Streaming ETL in Practice with PostgreSQL, Apache Kafka, and KSQL
A presentation at Postgresconf NYC in in New York, NY, USA by Viktor Gamov

@gamussa #Postgres @confluentinc Streaming ETL in Practice: Build Data Pipelines without a single line of code!

@gamussa @gamussa #Postgres @confluentinc

Special Thanks! @rmoff @gamussa #Postgres @confluentinc

Raffle, yeah 🚀 must follow @gamussa @confluentinc 📸🖼🐘 Tag @gamussa With #peoplepostgresdata @gamussa #Postgres @confluentinc

@gamussa #Postgres @confluentinc

Apache Kafka is an event streaming platform @gamussa #Postgres @confluentinc

But what is An event streaming platform? @gamussa #Postgres @confluentinc
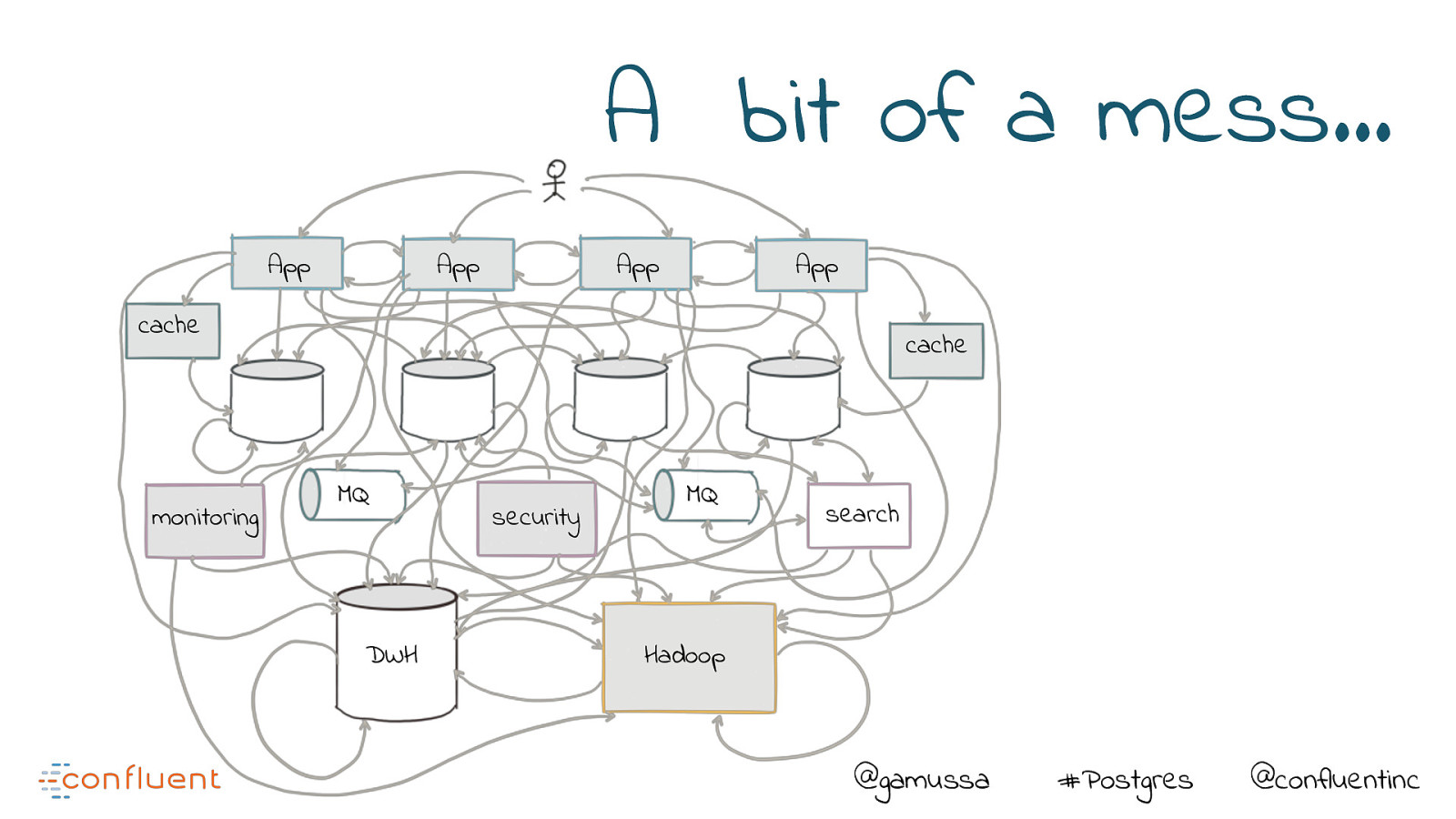
A bit of a mess… App App App App cache monitoring cache MQ DWH security MQ search Hadoop @gamussa #Postgres @confluentinc
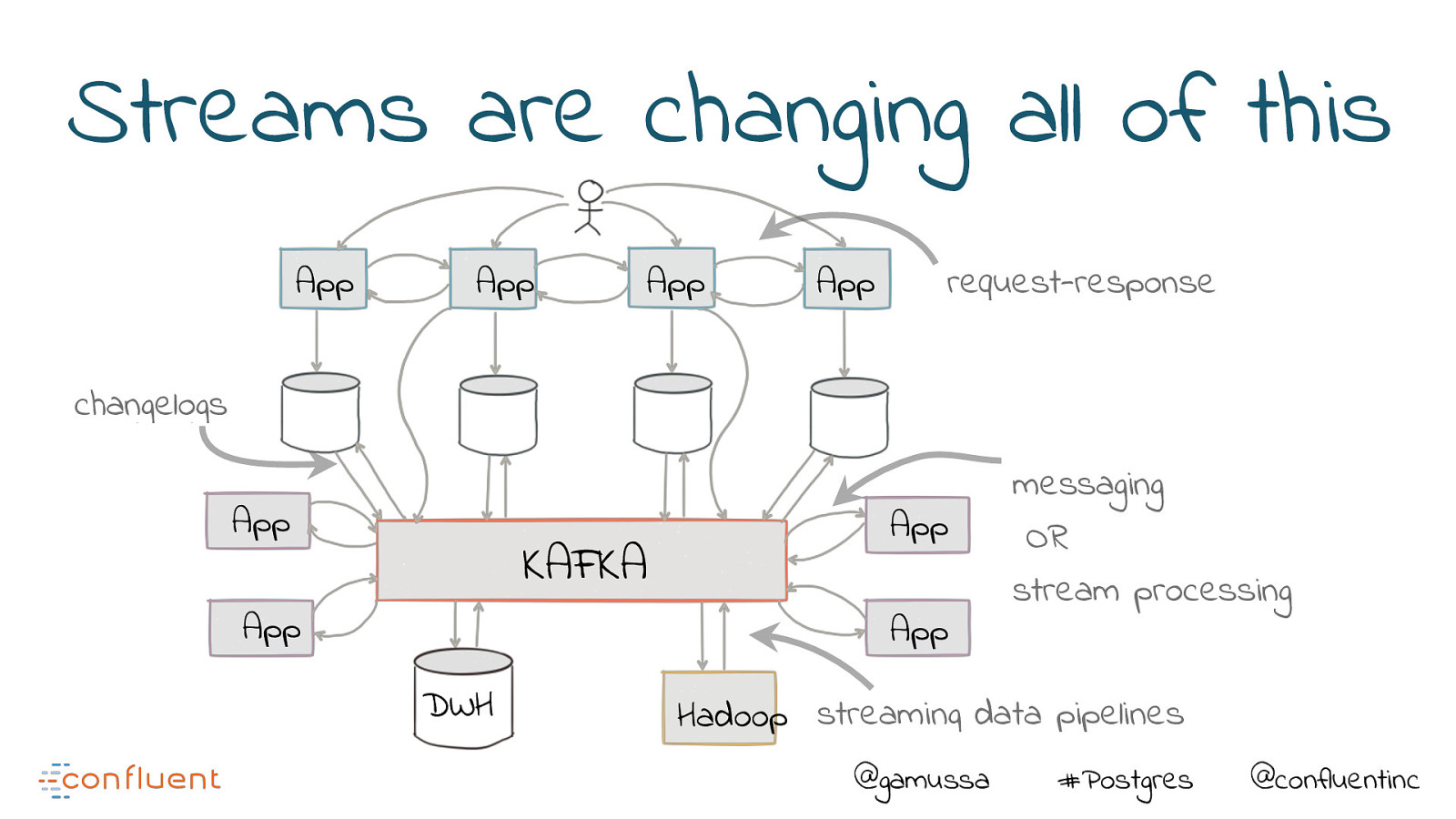
