Streams Must Flow: fault-tolerant stream processing apps on Kubernetes June, 2019 / Montreal, CA @gamussa | #ImCloudNative | @ConfluentINc
Slide 1

Slide 2

2 @gamussa | #ImCloudNative | @ConfluentINc
Slide 3

3 Special thanks! @gwenshap @gamussa @MatthiasJSax | #ImCloudNative | @ConfluentINc
Slide 4

4 Agenda Kafka Streams 101 How do Kafka Streams applications scale? Kubernetes 101 Recommendations for Kafka Streams @gamussa | #ImCloudNative | @ConfluentINc
Slide 5

https://gamov.dev/streams-k8s @gamussa | #ImCloudNative | @ConfluentINc
Slide 6
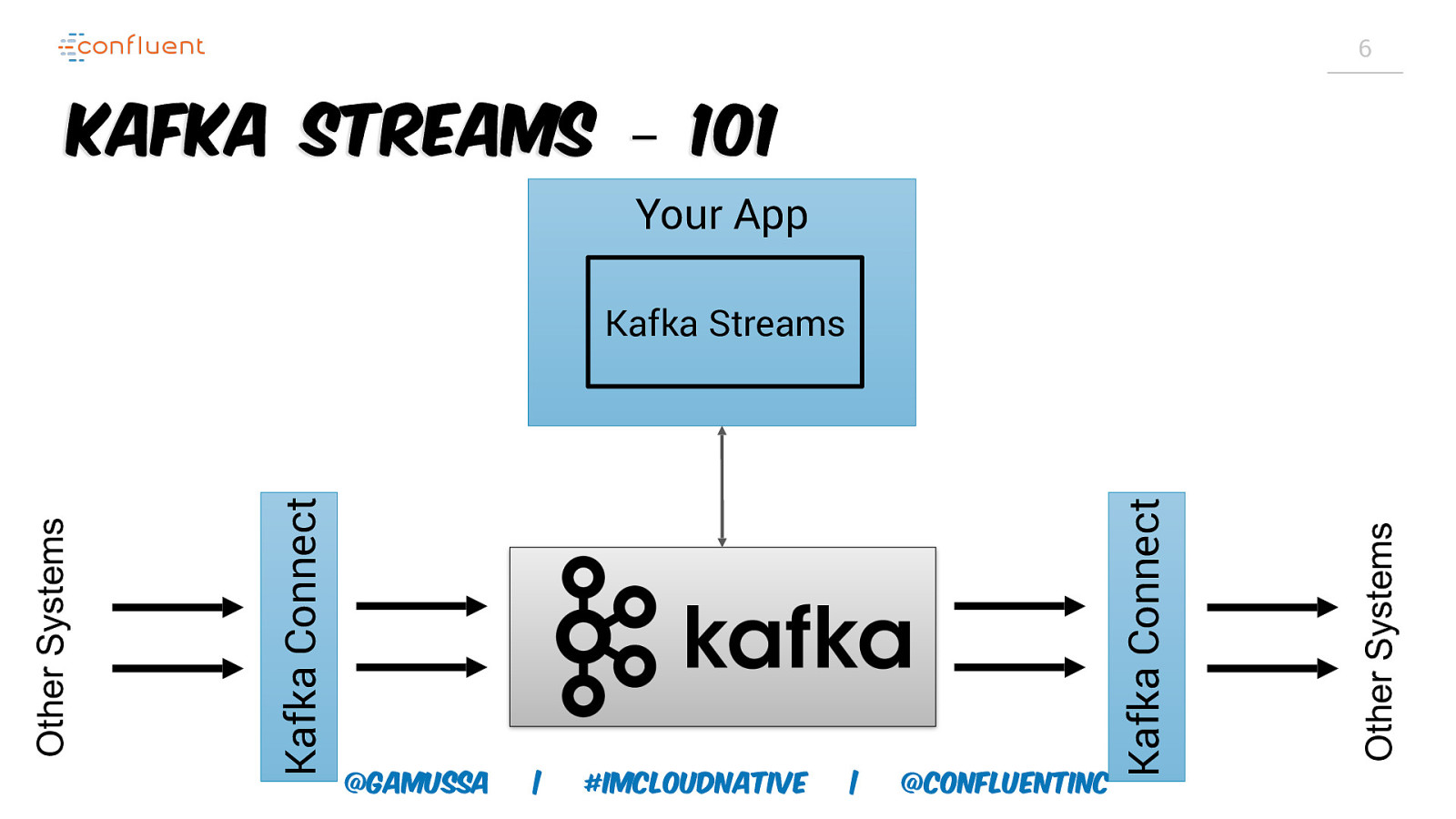
6 Kafka Streams – 101 Your App @gamussa | #ImCloudNative | @ConfluentINc Other Systems Kafka Connect Kafka Connect Other Systems Kafka Streams
Slide 7

7 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #ImCloudNative | @ConfluentINc
Slide 8

8 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #ImCloudNative | @ConfluentINc
Slide 9

9 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #ImCloudNative | @ConfluentINc
Slide 10

