Apache Kafka Event-Streaming Platform for .NET Developers
A presentation at NDC Sydney in in Sydney NSW, Australia by Viktor Gamov

#NDCSydney @ndc_conferences Apache Kafka Event-Streaming Platform October, 2019 for .NET Developers @gamussa | #NDCSydney | @ConfluentINc

2 @gamussa | #NDCSydney | @ConfluentINc

3 I build highly scalable Hello World apps @gamussa | #NDCSydney | @ConfluentINc

4 A company is build on DATA FLOWS but All we have is DATA STORES @gamussa | #NDCSydney | @ConfluentINc
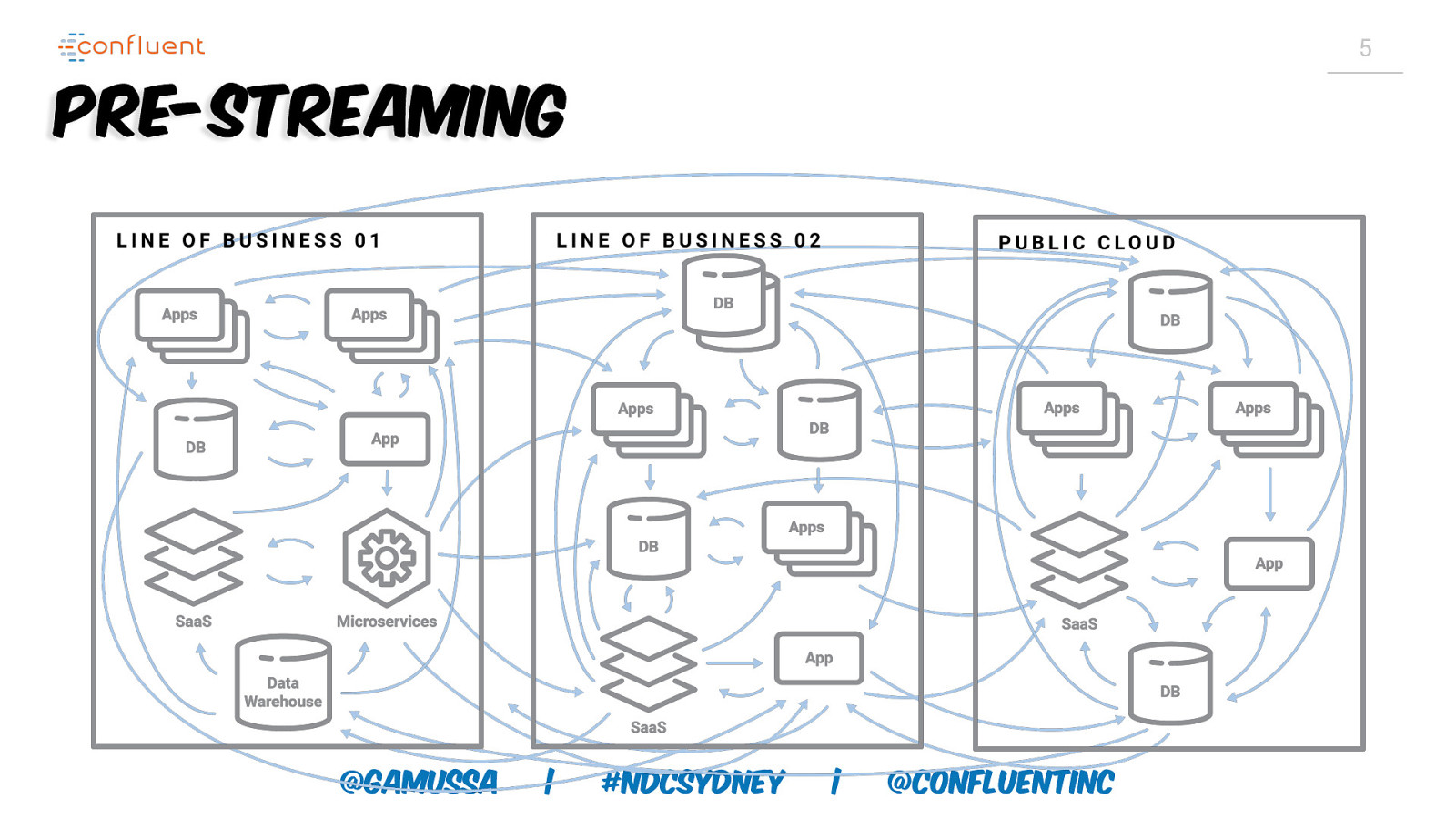
5 Pre-Streaming @gamussa | #NDCSydney | @ConfluentINc
6 @gamussa | #NDCSydney | @ConfluentINc
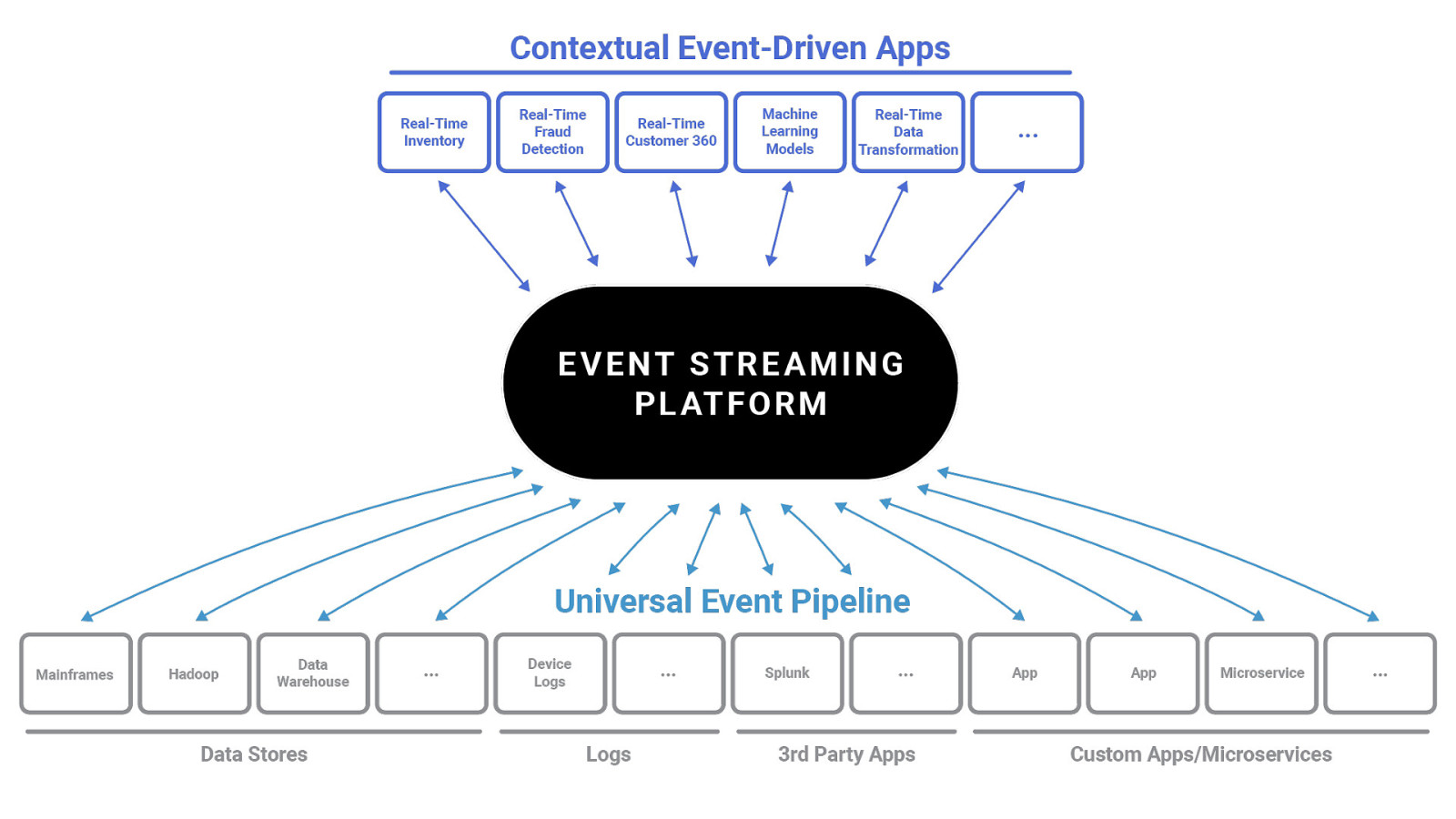
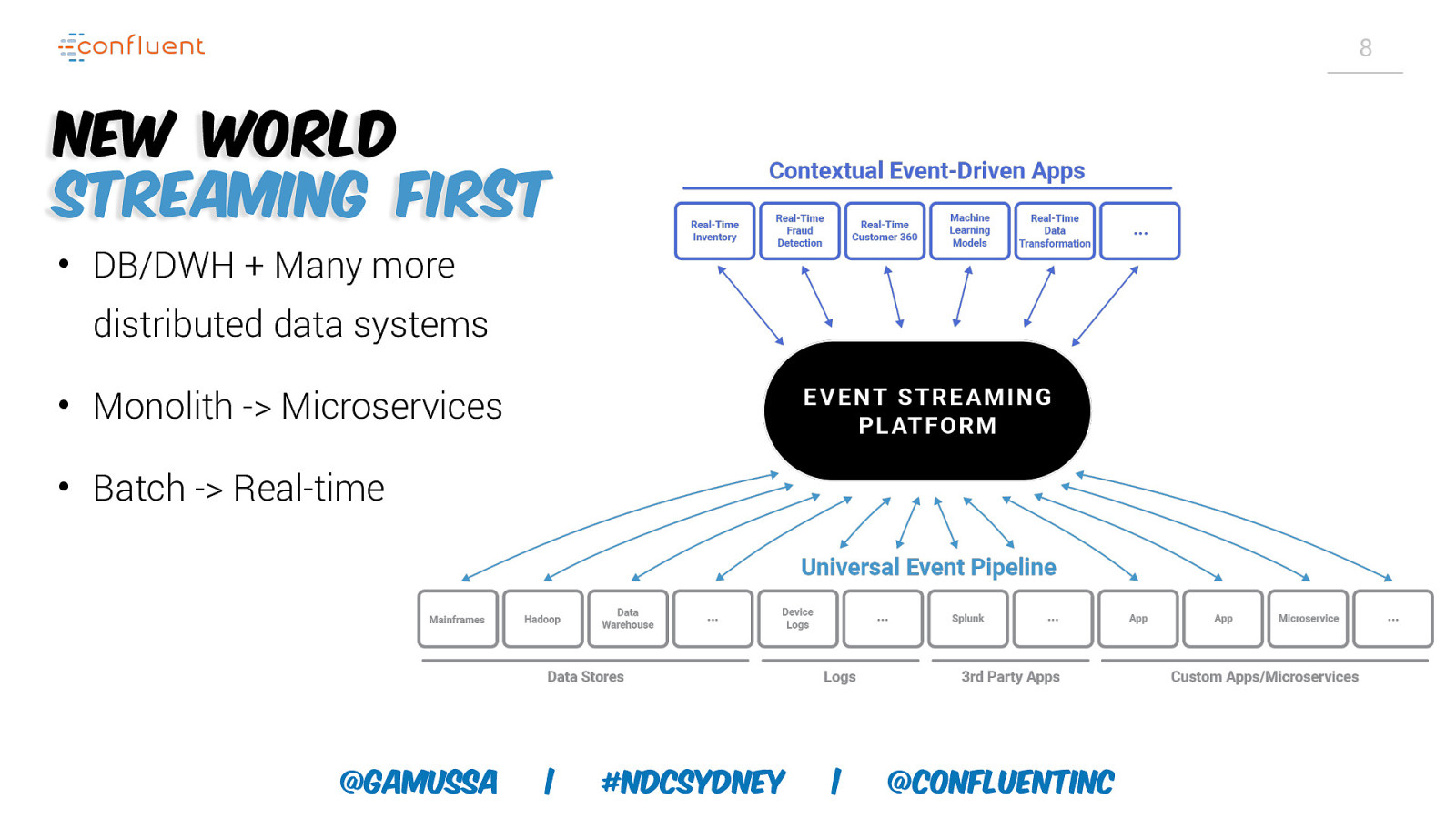
8 New World Streaming first • DB/DWH + Many more distributed data systems • Monolith -> Microservices • Batch -> Real-time @gamussa | #NDCSydney | @ConfluentINc
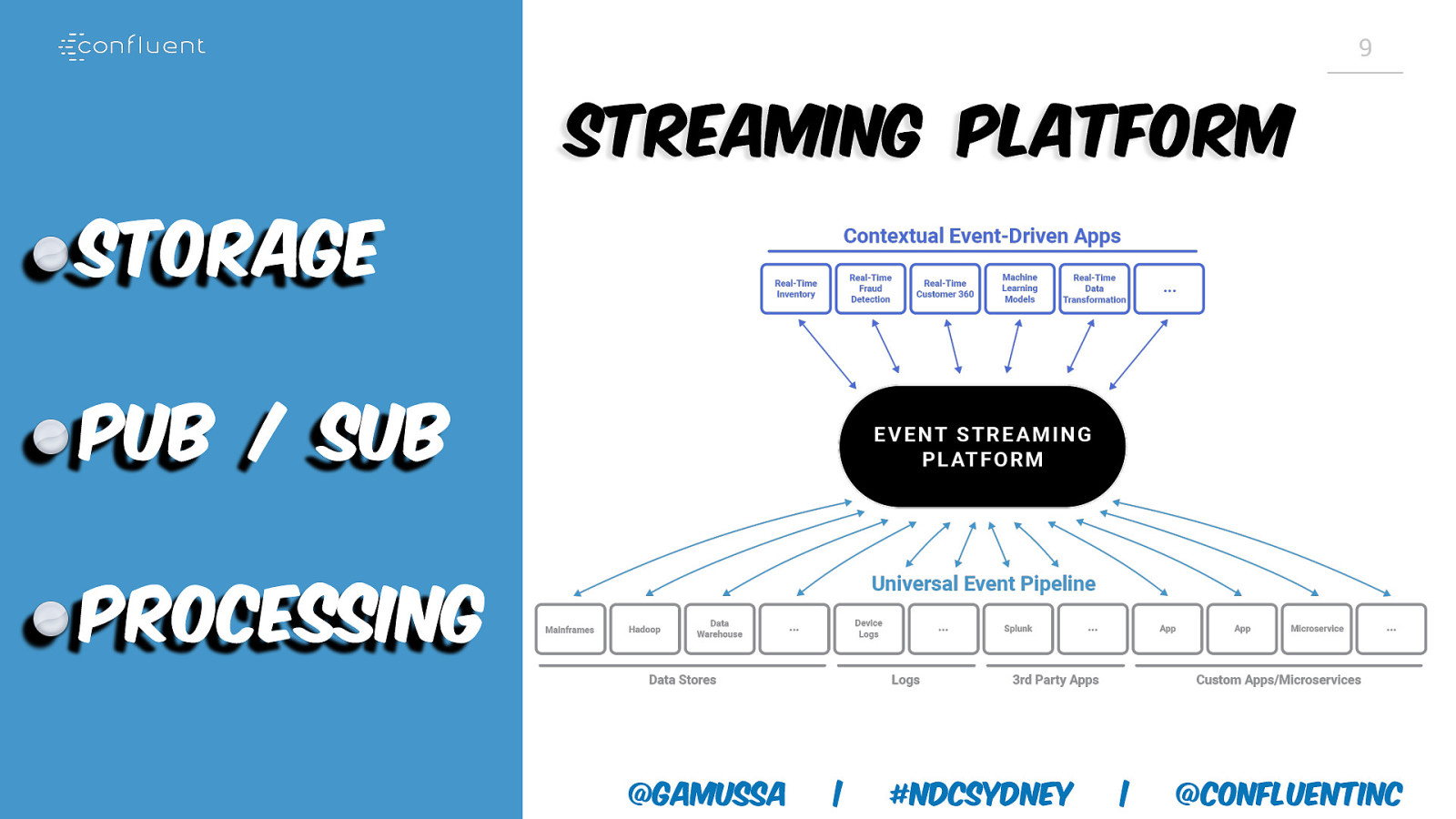
9 Streaming Platform Storage Pub / Sub Processing @gamussa | #NDCSydney | @ConfluentINc

