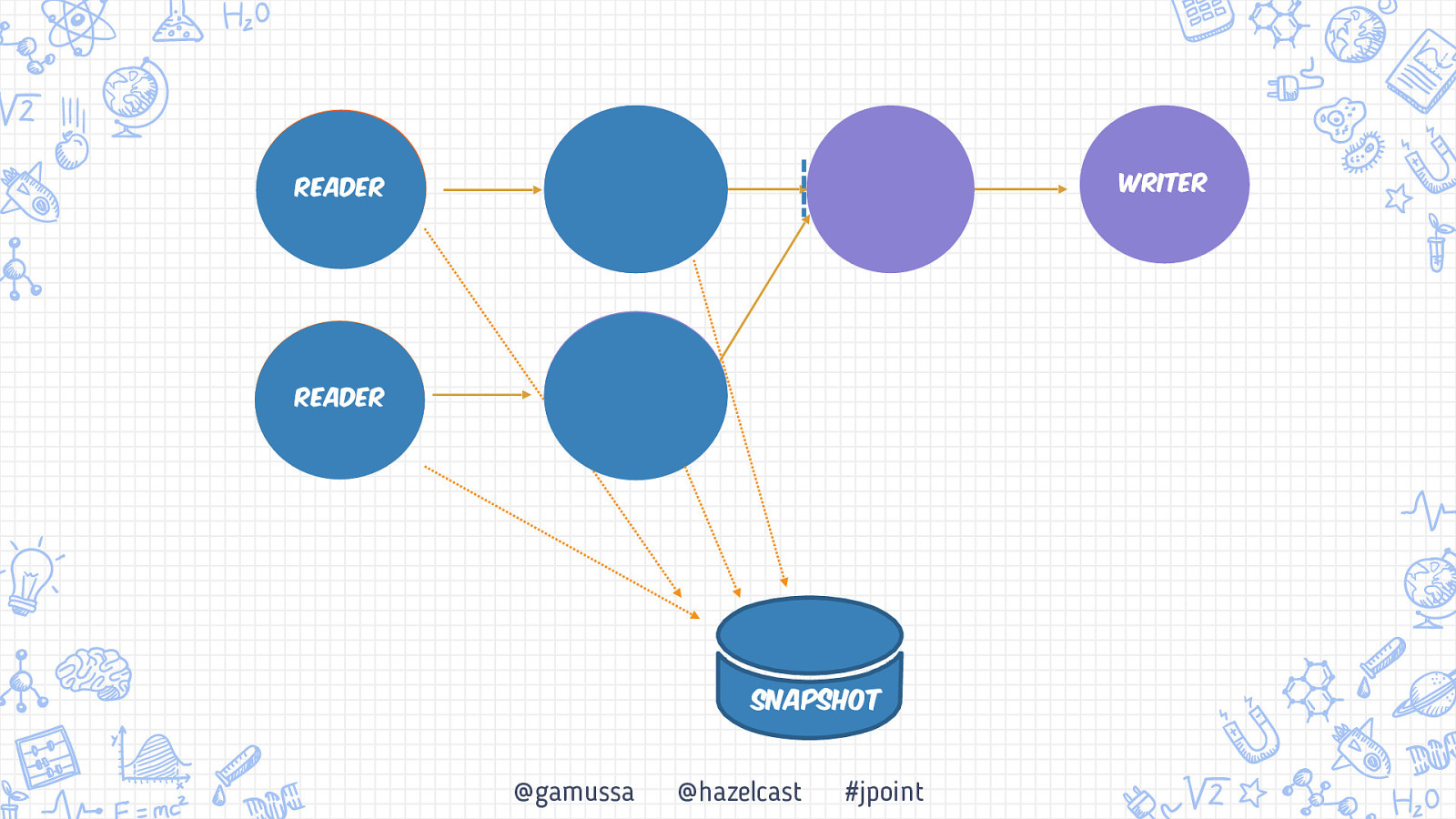
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
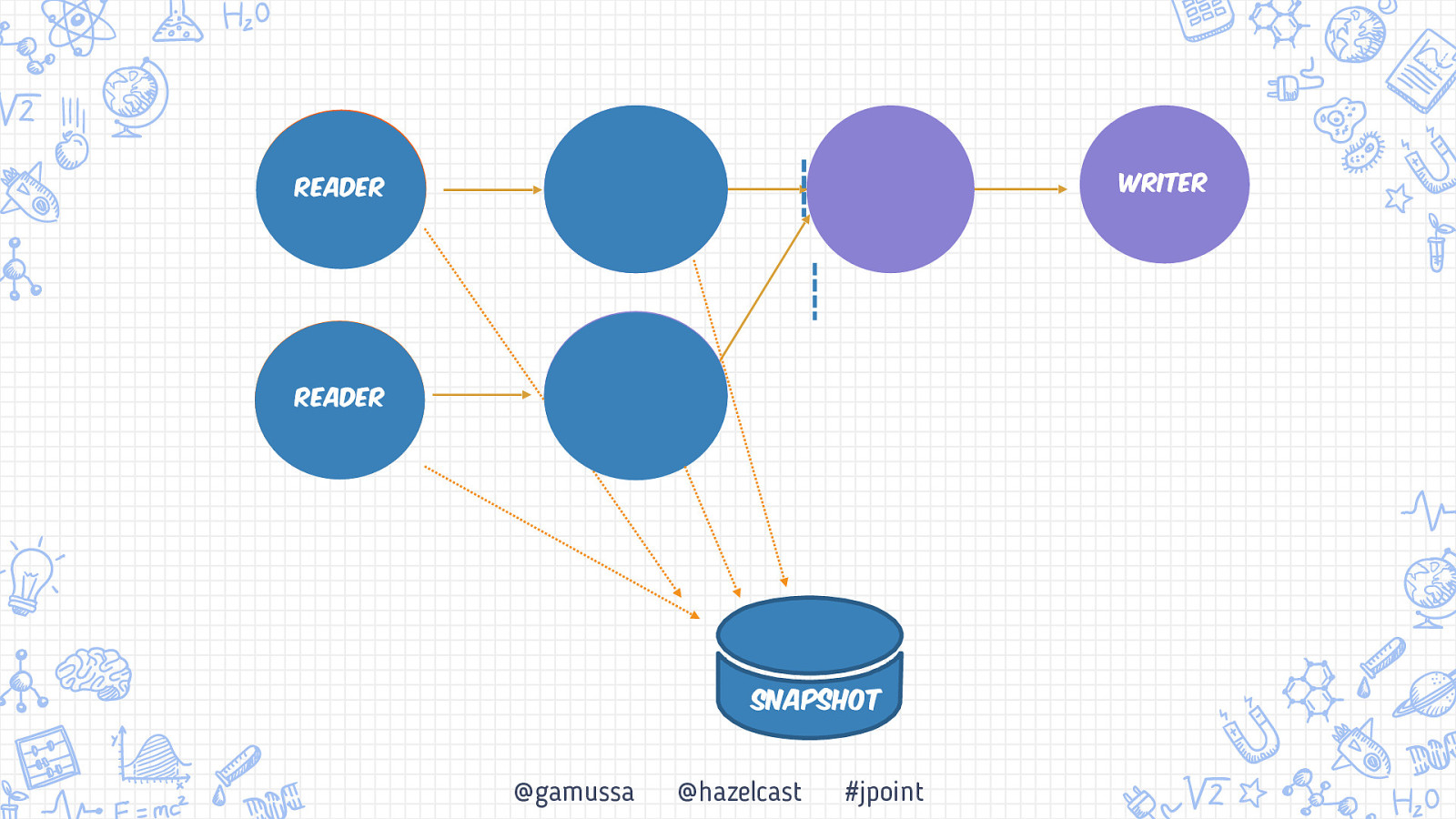