Streams are changing all of this App App App App request-response changelogs App KAFKA App App App DWH messaging OR stream processing Hadoop streaming data pipelines @gamussa #Postgres @confluentinc
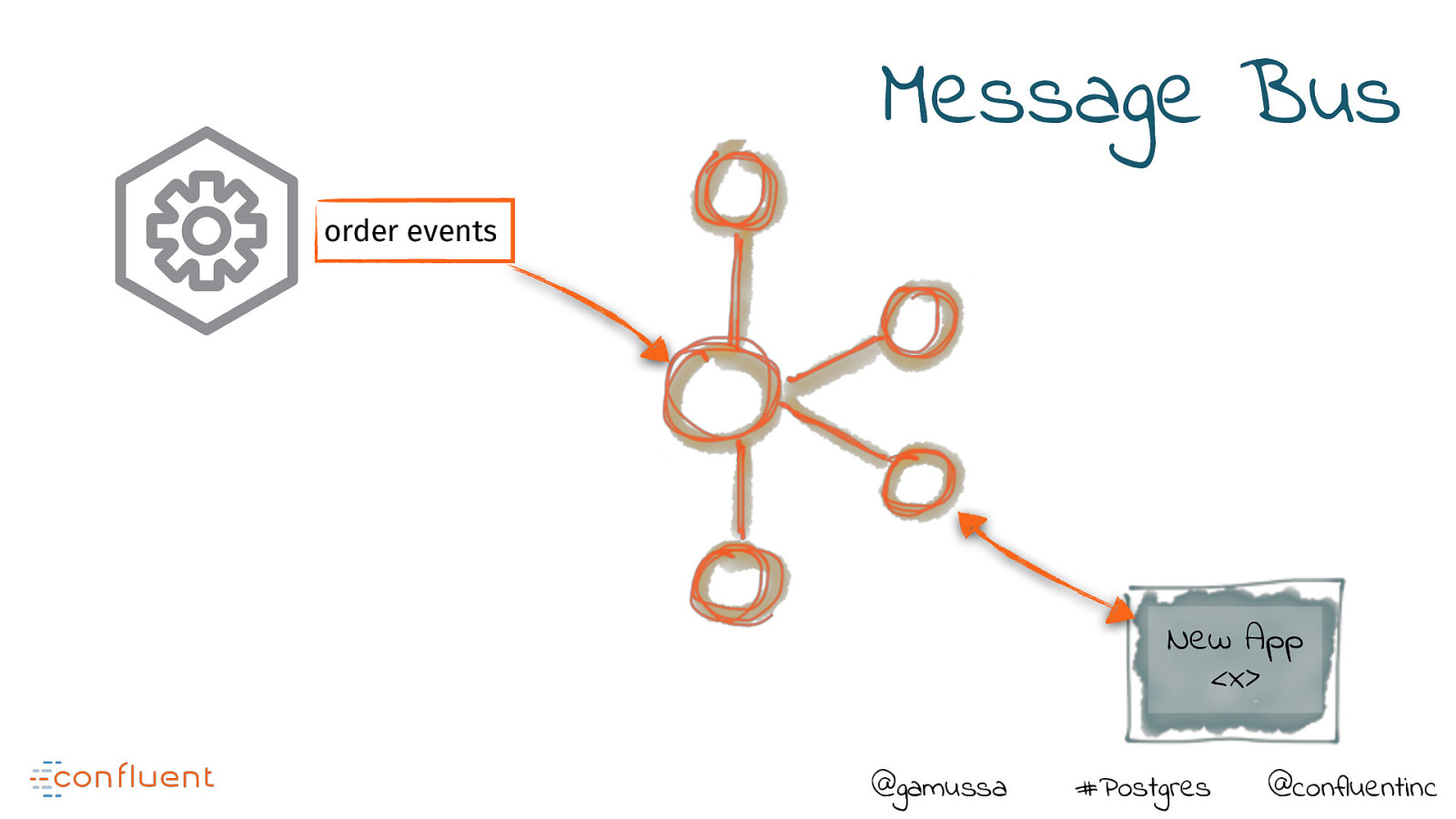
Message Bus order events New App <x> @gamussa #Postgres @confluentinc