10 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #ImCloudNative | @ConfluentINc
Slide 11
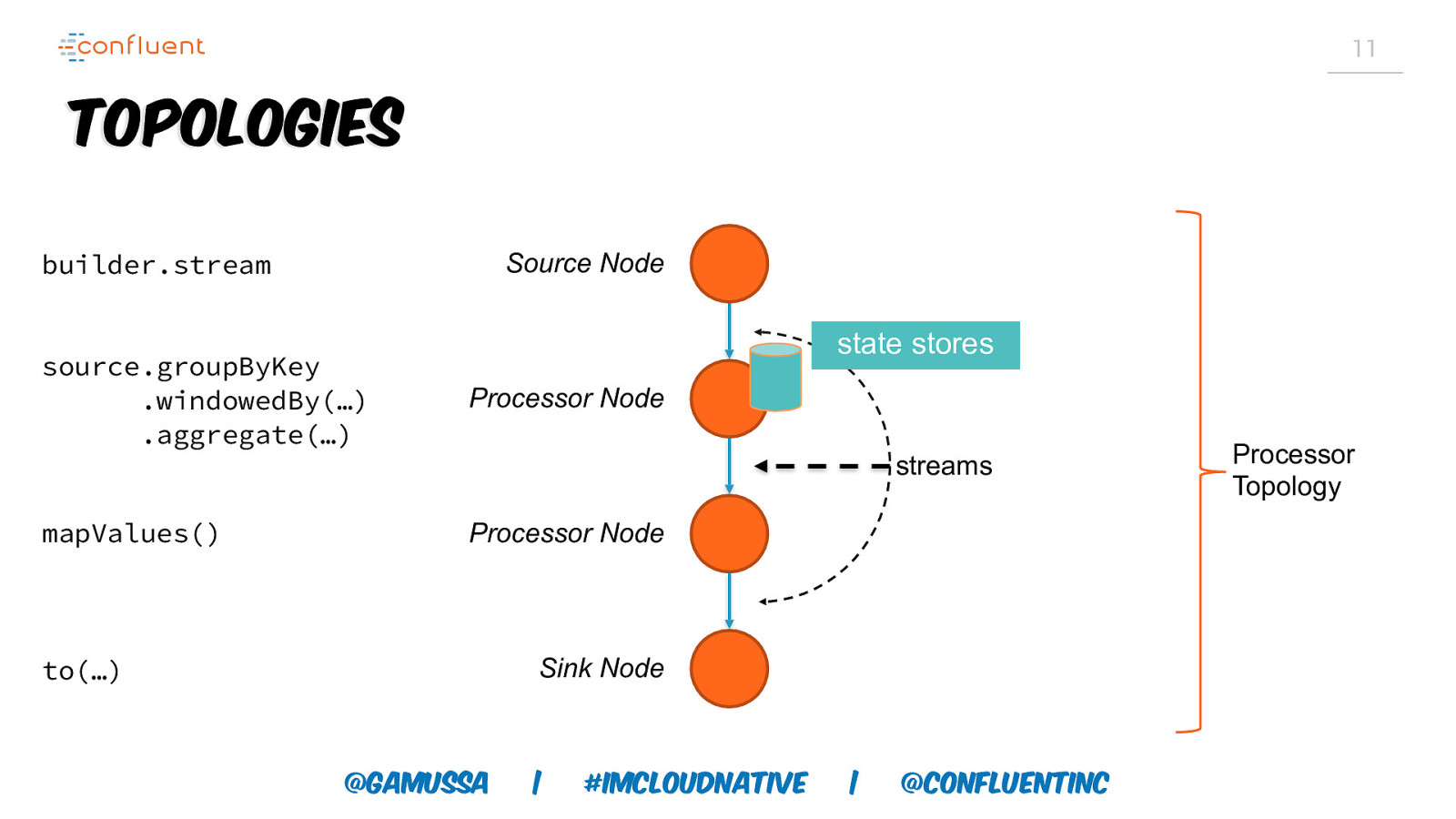
11 Topologies builder.stream Source Node state stores source.groupByKey .windowedBy(…) .aggregate(…) Processor Node mapValues() Processor Node streams Sink Node to(…) @gamussa | #ImCloudNative | @ConfluentINc Processor Topology
Slide 12

How Do Kafka Streams Application Scale? @gamussa | #ImCloudNative | @ConfluentINc
Slide 13