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
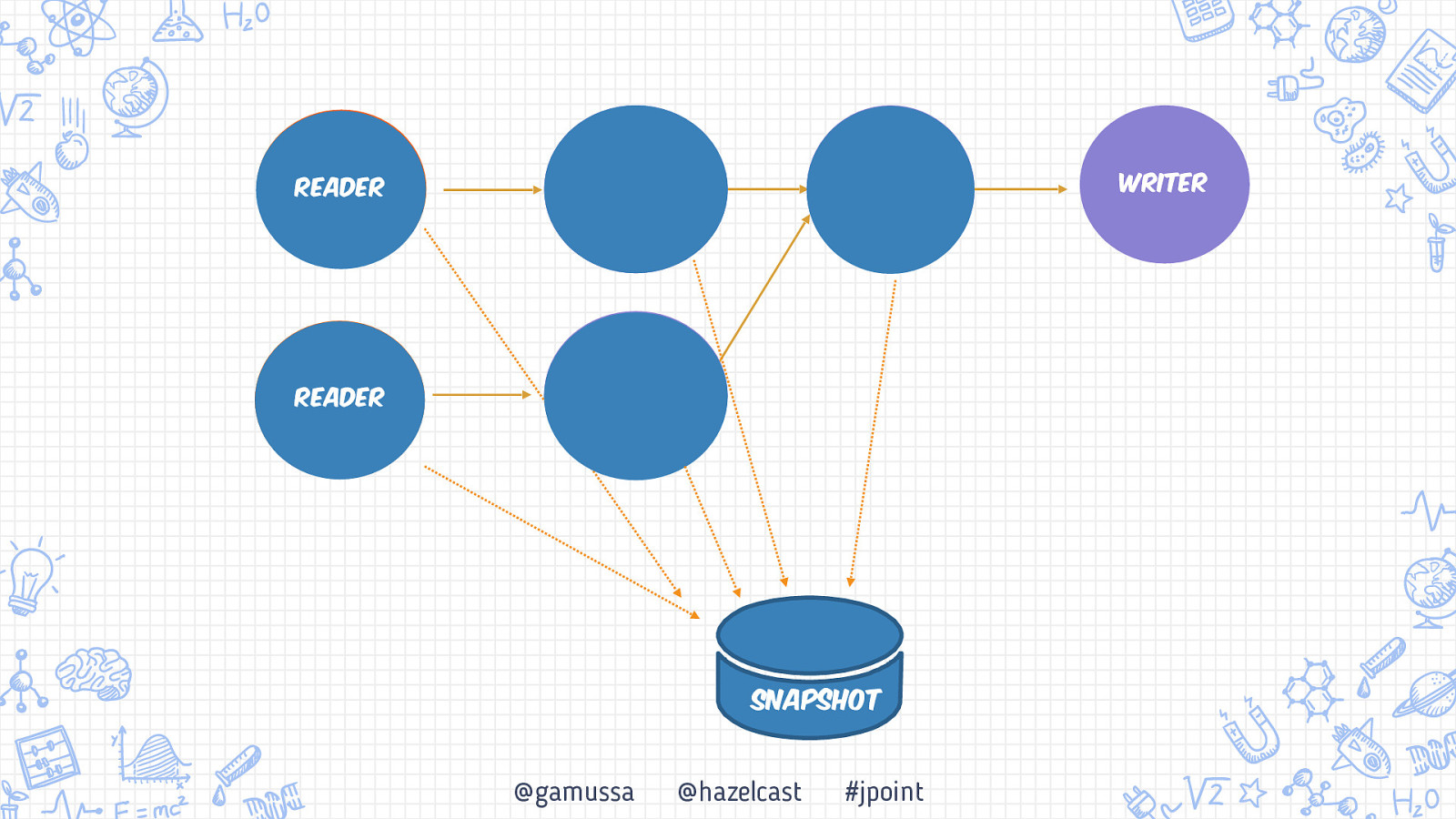