10 Storage @gamussa | #NDCSydney | @ConfluentINc

11 Core Abstraction ● DB - table ● Hadoop - file ● Kafka - ? @gamussa | #NDCSydney | @ConfluentINc


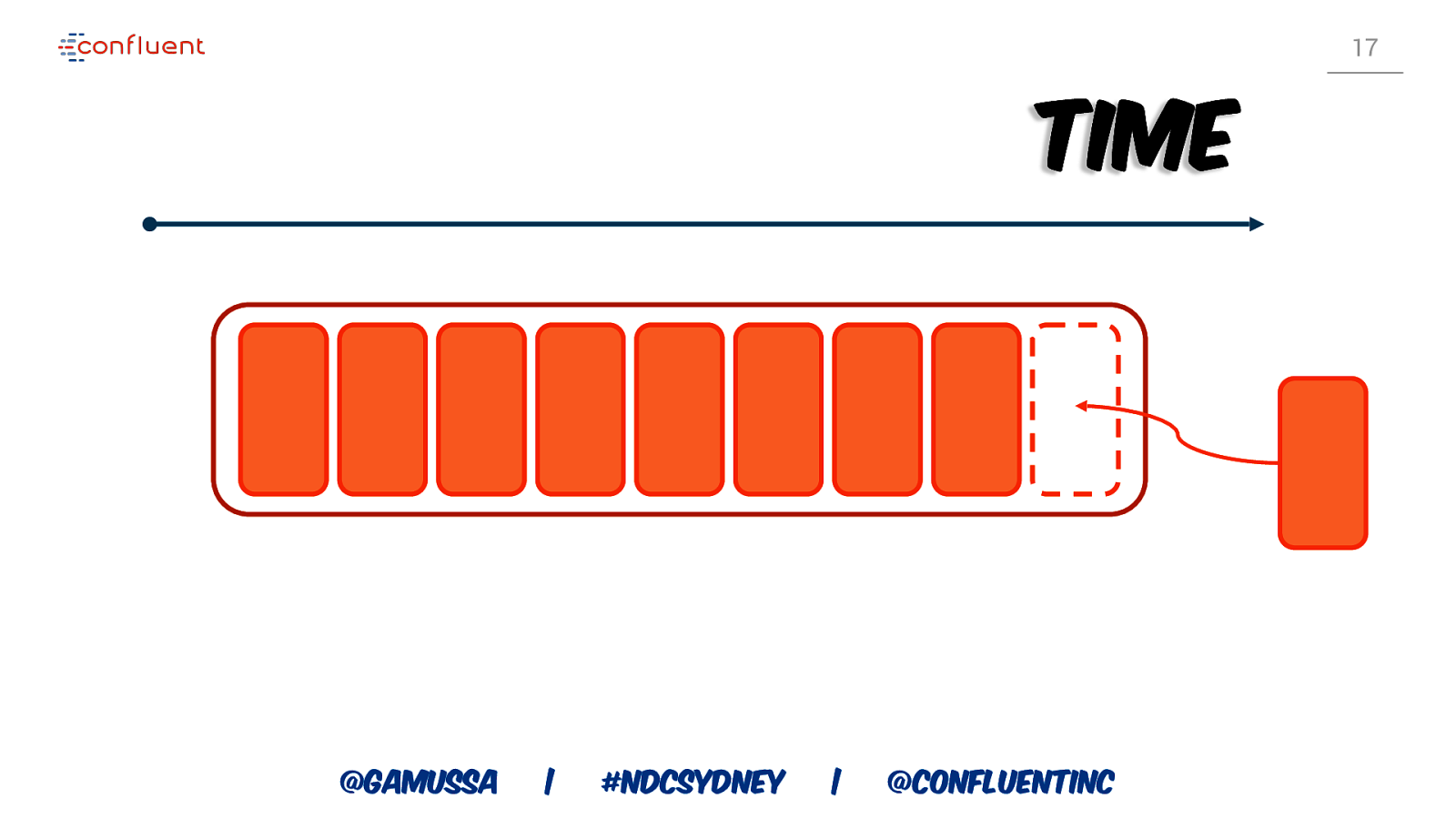
13 LOG @gamussa | #NDCSydney | @ConfluentINc