CONSUMERS CONSUMER GROUP COORDINATOR CONSUMER GROUP
Slide 14
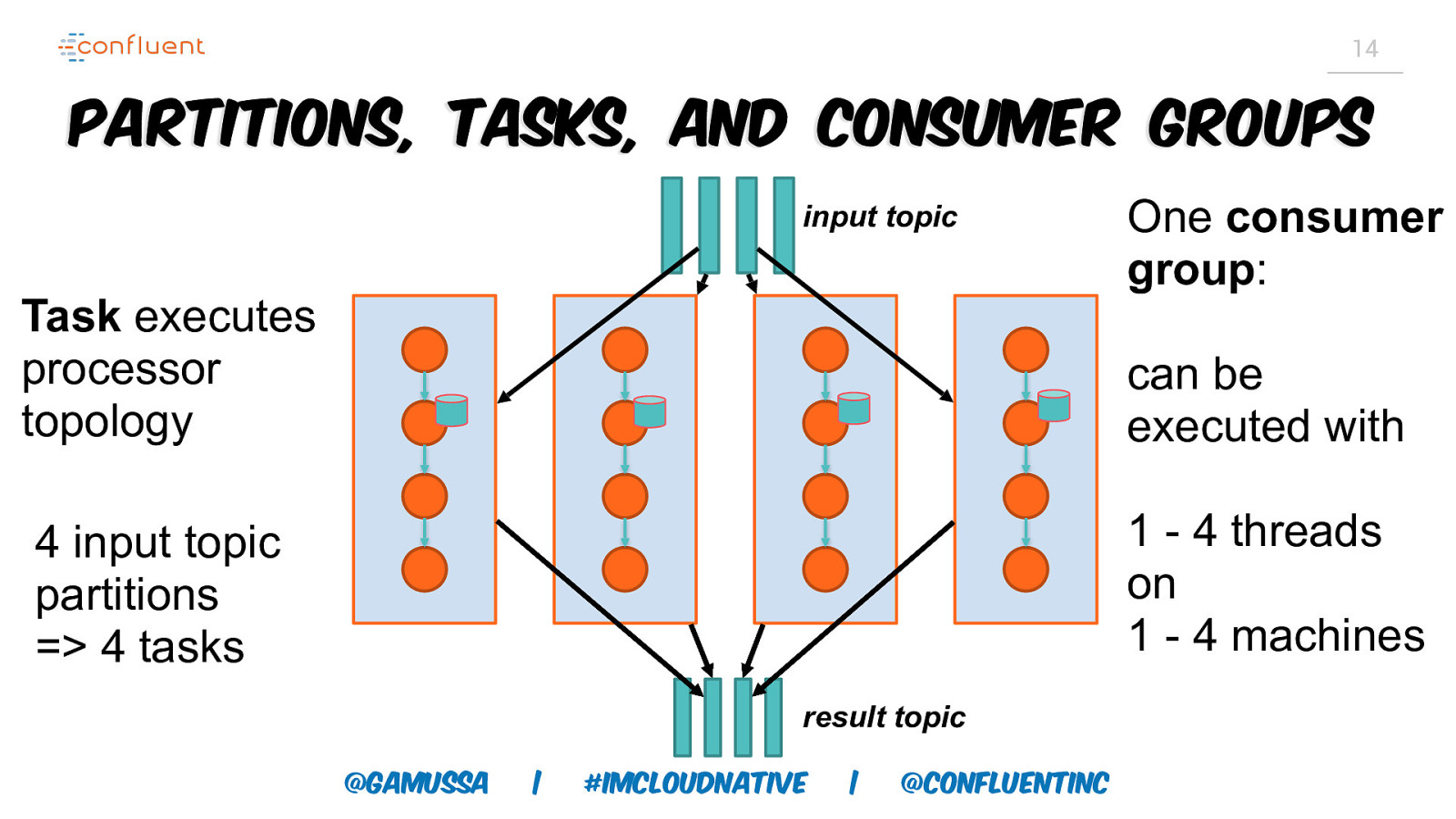
14 Partitions, Tasks, and Consumer Groups input topic Task executes processor topology One consumer group: can be executed with 1 - 4 threads on 1 - 4 machines 4 input topic partitions => 4 tasks result topic @gamussa | #ImCloudNative | @ConfluentINc
Slide 15
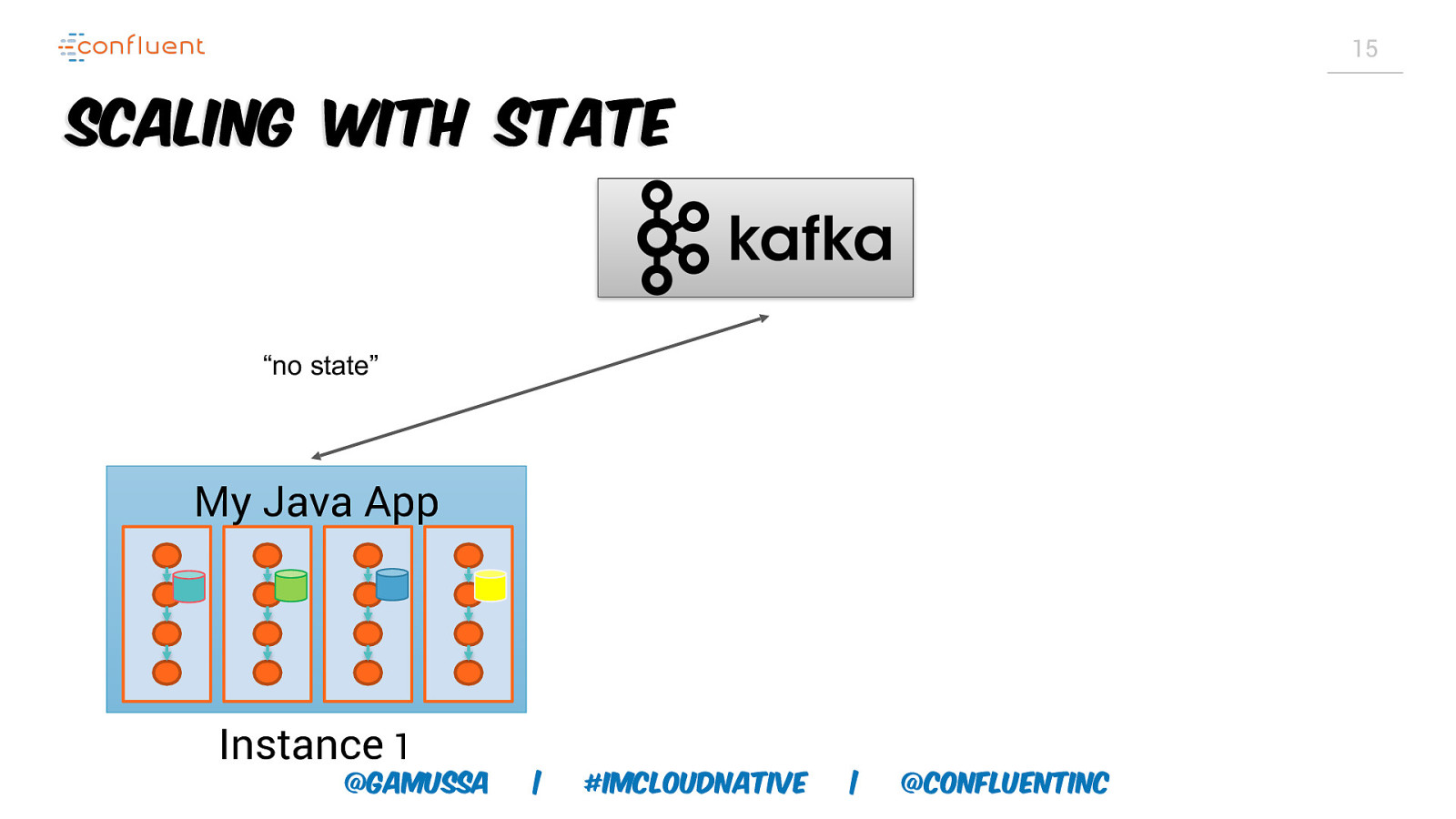