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
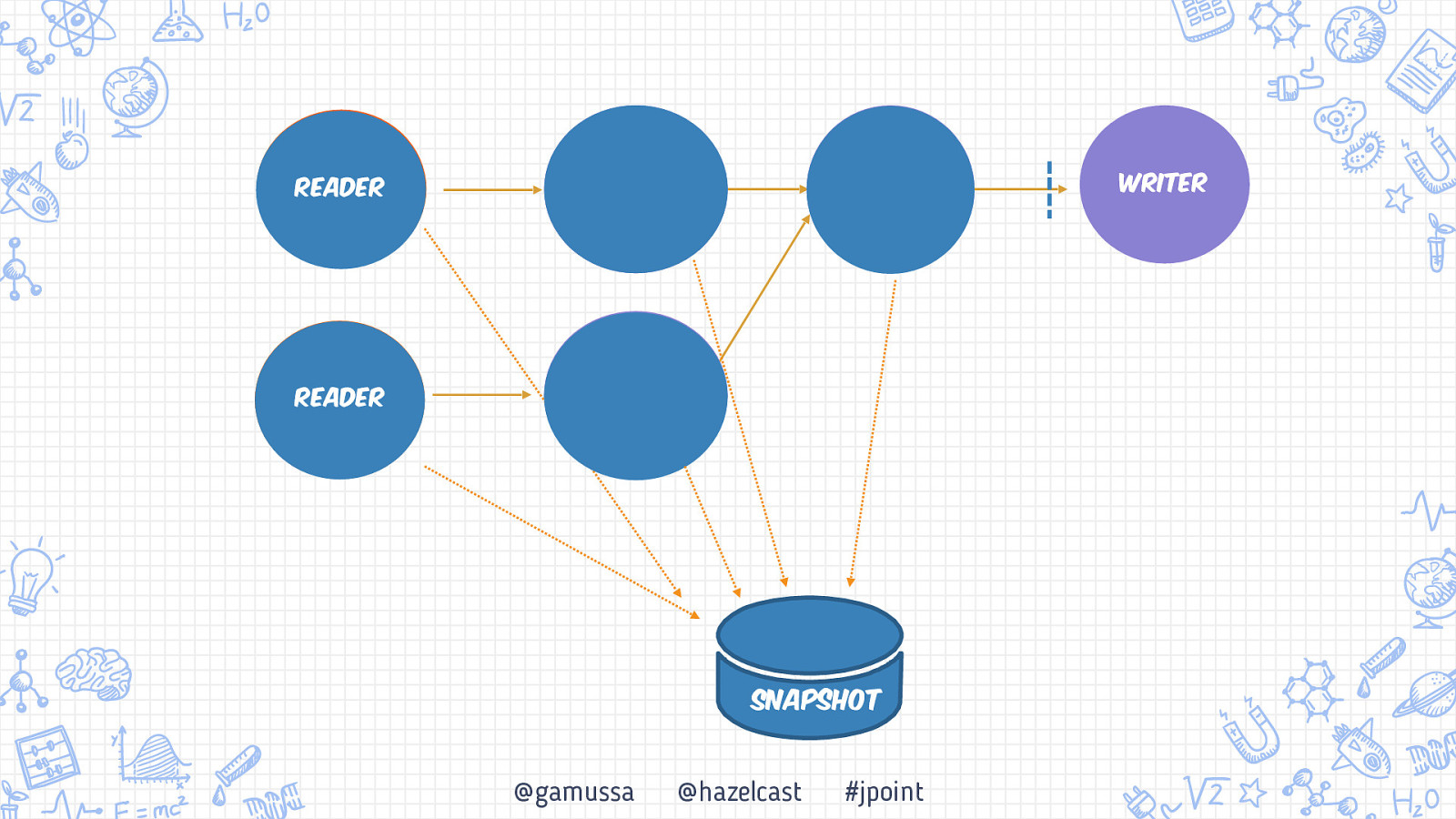