14 The log is a simple idea New Old Messages are added at the end of the log @gamussa | #NDCSydney | @ConfluentINc

15 The log is a simple idea New Old Messages are added at the end of the log @gamussa | #NDCSydney | @ConfluentINc

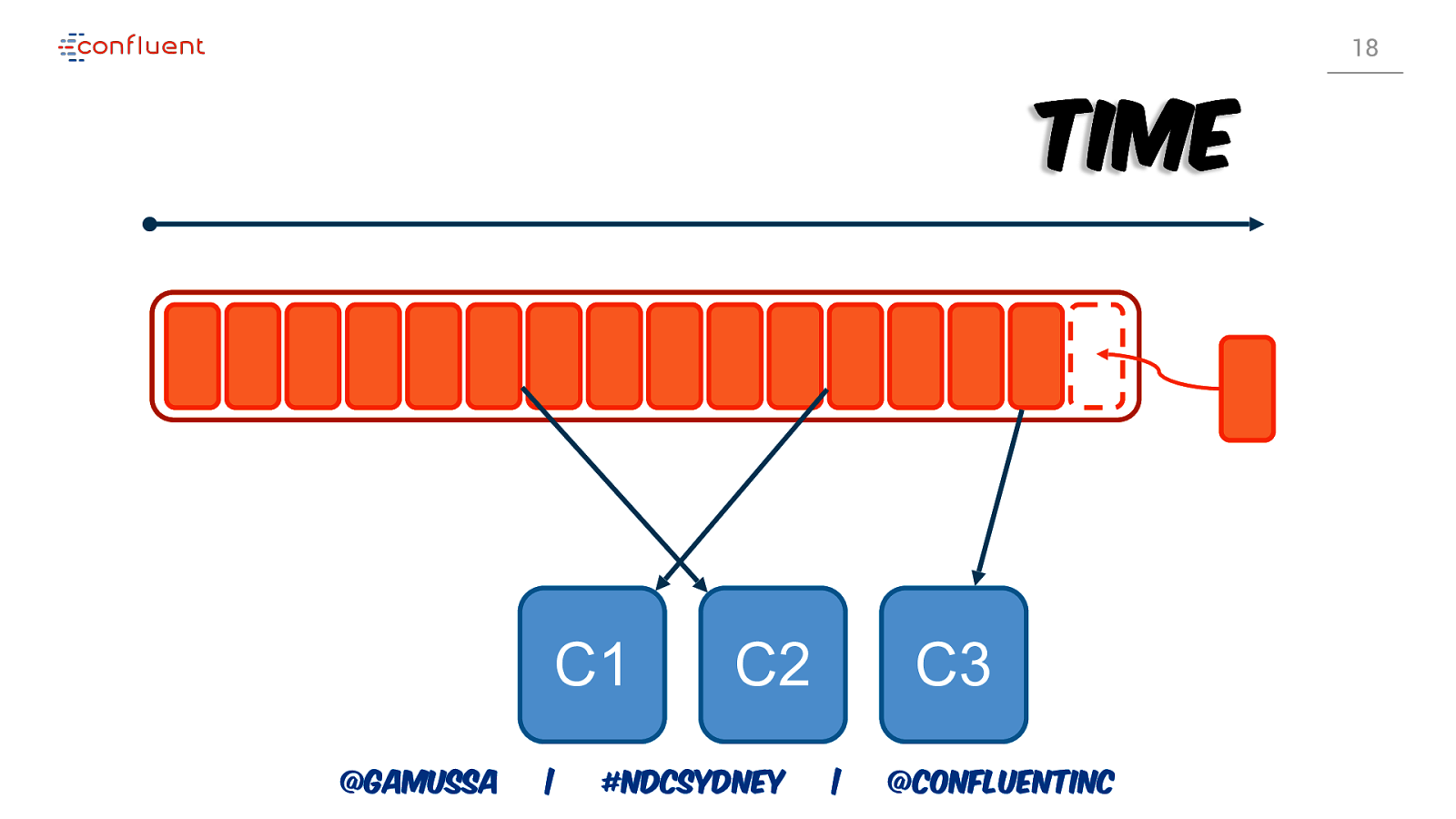
16 Pub / Sub @gamussa | #NDCSydney | @ConfluentINc
17 Time @gamussa | #NDCSydney | @ConfluentINc
18 Time C1 @gamussa | C2 #NDCSydney C3 | @ConfluentINc
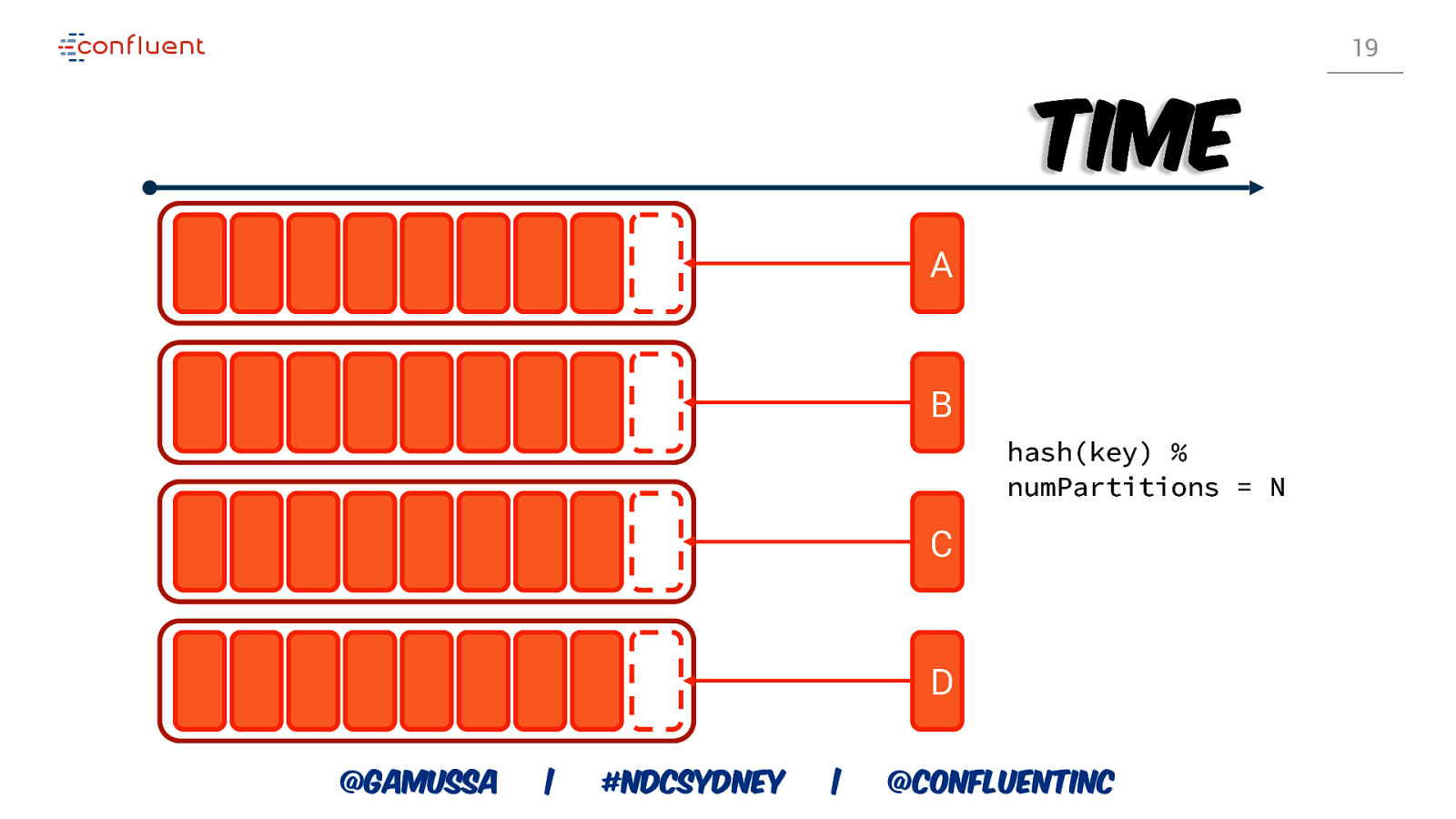
19 Time A B hash(key) % numPartitions = N C D @gamussa | #NDCSydney | @ConfluentINc
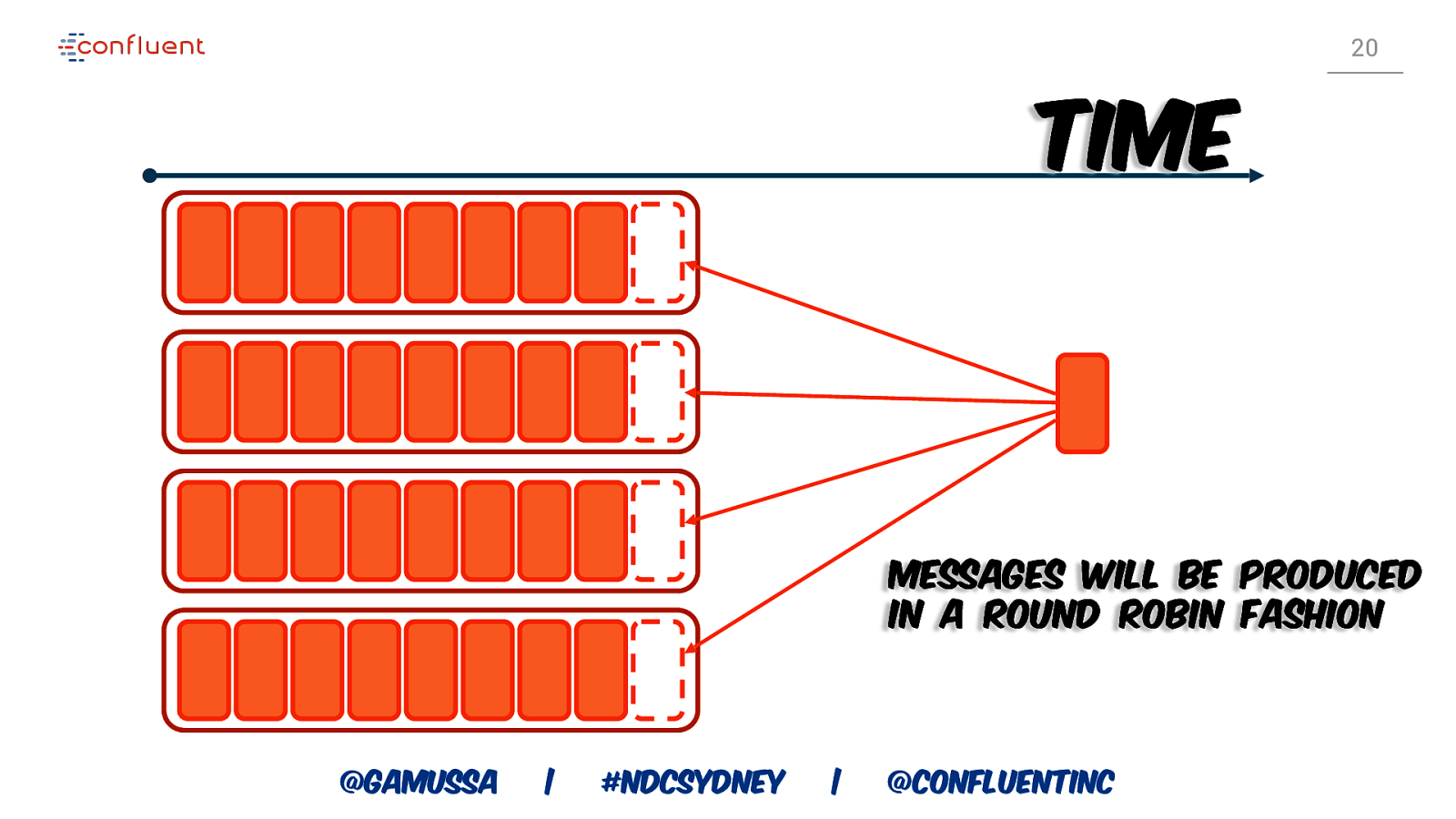
20 Time Messages will be produced in a round robin fashion @gamussa | #NDCSydney | @ConfluentINc
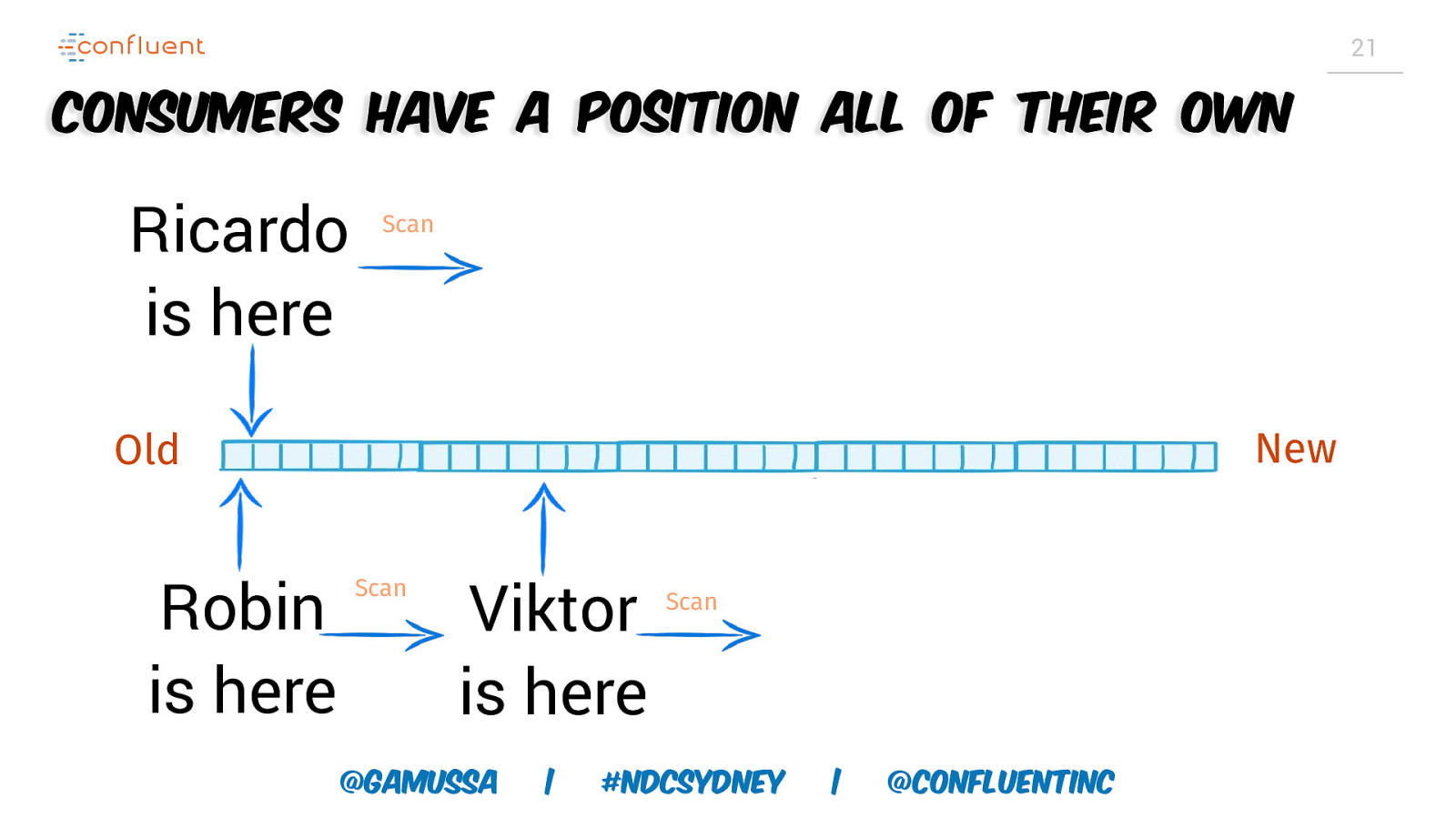
21 Consumers have a position all of their own Ricardo is here Scan New Old Robin is here Scan Viktor is here @gamussa | Scan #NDCSydney | @ConfluentINc
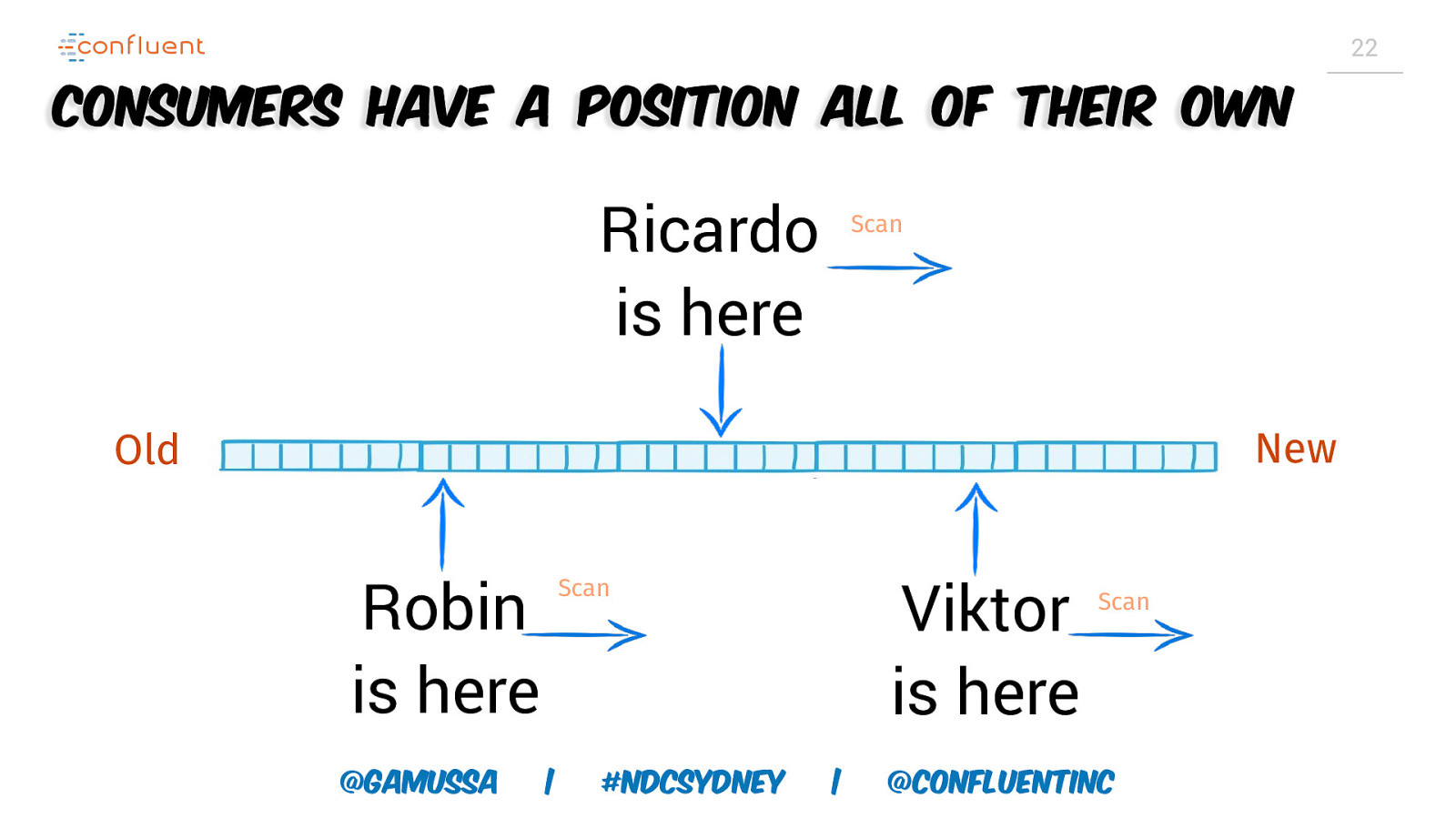
22 Consumers have a position all of their own Ricardo is here Scan New Old Robin is here @gamussa Viktor is here Scan | #NDCSydney | Scan @ConfluentINc
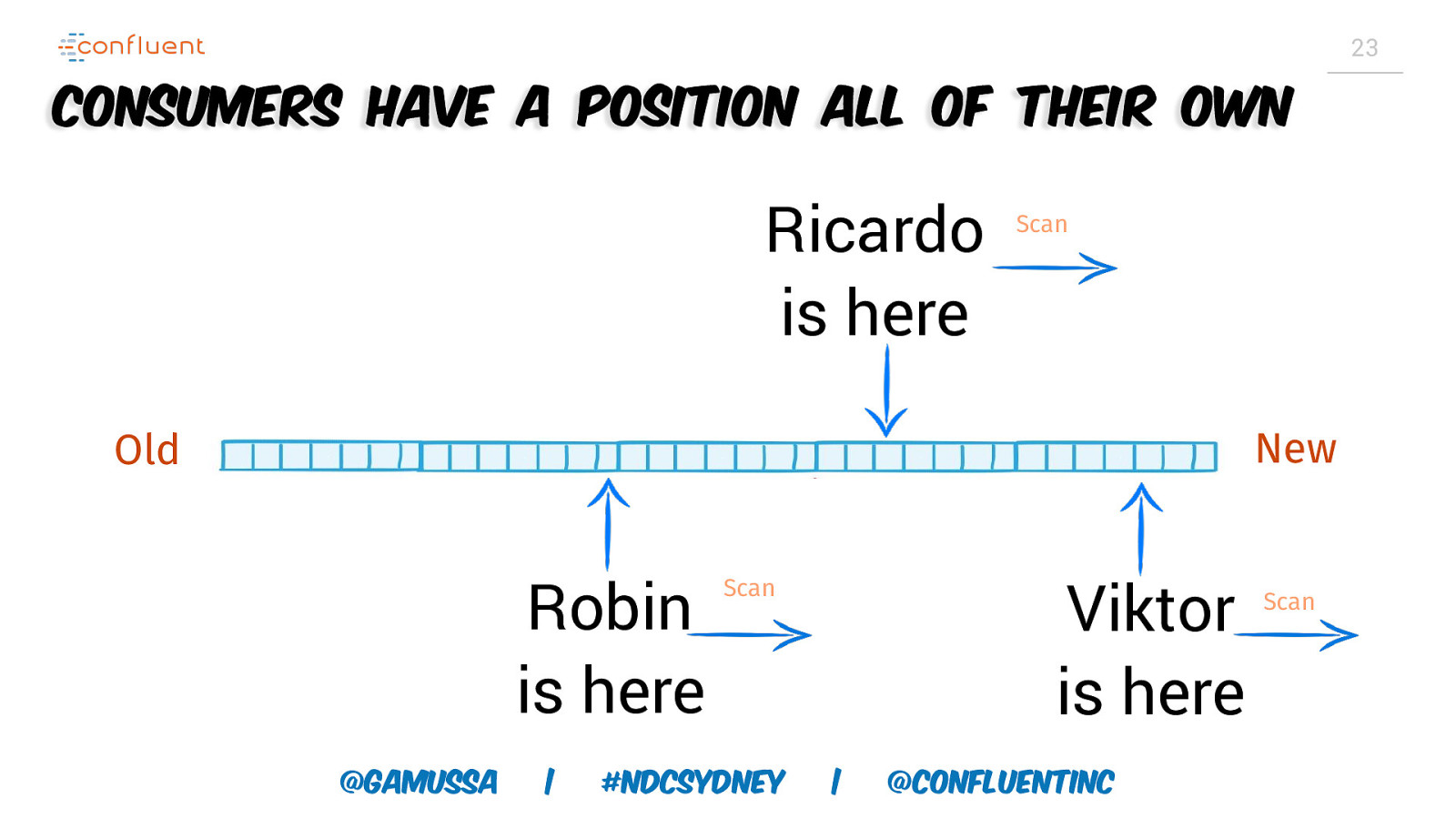
23 Consumers have a position all of their own Ricardo is here Scan New Old Robin is here @gamussa | Viktor is here Scan #NDCSydney | @ConfluentINc Scan
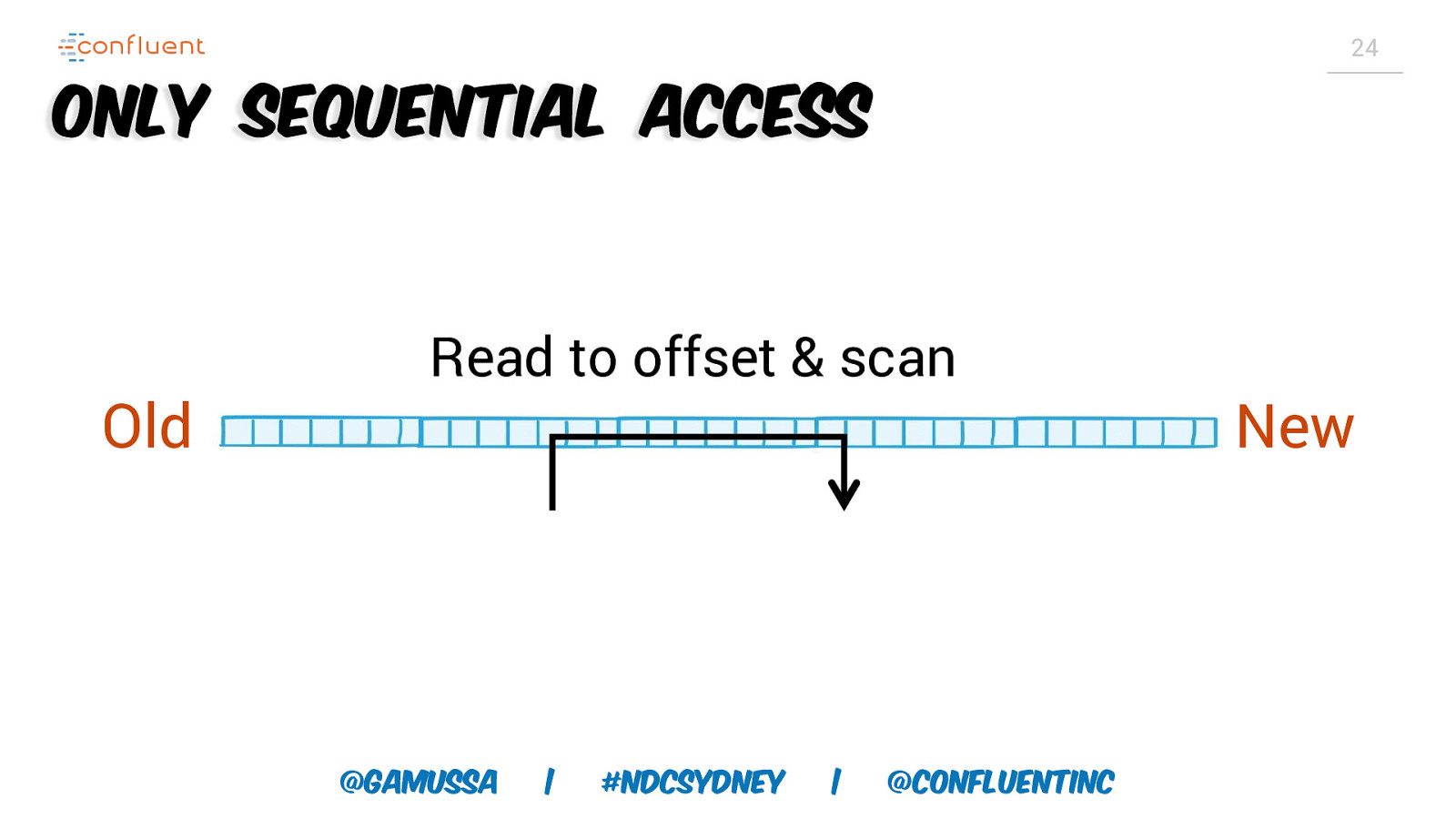
24 Only Sequential Access Old Read to offset & scan @gamussa | #NDCSydney | @ConfluentINc New