15 Scaling with State “no state” My Java App Instance 1 @gamussa | #ImCloudNative | @ConfluentINc
Slide 16
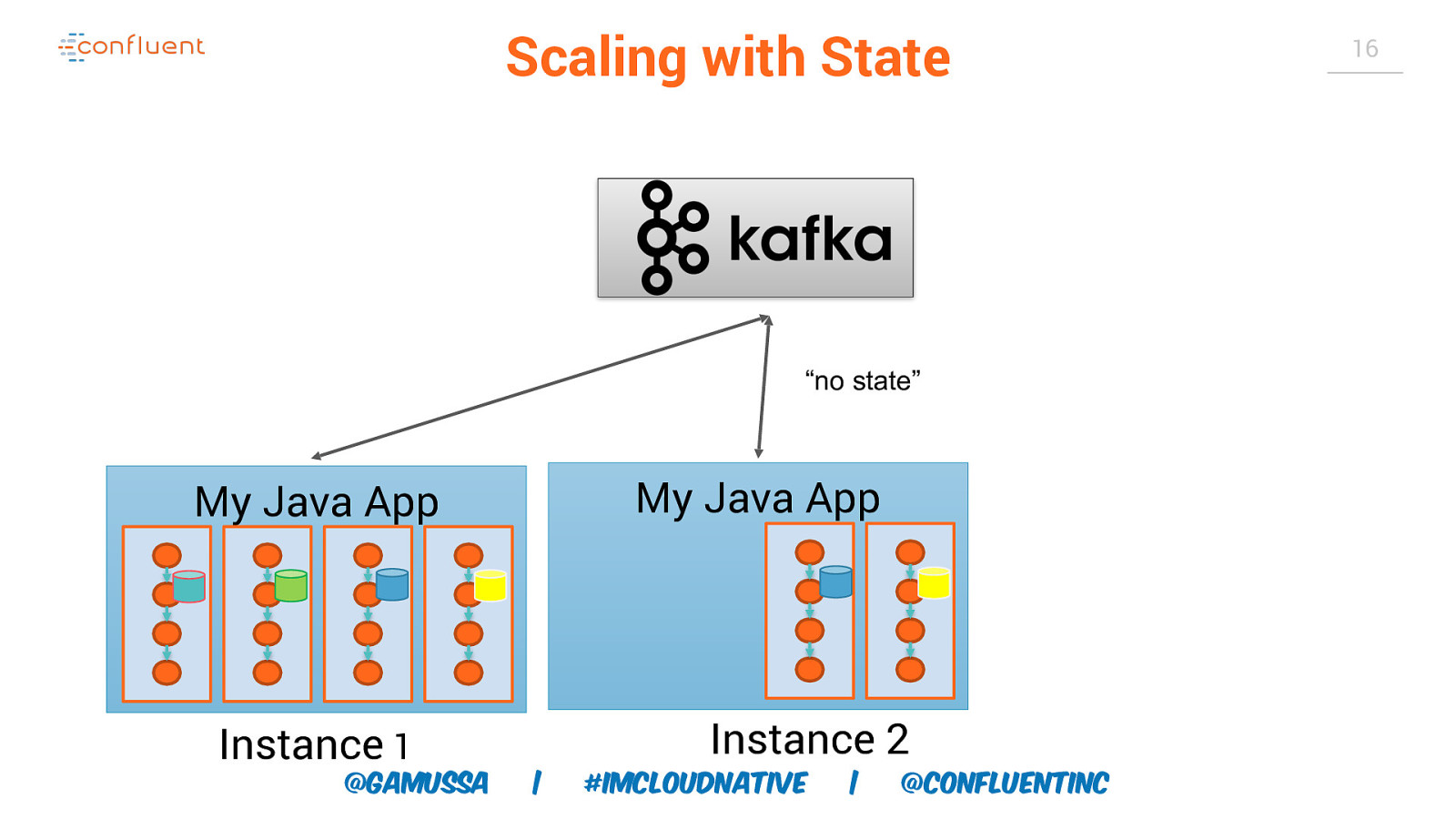
Scaling with State “no state” My Java App My Java App Instance 1 @gamussa Instance 2 | #ImCloudNative | @ConfluentINc 16
Slide 17
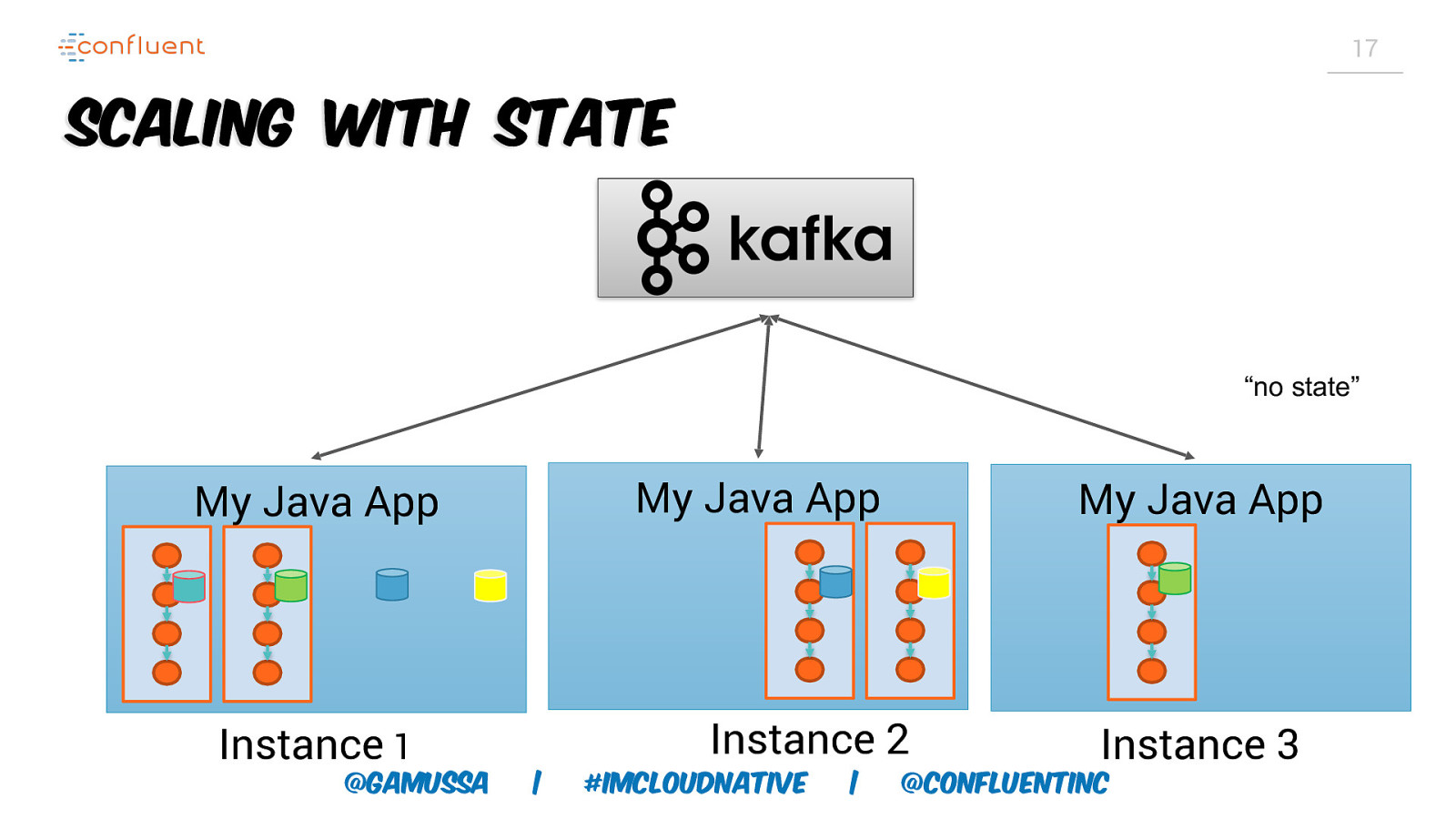
17 Scaling with State “no state” My Java App My Java App Instance 1 @gamussa My Java App Instance 2 | #ImCloudNative | Instance 3 @ConfluentINc
Slide 18