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
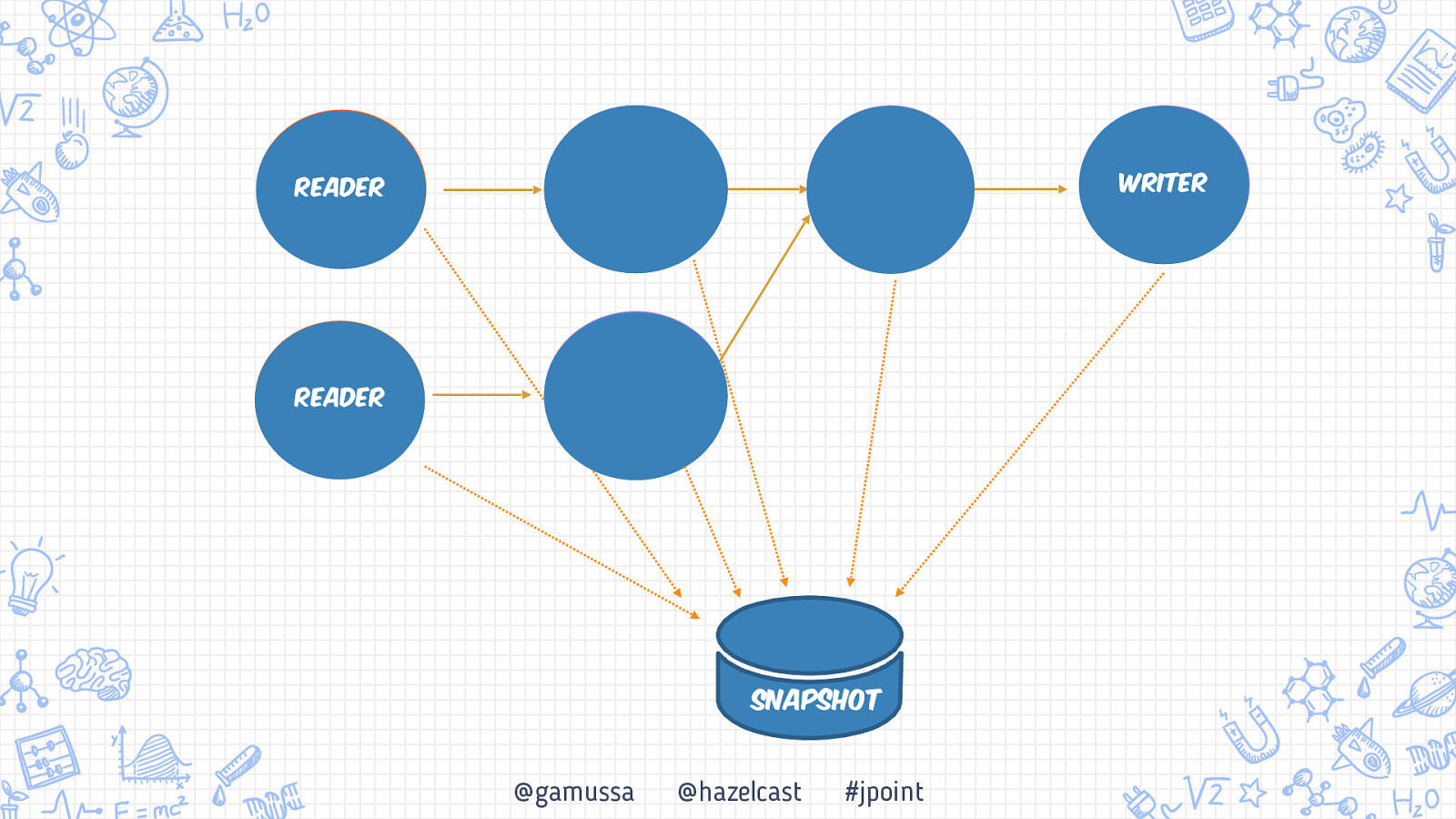
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint
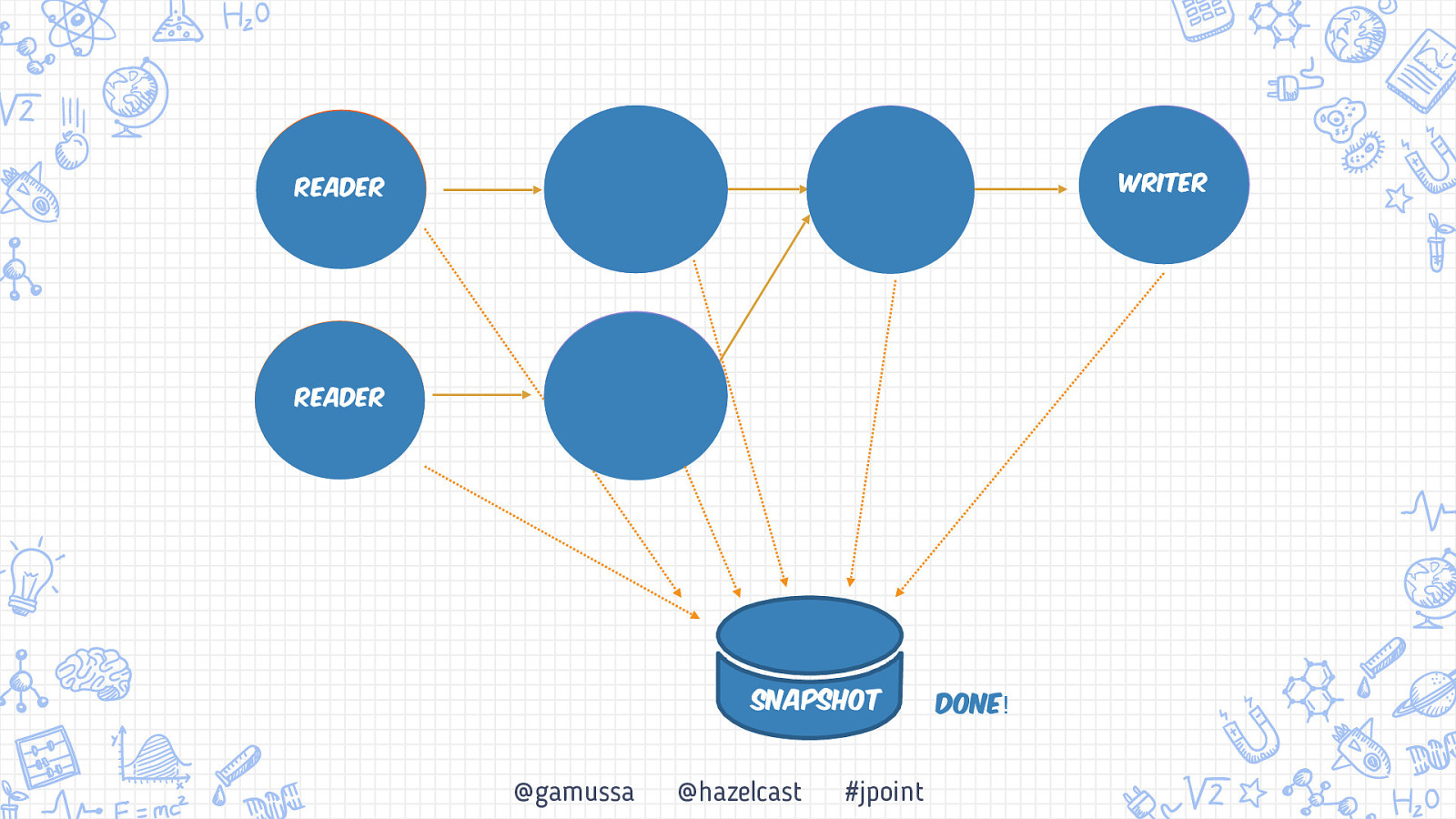
Writer Reader Reader Snapshot @gamussa @hazelcast #jpoint Done!