CONSUMERS CONSUMER GROUP COORDINATOR CONSUMER GROUP
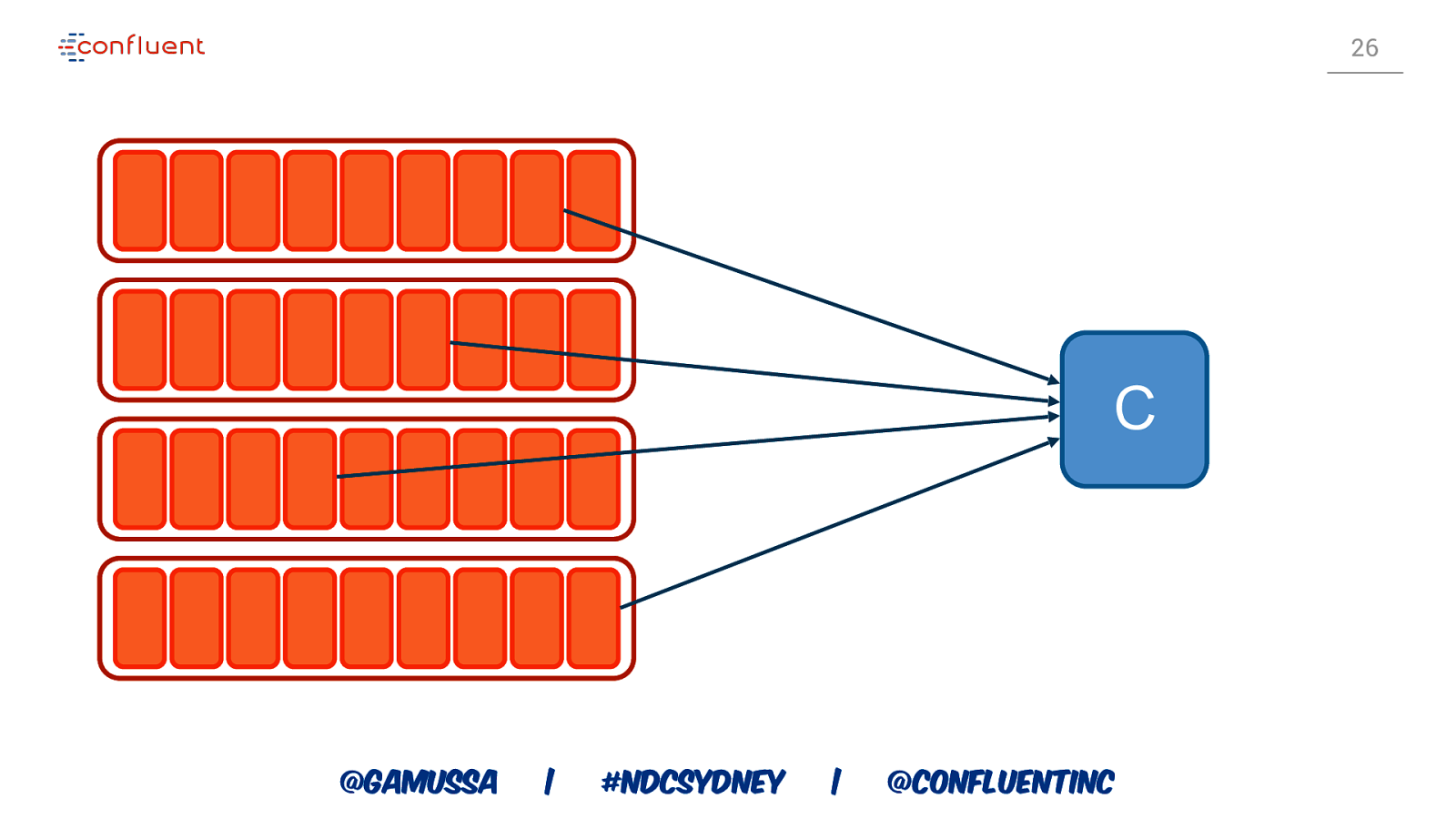
26 C @gamussa | #NDCSydney | @ConfluentINc
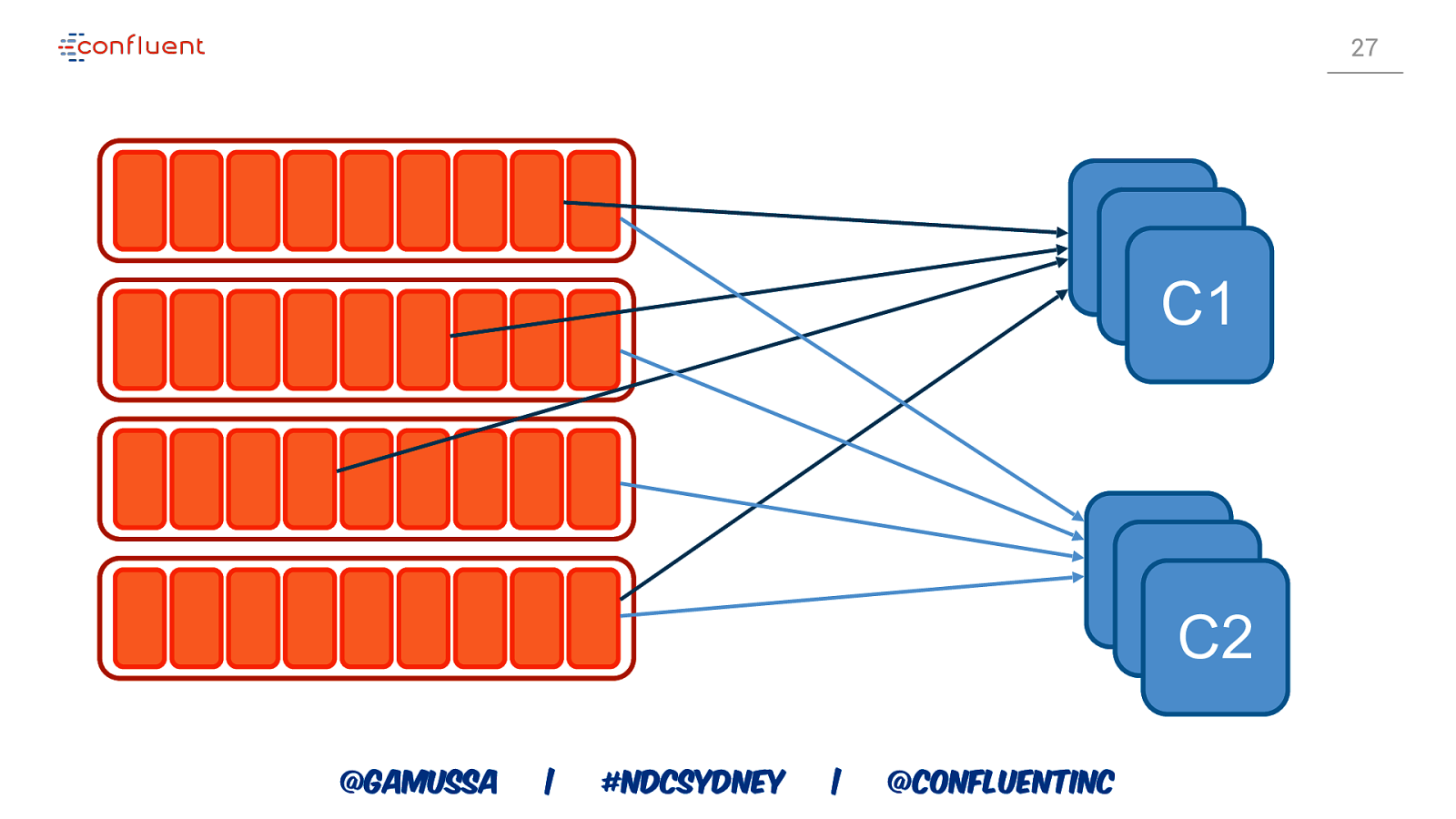
27 CC C1 CC C2 @gamussa | #NDCSydney | @ConfluentINc
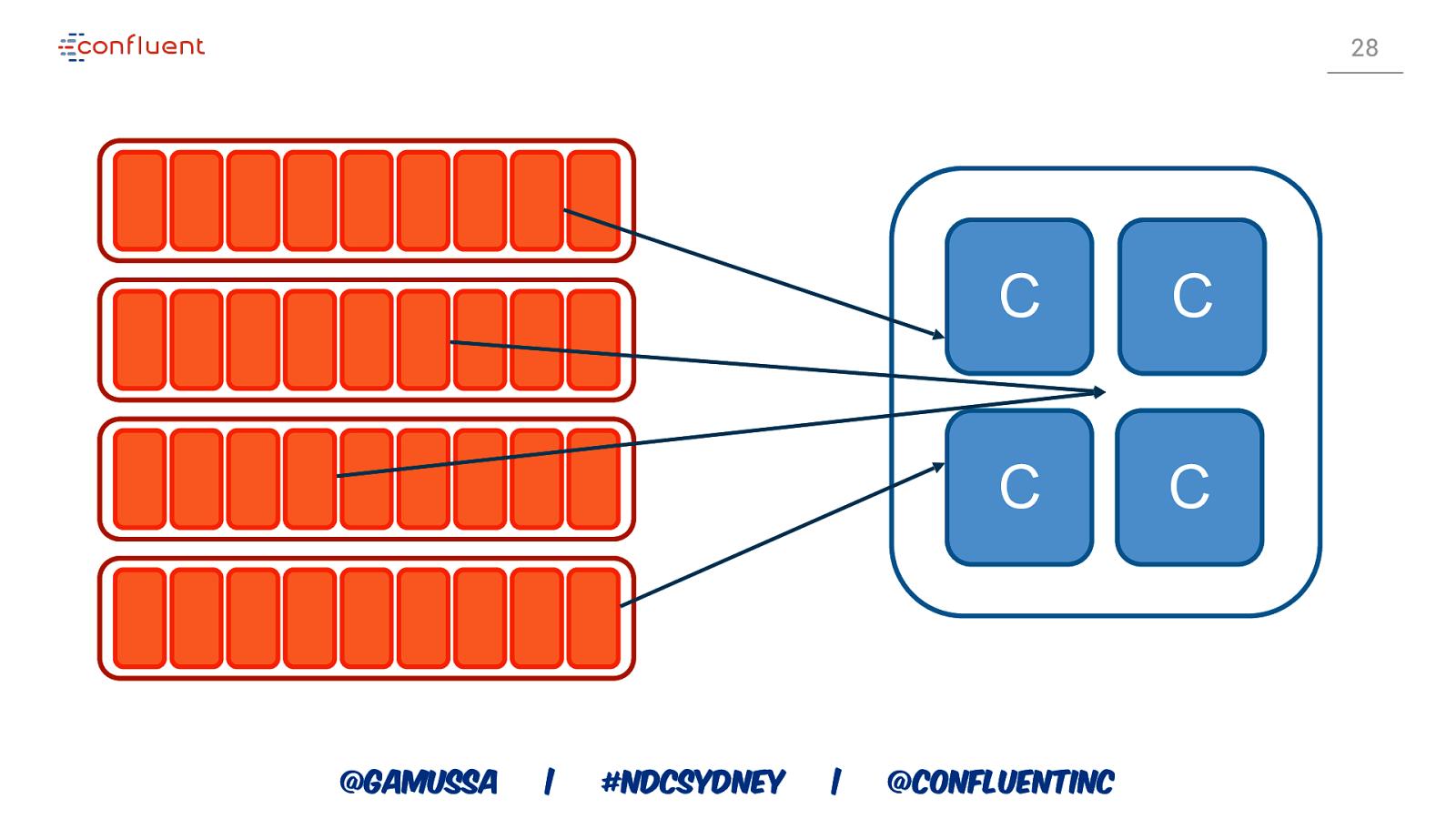
28 @gamussa | #NDCSydney | C C C C @ConfluentINc
29 @gamussa | #NDCSydney | 0 1 2 3 @ConfluentINc
30 @gamussa | #NDCSydney | 0 1 2 3 @ConfluentINc
31 @gamussa | #NDCSydney | 0, 3 1 2 3 @ConfluentINc
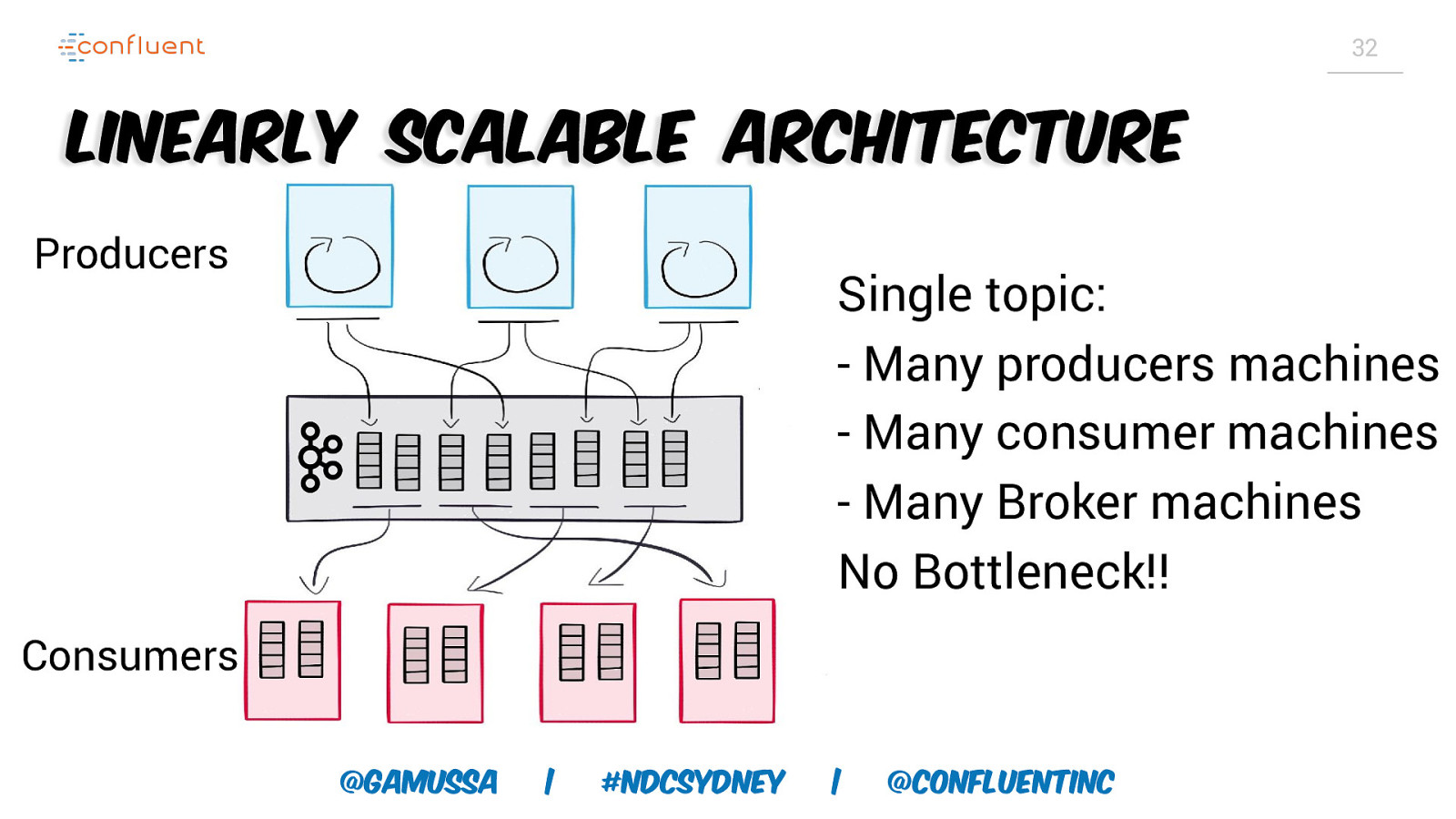
32 Linearly Scalable Architecture Producers Single topic: - Many producers machines - Many consumer machines - Many Broker machines No Bottleneck!! Consumers @gamussa | #NDCSydney | @ConfluentINc
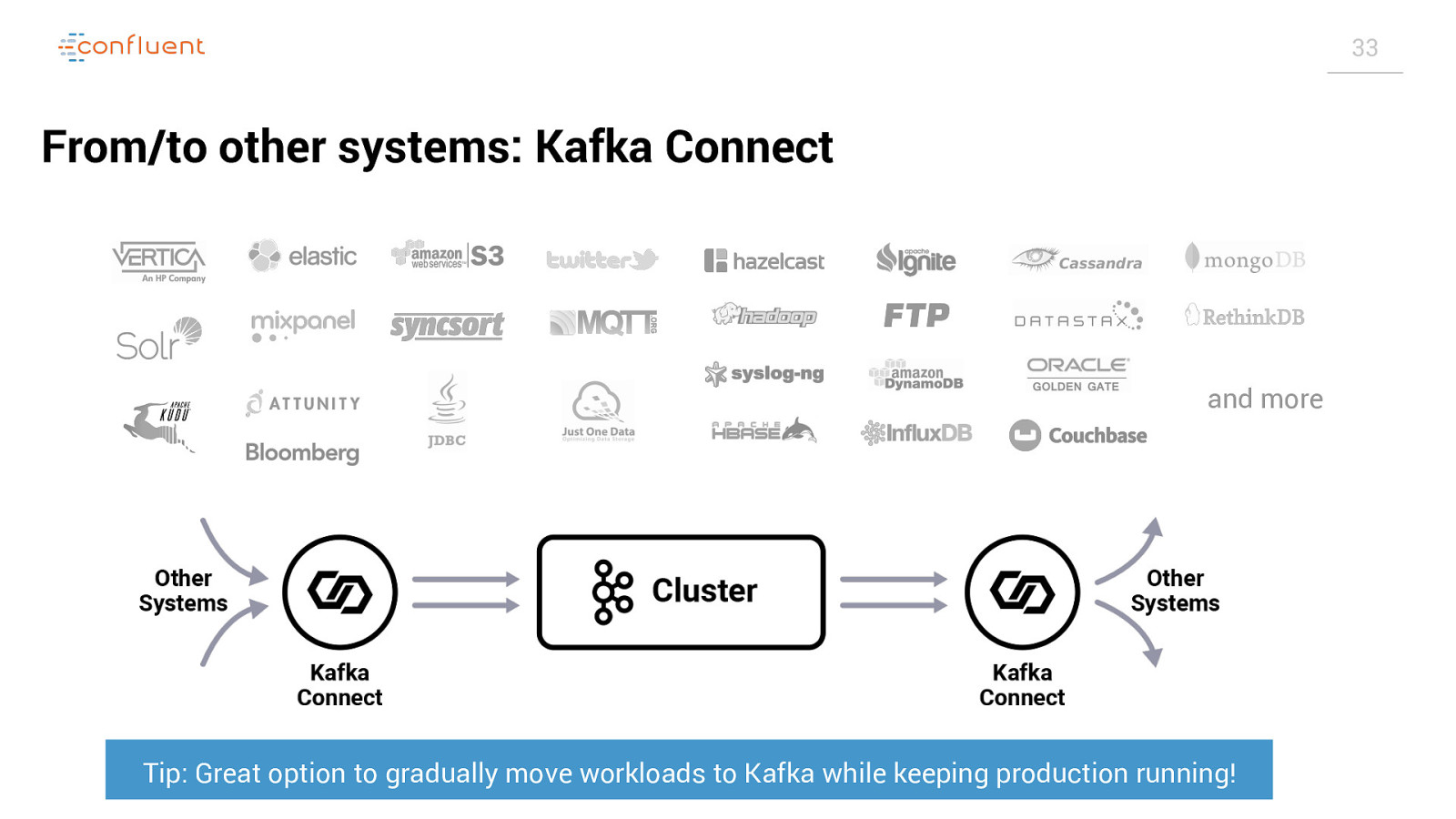
33 From/to other systems: Kafka Connect and more Tip: Great option to gradually move workloads to Kafka while keeping production running!