18 Scaling and FaultTolerance Two Sides of Same Coin @gamussa | #ImCloudNative | @ConfluentINc
Slide 19
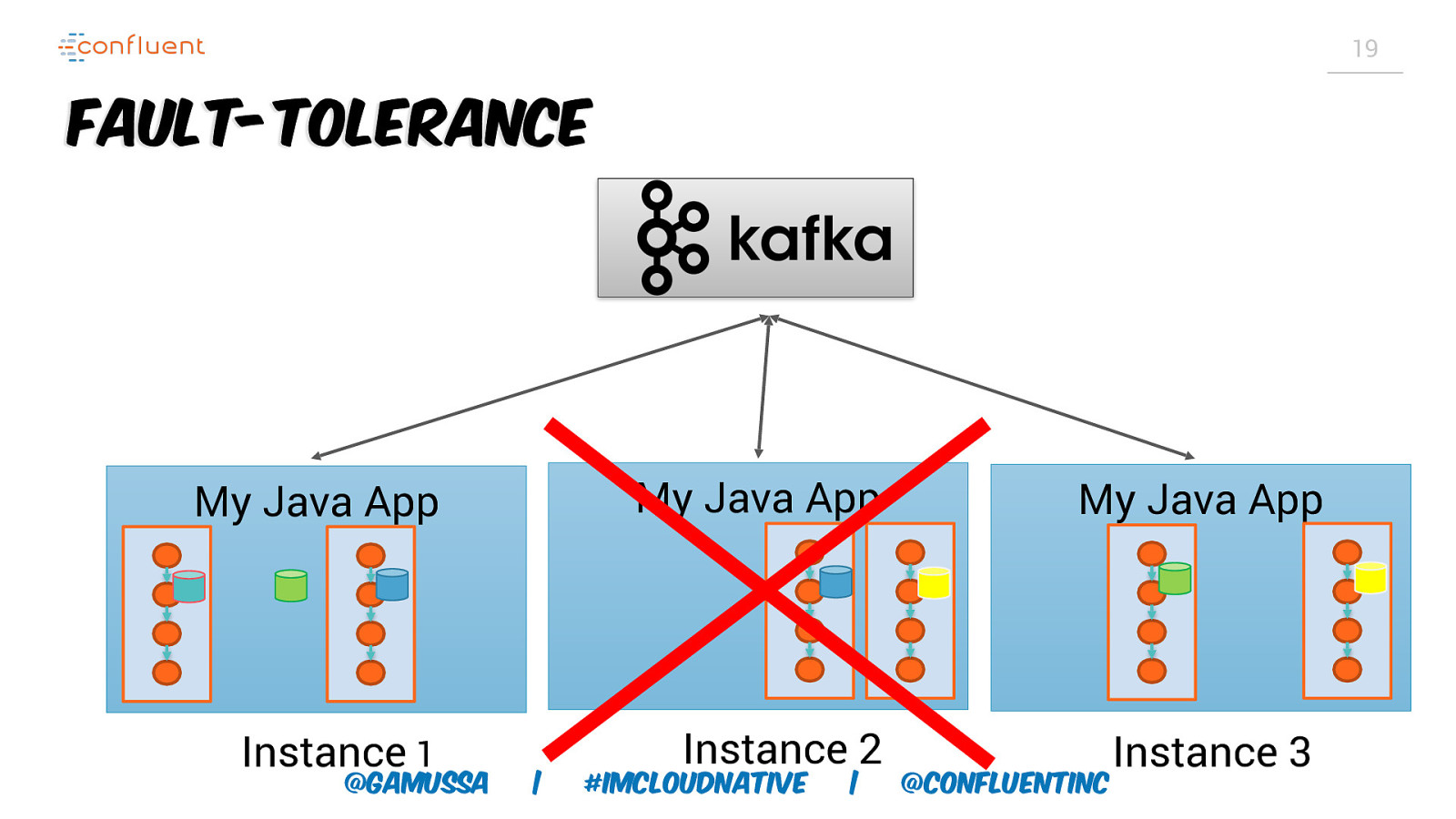
19 Fault-Tolerance My Java App My Java App My Java App Instance 1 Instance 2 Instance 3 @gamussa | #ImCloudNative | @ConfluentINc
Slide 20
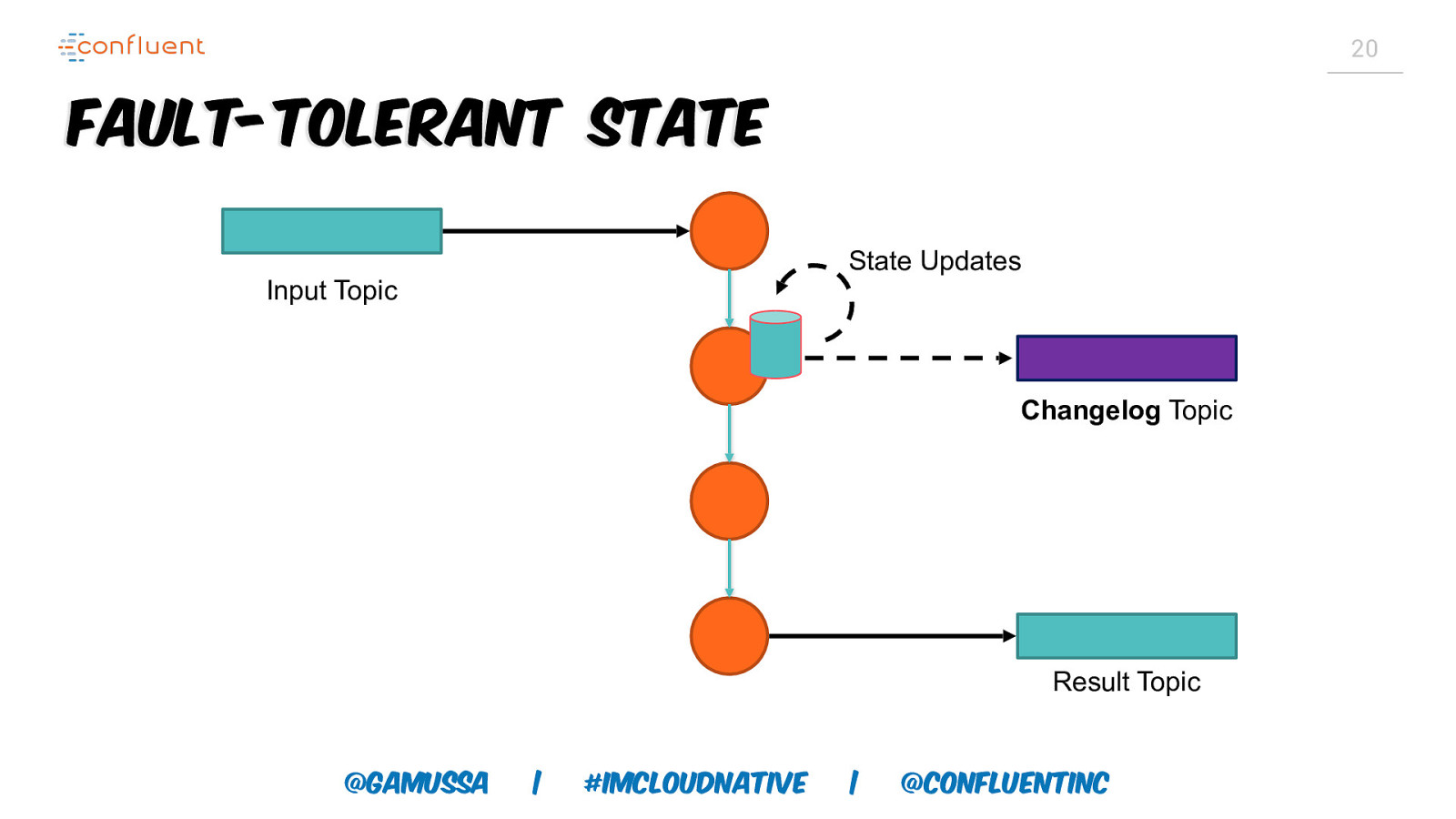