Как считать «бесконечные» данные? @gamussa @hazelcast #jpoint

Конечное представление бесконечных данных

@gamussa @hazelcast #jpoint

https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 @gamussa @hazelcast #jpoint

Time-based обработка @gamussa @hazelcast #jpoint

Time-based обработка Привязка записей к окнам на основе Времени события Времени обработки @gamussa @hazelcast #jpoint

Time-based обработка Привязка записей к окнам на основе Времени события Времени обработки Сколько ждать «запоздалых» данных? @gamussa @hazelcast #jpoint

Time-based обработка Привязка записей к окнам на основе Времени события Времени обработки Сколько ждать «запоздалых» данных? Точность vs Память @gamussa @hazelcast #jpoint
Fatality @gamussa @hazelcast #jpoint

Потоковая обработка: итоги @gamussa @hazelcast #jpoint

Потоковая обработка: итоги • Получать результаты вычислений реальном времени возможно! @gamussa @hazelcast #jpoint

Потоковая обработка: итоги • Получать результаты вычислений реальном времени возможно! • Окна – конечное представление бесконечных данных • Окна основаны на временнЫх параметрах (время события + время обработки) @gamussa @hazelcast #jpoint

Потоковая обработка: итоги • Получать результаты вычислений реальном времени возможно! • Окна – конечное представление бесконечных данных • Окна основаны на временнЫх параметрах (время события + время обработки) • Обработка «запоздалых» событий • Вам решать, сколько ждать @gamussa @hazelcast #jpoint

hazelcast/hazelcast-jet-code-samples @gamussa @hazelcast #jpoint

СПАСИБО! Вопросы? @gamussa viktor@hazelcast.com @gamussa @hazelcast #jpoint

Виктор возвращается с продолжением доклада про обработку данных в памяти! На этот раз он противопоставит «потоковый» подход «пакетному». Как мы знаем, информации, зараза, много! Мало того, что её много, так ещё никто не хочет сидеть и ждать, пока Hadoop-кластер посчитает всё. Big Data уже не интересно, Fast Data — наше новое «всё»! Так что же делать, если новые данные всё прибывают и прибывают по каналам связи (через сокет-сервер ли или модную нынче Кафку) ежесекундно (а может, даже и быстрее)? Можно было бы складывать их в какое-нибудь хранилище и считать по ночам MapReduce-ом. Или всё-таки прибегнем к потоковой обработке? У каждого подхода есть свои преимущества и недостатки: как очевидные, так и те, что не всегда лежат на поверхности. После небольшого введения и обзора терминов Виктор на основе примеров кода покажет, как использовать Hazelcast Jet для распределенной обработки потоковых данных.