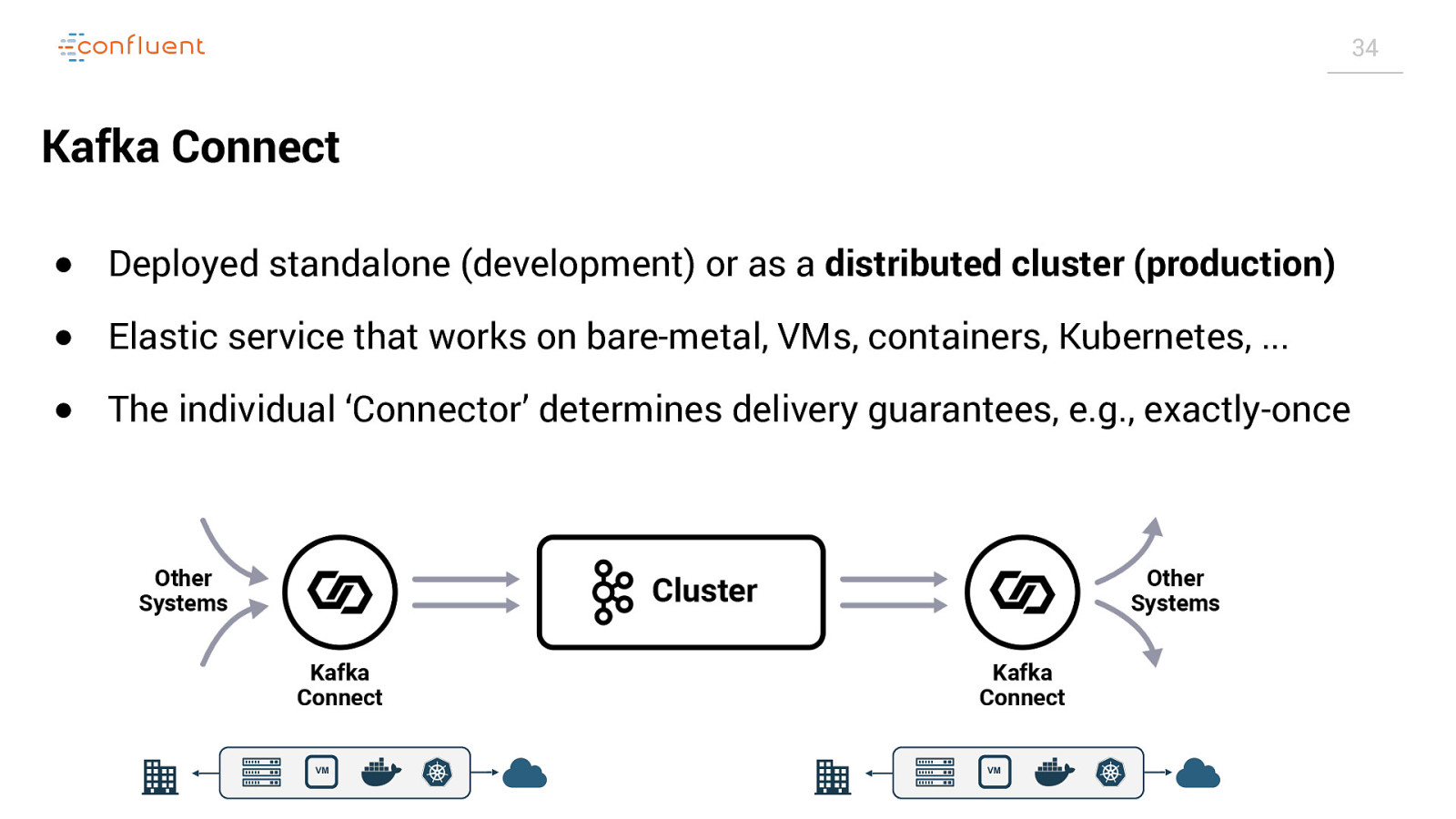
34 Kafka Connect ● Deployed standalone (development) or as a distributed cluster (production) ● Elastic service that works on bare-metal, VMs, containers, Kubernetes, … ● The individual ‘Connector’ determines delivery guarantees, e.g., exactly-once VM VM
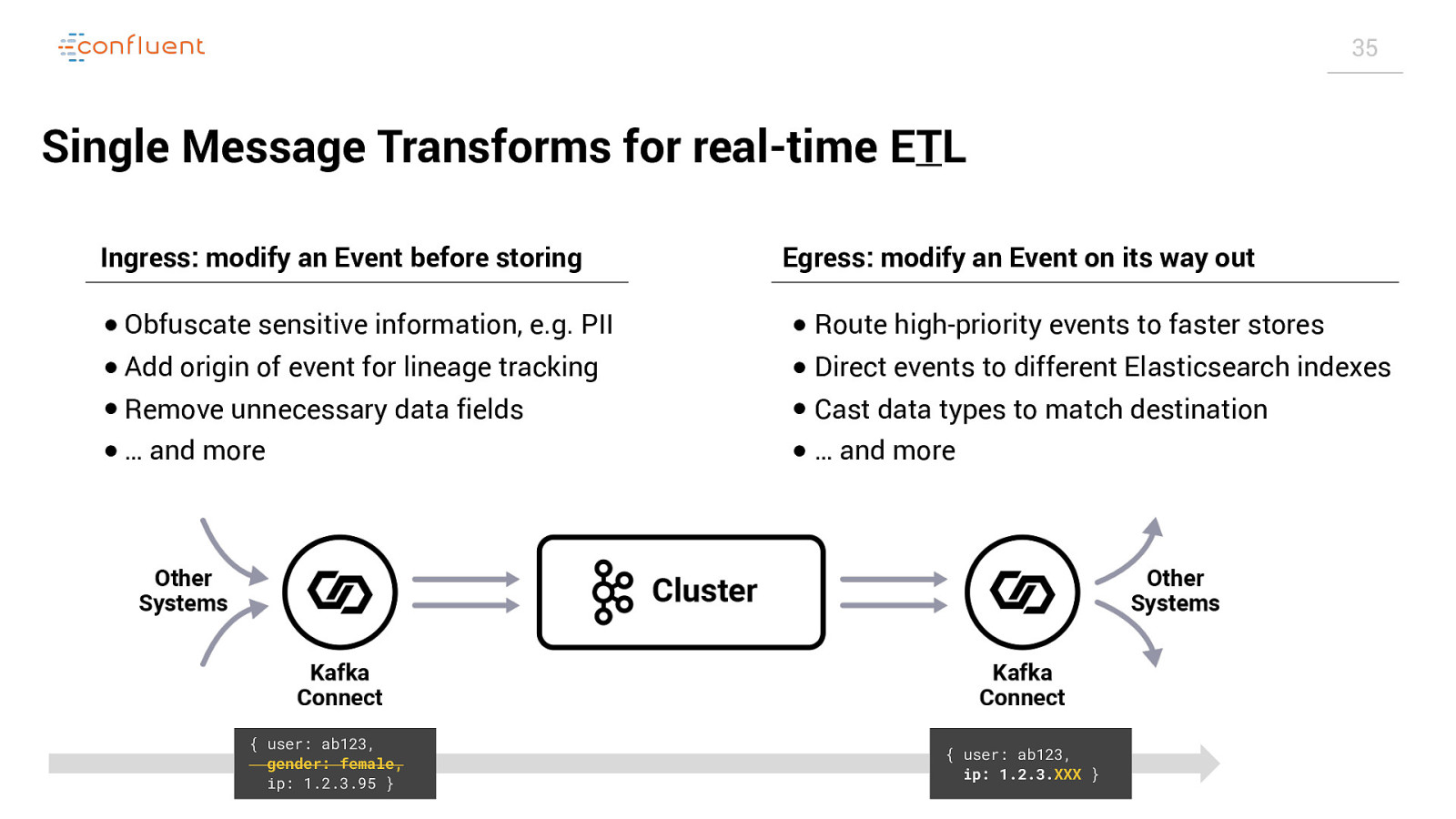
35 Single Message Transforms for real-time ETL Ingress: modify an Event before storing Egress: modify an Event on its way out ● Obfuscate sensitive information, e.g. PII ● Route high-priority events to faster stores ● Add origin of event for lineage tracking ● Remove unnecessary data fields ● Direct events to different Elasticsearch indexes ● Cast data types to match destination ● … and more ● … and more { user: ab123, gender: female, ip: 1.2.3.95 } { user: ab123, ip: 1.2.3.XXX }
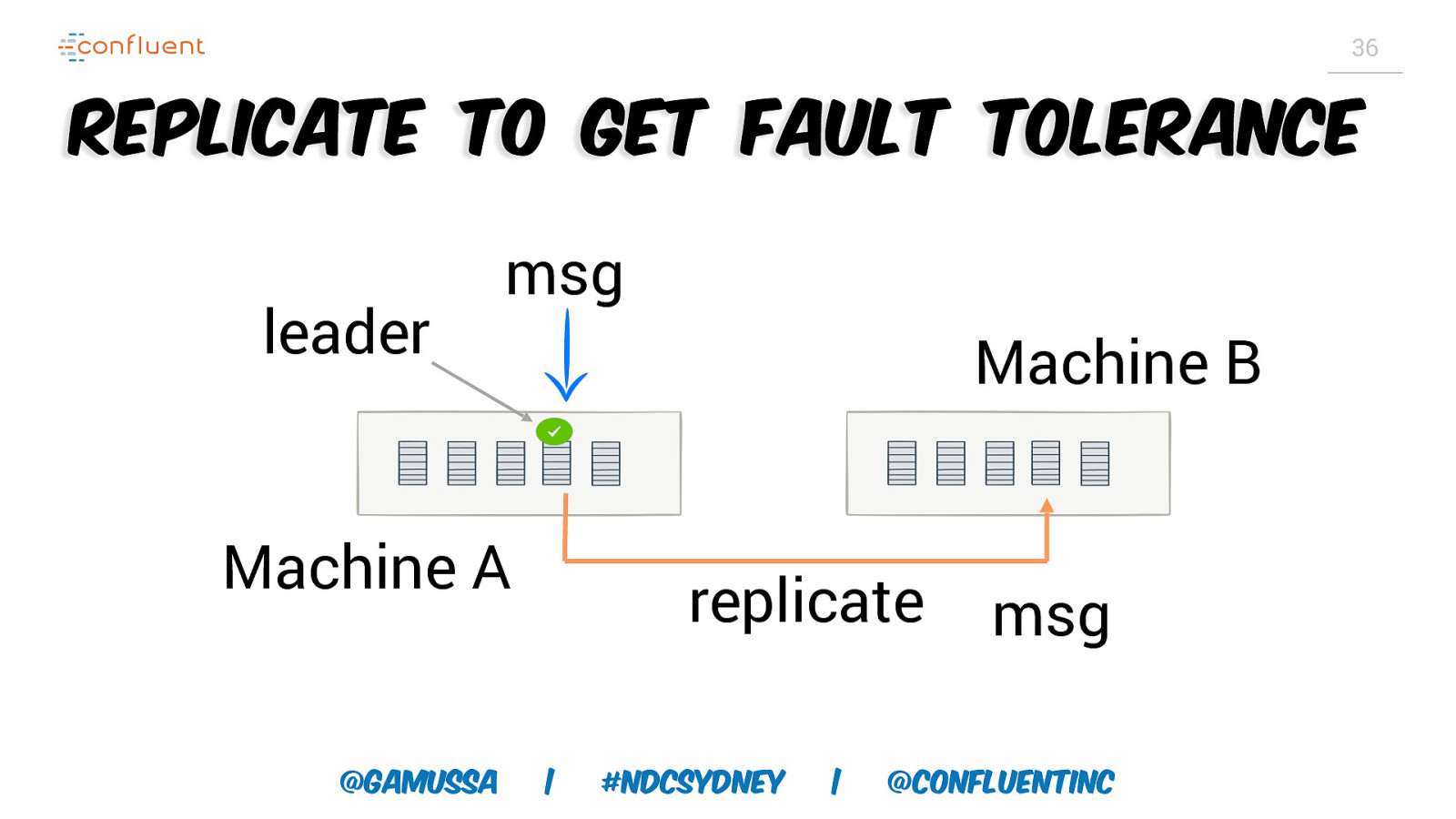