20 Fault-Tolerant State State Updates Input Topic Changelog Topic Result Topic @gamussa | #ImCloudNative | @ConfluentINc
Slide 21
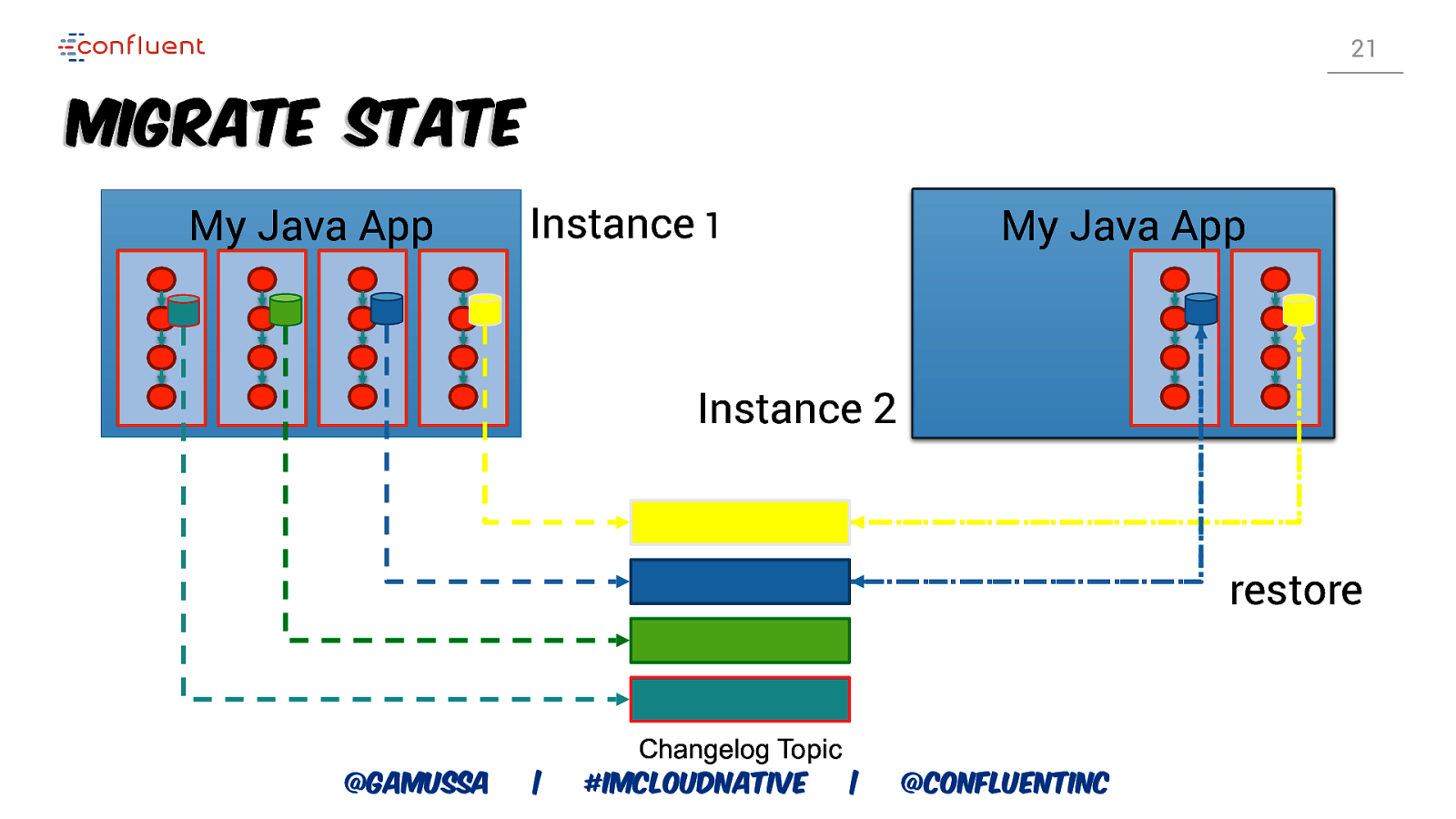
21 Migrate State My Java App Instance 1 Trade My Java StatsApp App Instance 2 restore Changelog Topic @gamussa | #ImCloudNative | @ConfluentINc
Slide 22

22 Recovery Time • Changelog topics are log compacted • Size of changelog topic linear in size of state • Large state implies high recovery times @gamussa | #ImCloudNative | @ConfluentINc
Slide 23

Recommendations for Kafka Streams @gamussa | #ImCloudNative | @ConfluentINc
Slide 24
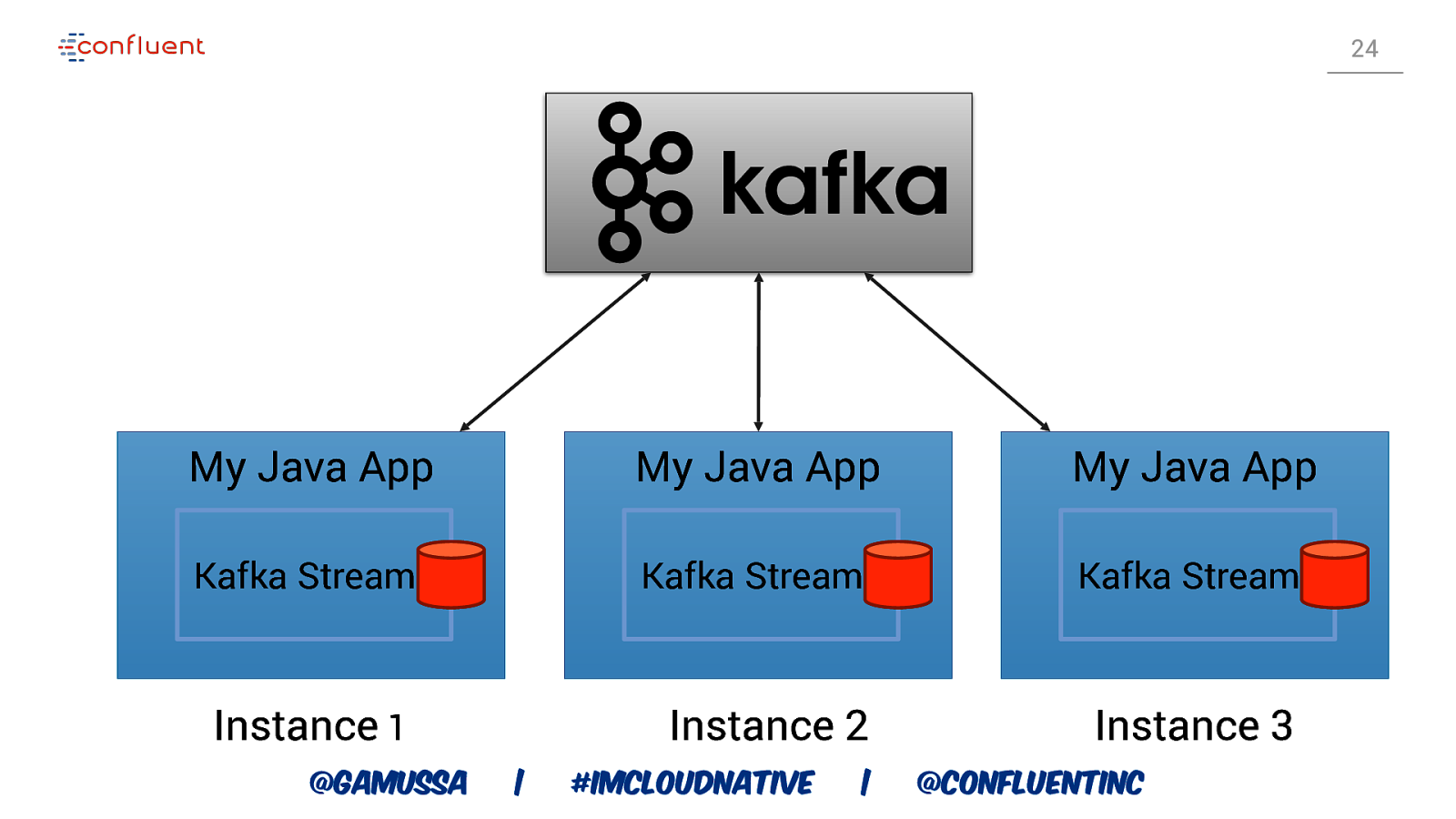
24 My Java App My Java App My Java App Kafka Streams Kafka Streams Kafka Streams Instance 1 Instance 2 Instance 3 @gamussa | #ImCloudNative | @ConfluentINc
Slide 25
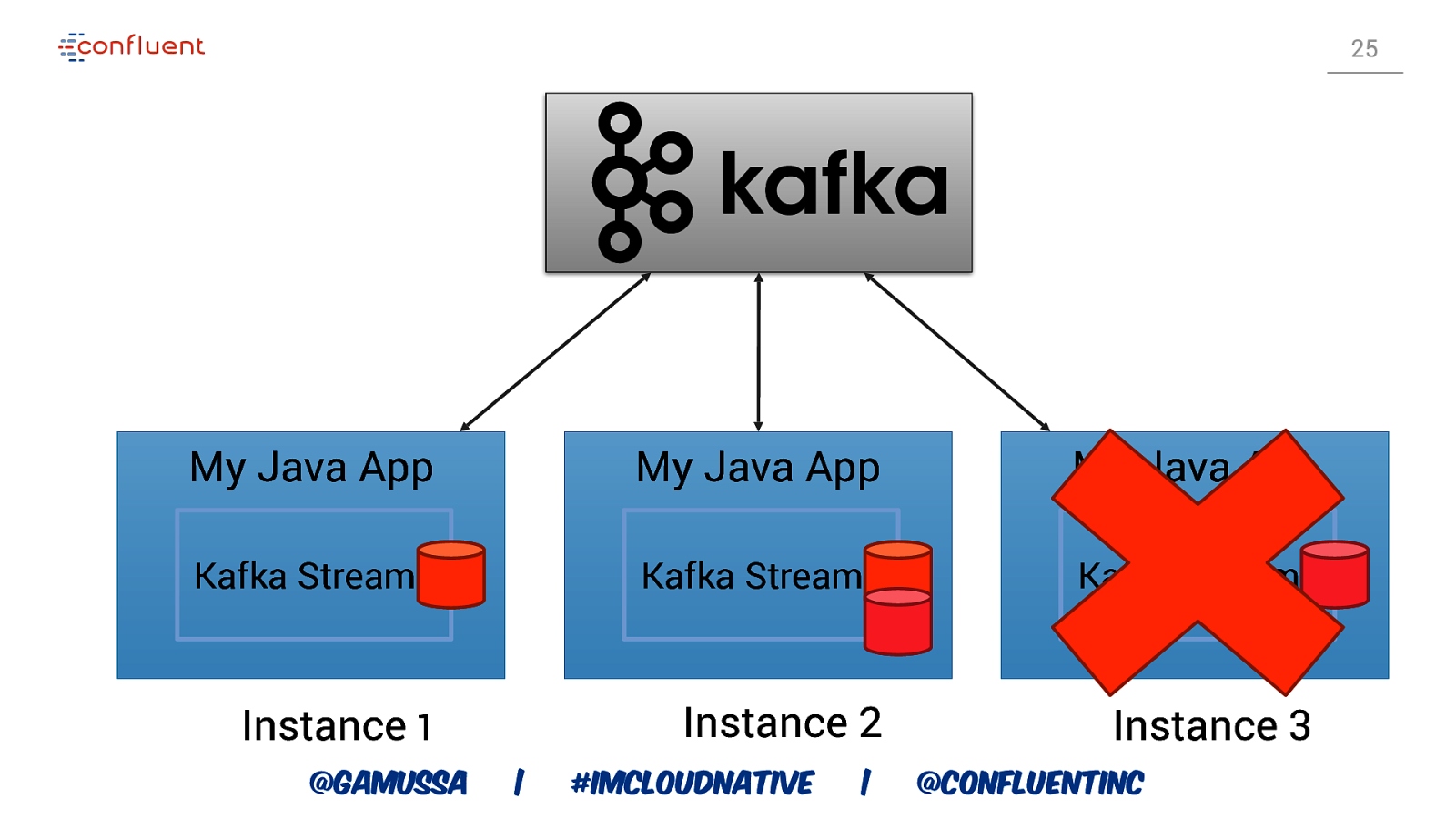
25 My Java App My Java App My Java App Kafka Streams Kafka Streams Kafka Streams Instance 1 Instance 2 Instance 3 @gamussa | #ImCloudNative | @ConfluentINc
Slide 26