36 Replicate to get fault tolerance leader msg Machine B Machine A @gamussa replicate | #NDCSydney | msg @ConfluentINc
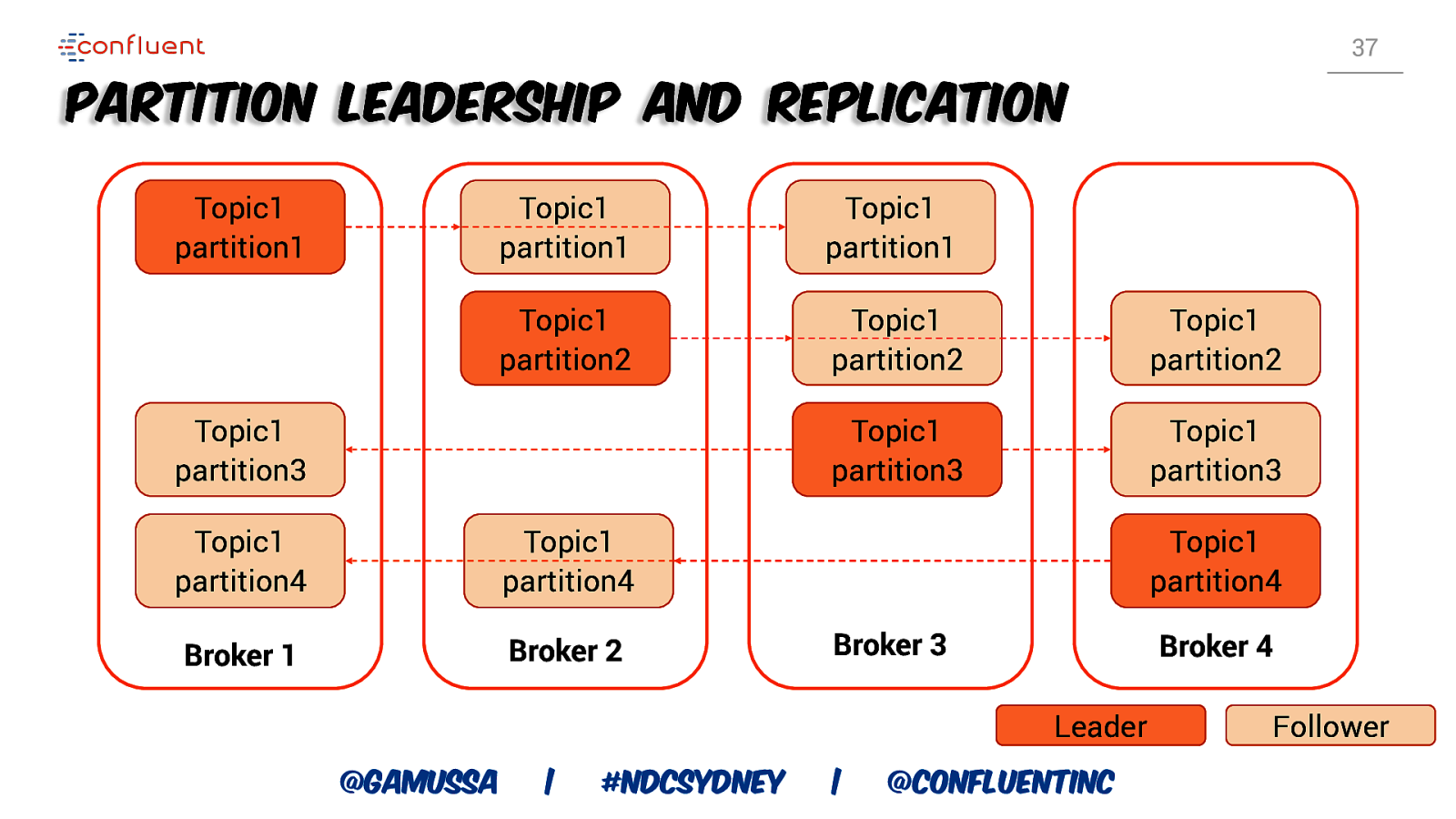
37 Partition Leadership and Replication Topic1 partition1 Topic1 partition1 Topic1 partition1 Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4 Broker 1 Broker 2 Topic1 partition4 Broker 3 Broker 4 Leader @gamussa | #NDCSydney | @ConfluentINc Follower
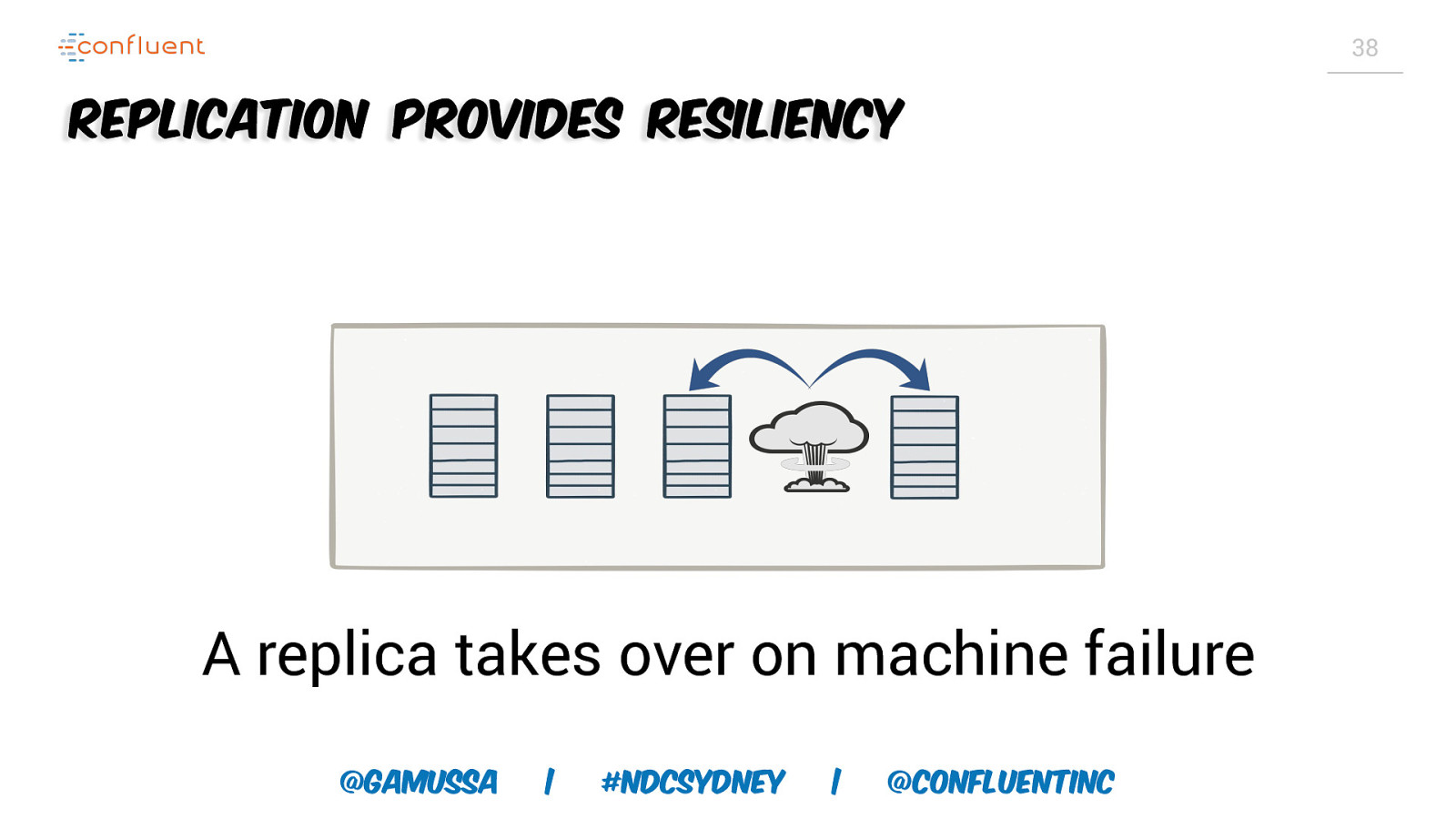
38 Replication provides resiliency A replica takes over on machine failure @gamussa | #NDCSydney | @ConfluentINc
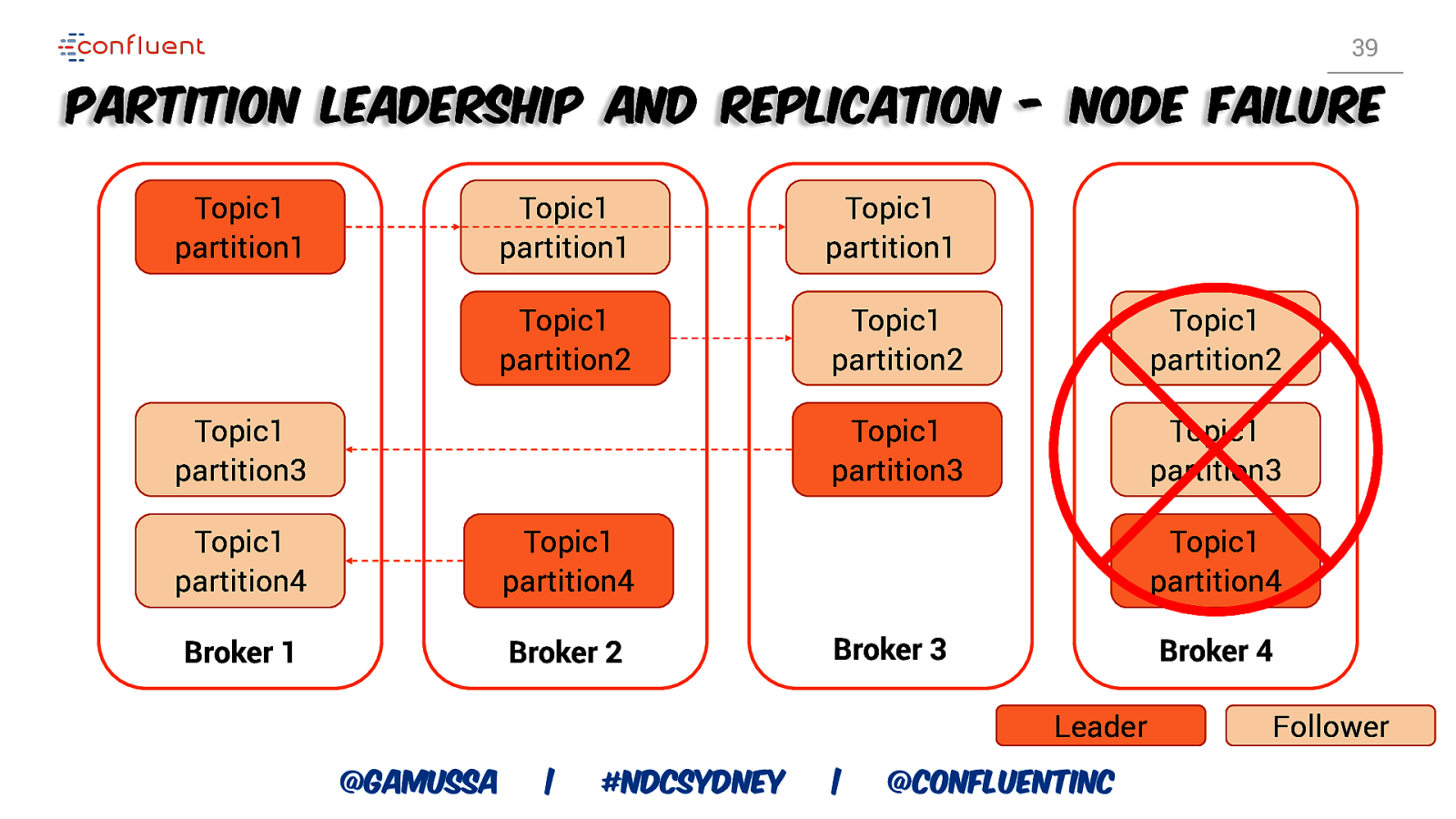
39 Partition Leadership and Replication - node failure Topic1 partition1 Topic1 partition1 Topic1 partition1 Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4 Broker 1 Broker 2 Topic1 partition4 Broker 3 Broker 4 Leader @gamussa | #NDCSydney | @ConfluentINc Follower