26 StatefulSets are new and complicated. We don’t need them. @gamussa | #ImCloudNative | @ConfluentINc
Slide 27

27 Recovering state takes time. Statelful is faster. @gamussa | #ImCloudNative | @ConfluentINc
Slide 28
28 But I’ll want to scale-out and back anyway. @gamussa | #ImCloudNative | @ConfluentINc
Slide 29

29 @gamussa | #ImCloudNative | @ConfluentINc
Slide 30

30 I don’t really trust my storage admin anyway @gamussa | #ImCloudNative | @ConfluentINc
Slide 31

31 Recommendations ● Keep changelog shards small ● If you trust your storage: Use StatefulSets ● Use anti-affinity when possible ● Use “parallel” pod management
Slide 32

32 🛑 Stop! Demo time! @gamussa | #ImCloudNative | @ConfluentINc
Slide 33

33 Summary Kafka Streams has recoverable state, that gives streams apps easy elasticity and high availability Kubernetes makes it easy to scale applications It also has StatefulSets for applications with state @gamussa | #ImCloudNative | @ConfluentINc
Slide 34

34 Summary Now you know how to deploy Kafka Streams on Kubernetes and take advantage on all the scalability and highavailability capabilities @gamussa | #ImCloudNative | @ConfluentINc
Slide 35

35 Resources and Next Steps https://cnfl.io/helm_video https://cnfl.io/cp-helm https://cnfl.io/k8s https://slackpass.io/confluentcommunity #kubernetes @gamussa | #ImCloudNative | @ConfluentINc
Slide 36

Thanks! @gamussa viktor@confluent.io We are hiring! https://www.confluent.io/careers/ @gamussa | @ #ImCloudNative | @ConfluentINc
Slide 37

37