40 The log is a type of durable messaging system Similar to a traditional messaging system (ActiveMQ, Rabbit etc) but with: (a) Far better scalability (b) Built in fault tolerance / HA (c) Storage

Stop! Demo time! @gamussa | #NDCSydney | @ConfluentINc

42 Processing @gamussa | #NDCSydney | @ConfluentINc

43 Streaming is the toolset for dealing with events as they move! @gamussa | #NDCSydney | @ConfluentINc
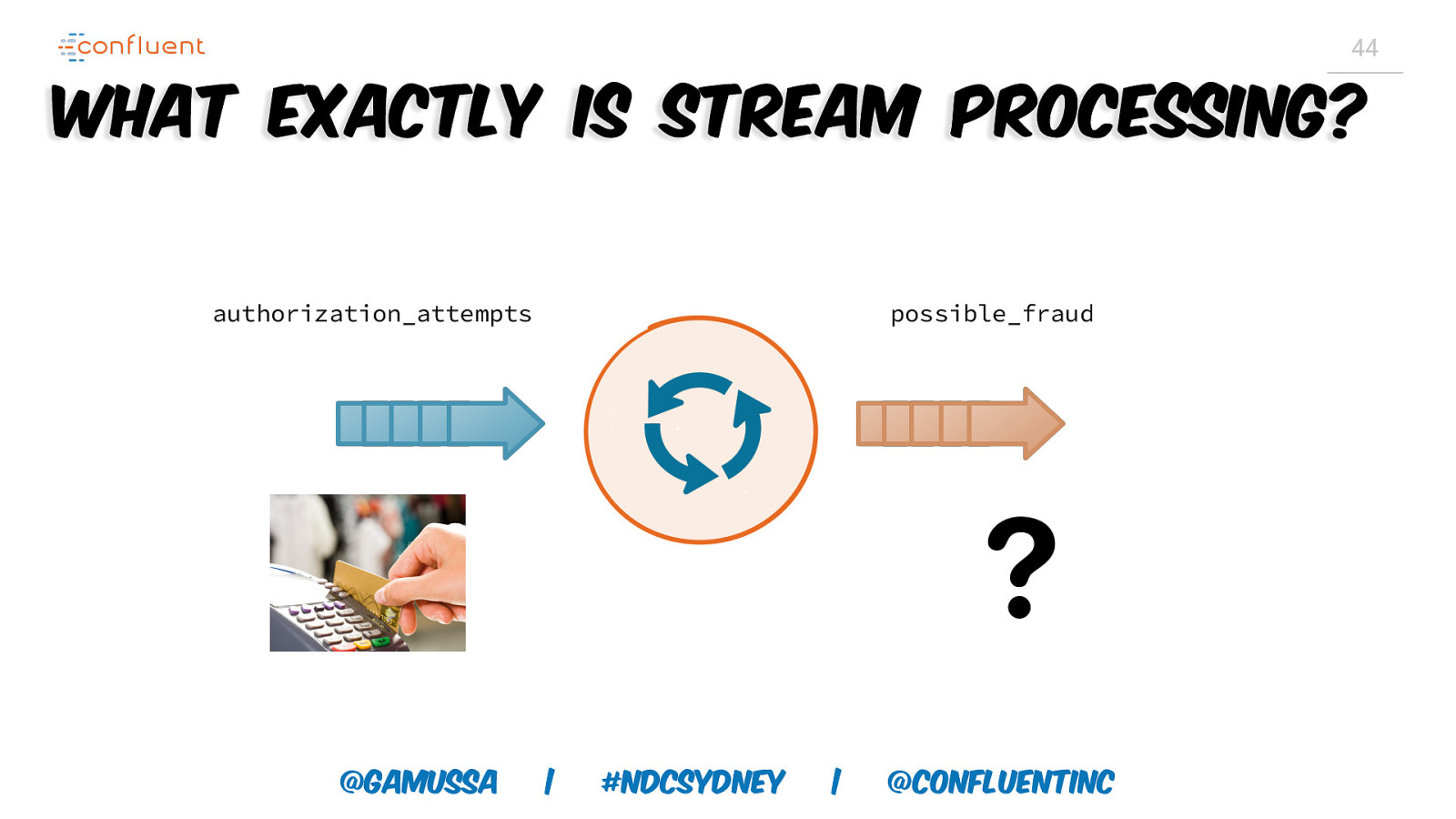
44 What exactly is Stream Processing? authorization_attempts @gamussa possible_fraud | #NDCSydney | @ConfluentINc

45 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc

46 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc

47 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc

48 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc

49 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc

50 What exactly is Stream Processing? possible_fraud authorization_attempts CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; @gamussa | #NDCSydney | @ConfluentINc
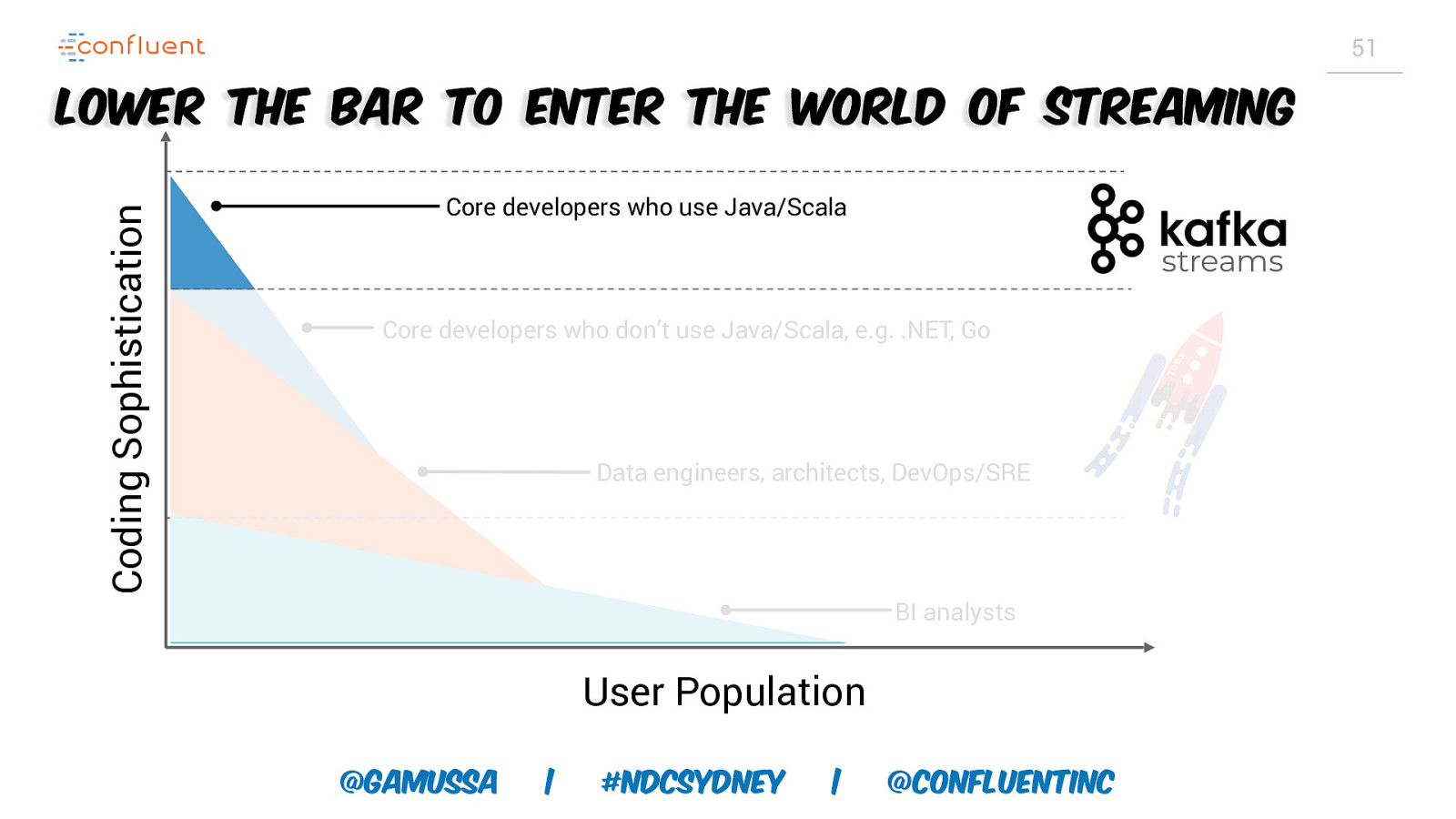
51 Coding Sophistication Lower the bar to enter the world of streaming Core developers who use Java/Scala streams Core developers who don’t use Java/Scala, e.g. .NET, Go Data engineers, architects, DevOps/SRE BI analysts User Population @gamussa | #NDCSydney | @ConfluentINc
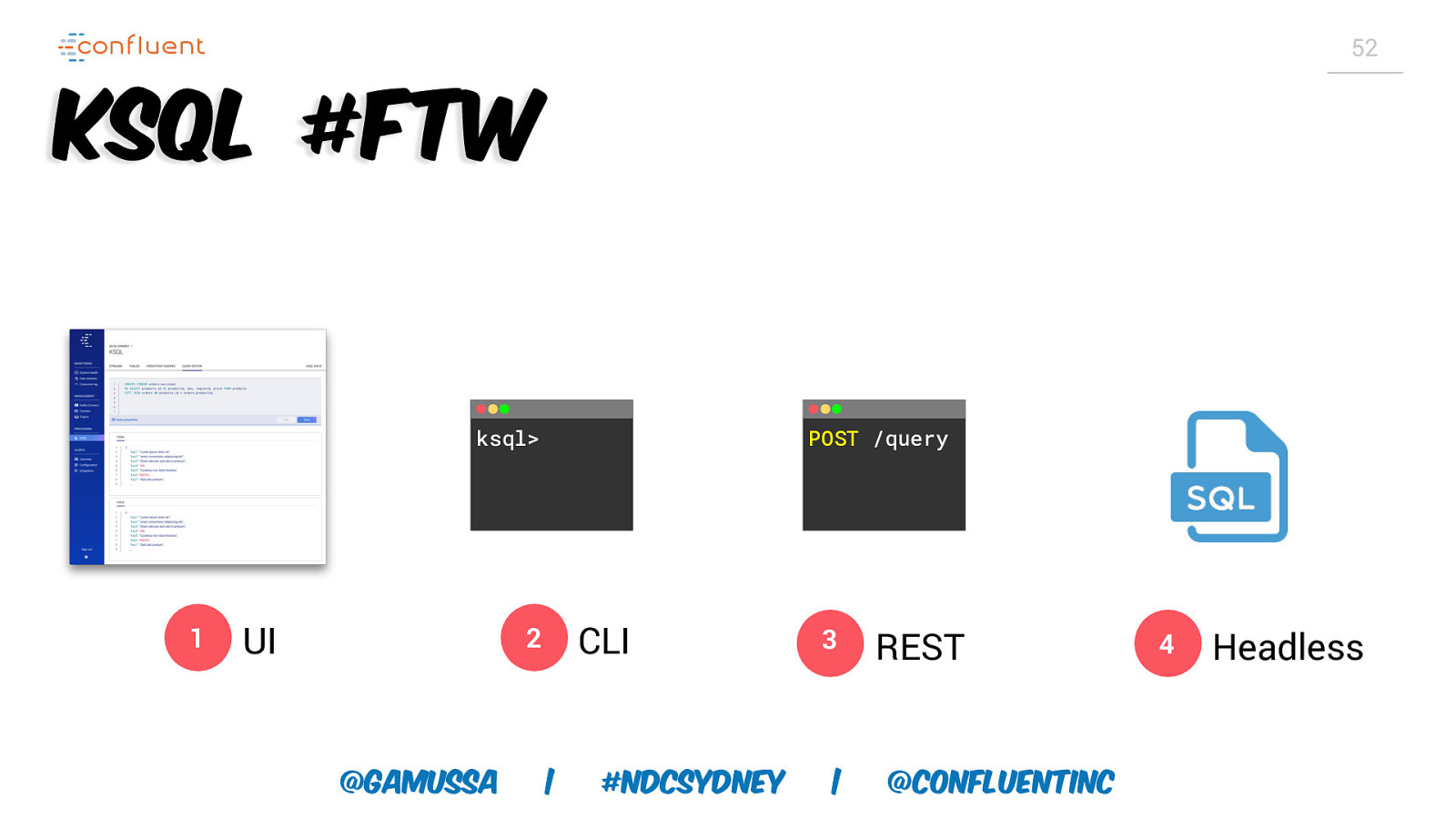
52 KSQL #FTW ksql> 1 UI POST /query CLI 2 @gamussa | #NDCSydney 3 | REST @ConfluentINc 4 Headless
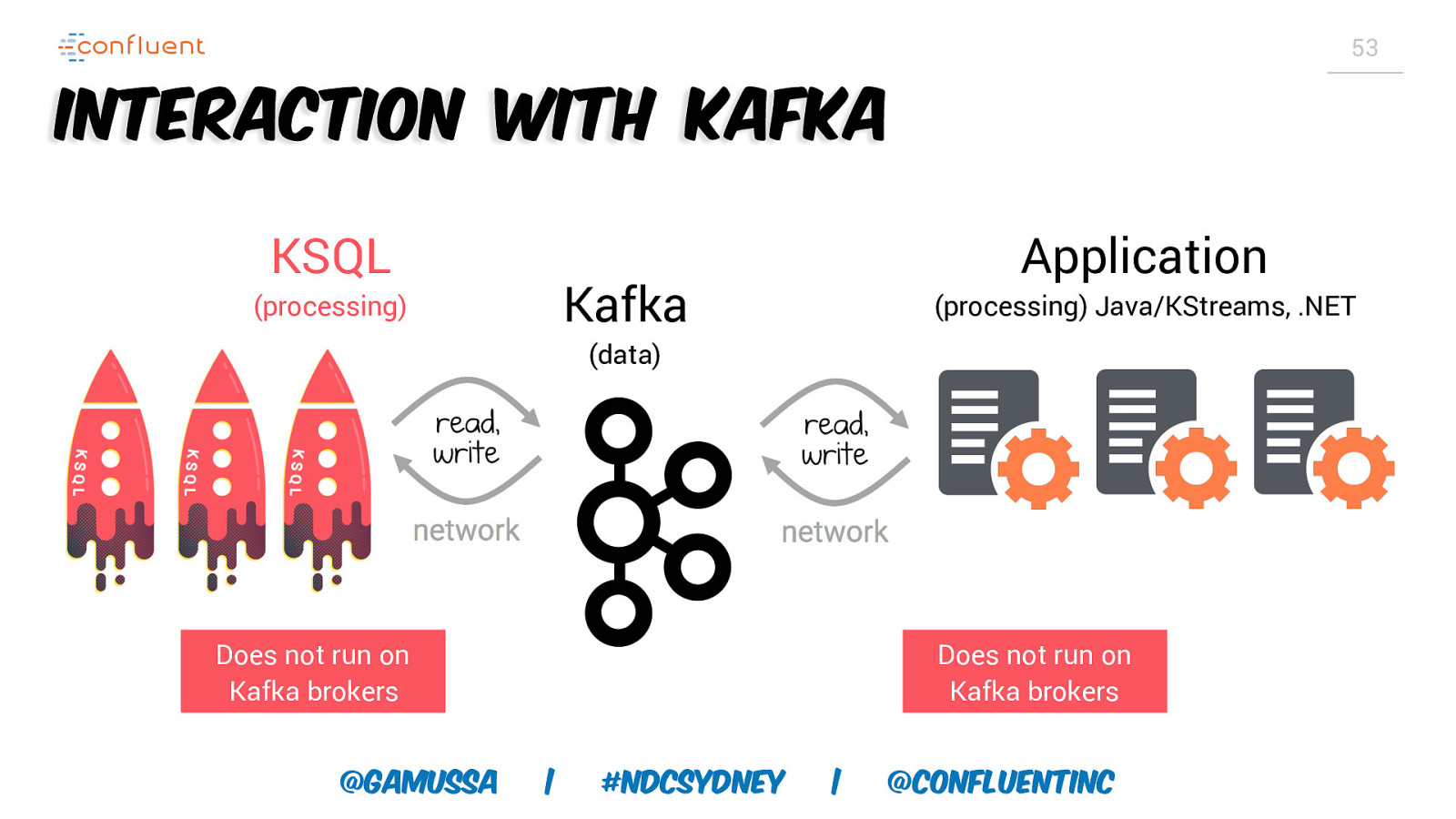
53 Interaction with Kafka KSQL Application Kafka (processing) (processing) Java/KStreams, .NET (data) Does not run on Kafka brokers @gamussa Does not run on Kafka brokers | #NDCSydney | @ConfluentINc

54 Find your local Meetup Group https://cnfl.io/kafka-meetups Grab Stream Processing books https://cnfl.io/book-bundle Join us in Slack http://cnfl.io/slack @gamussa | #NDCSydney | @ConfluentINc

55 One More Thing…

56 https://gamov.dev/sydney-meetup

Thanks! @gamussa viktor@confluent.io @gamussa | @ #NDCSydney | @ConfluentINc

When it comes time to choose a distributed messaging system, everyone knows the answer: Apache Kafka. But how about when you’re on the hook to choose a world-class, horizontally scalable stream data processing system? When you need not just publish and subscribe messaging, but also long-term storage, a flexible integration framework, and a means of deploying real-time stream processing applications at scale without having to integrate many different pieces of infrastructure yourself? The answer is still Apache Kafka.
In this talk, Viktor will give a rapid-fire review of the breadth of Kafka as a streaming data platform. You’ll see its internal architecture, including how it partitions messaging workloads in a fault-tolerant way, and how it provides message durability. Viktor will explain Kafka’s approach to pub/sub messaging and how the Confluent .NET client offers a framework for computation over streaming data.
Video
Code
The following code examples from the presentation can be tried out live.
Resources
The following resources were mentioned during the presentation or are useful additional information.
-
Kubernetes demo setup
confluent platform demo setup + twitter connector and ksql
-
Confluent Kafka Dotnet client
Buzz and feedback
Here’s what was said about this presentation on social media.