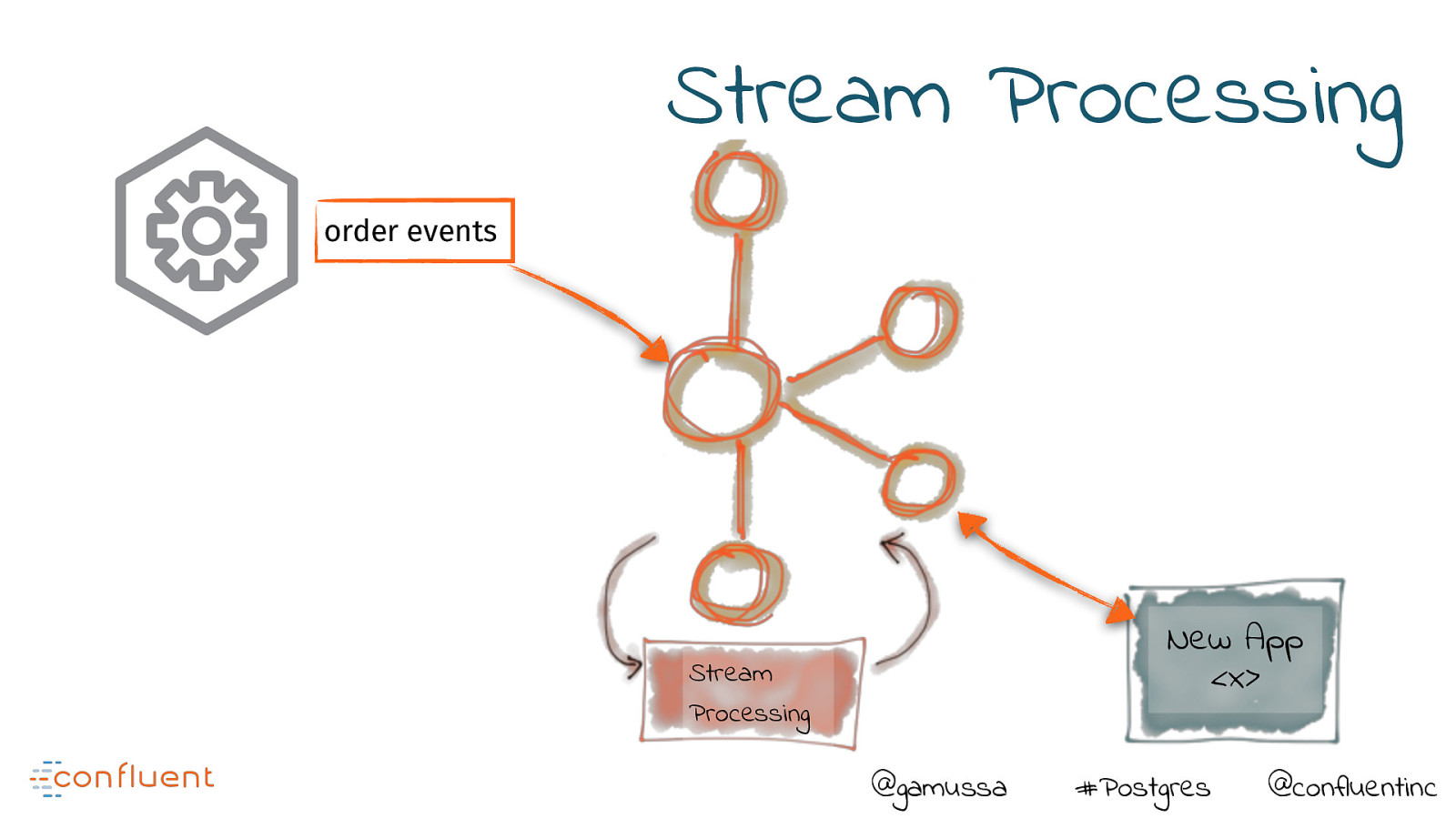
Stream Processing order events New App <x> Stream Processing @gamussa #Postgres @confluentinc
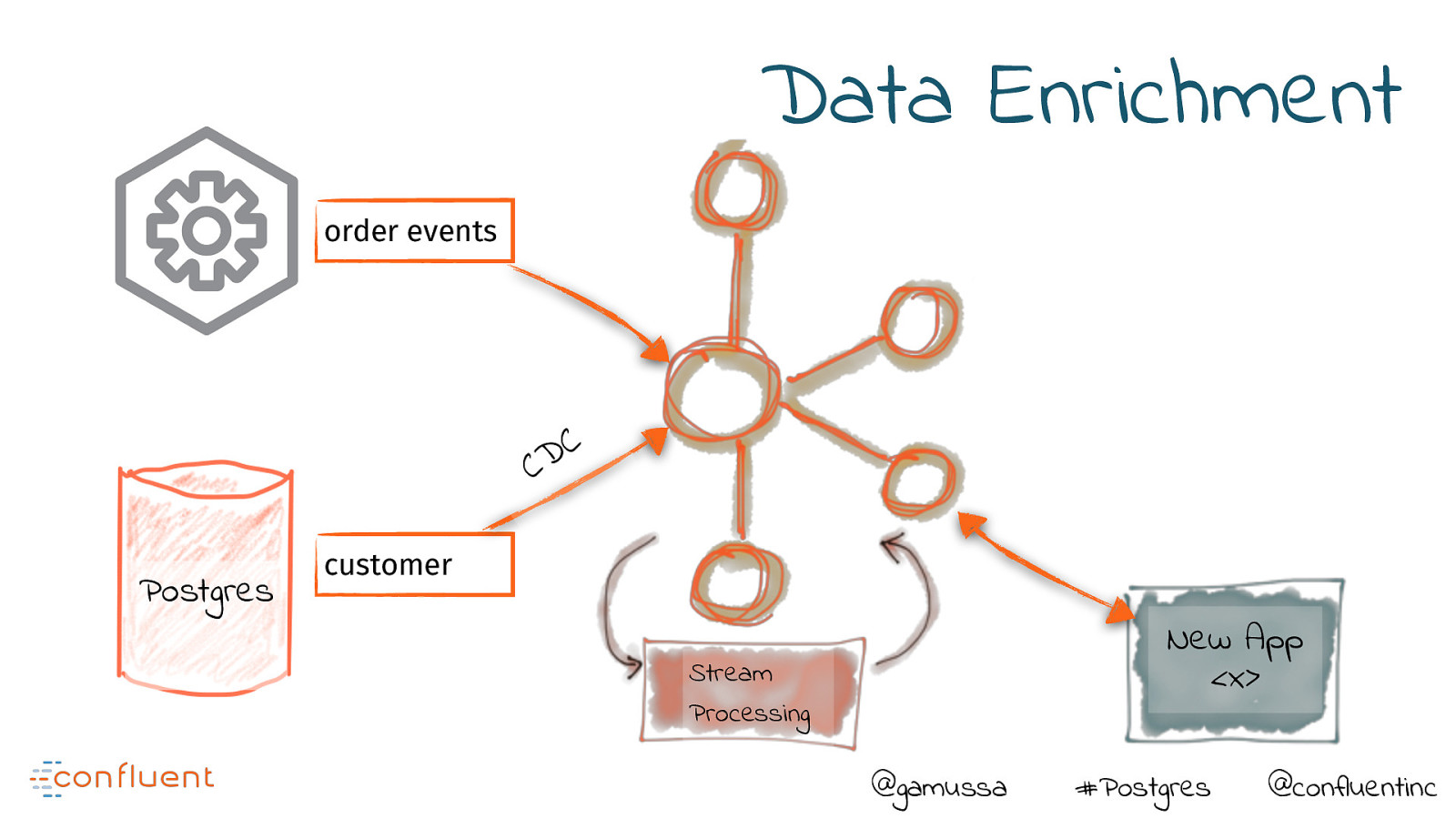
Data Enrichment order events C D C Postgres customer New App <x> Stream Processing @gamussa #Postgres @confluentinc
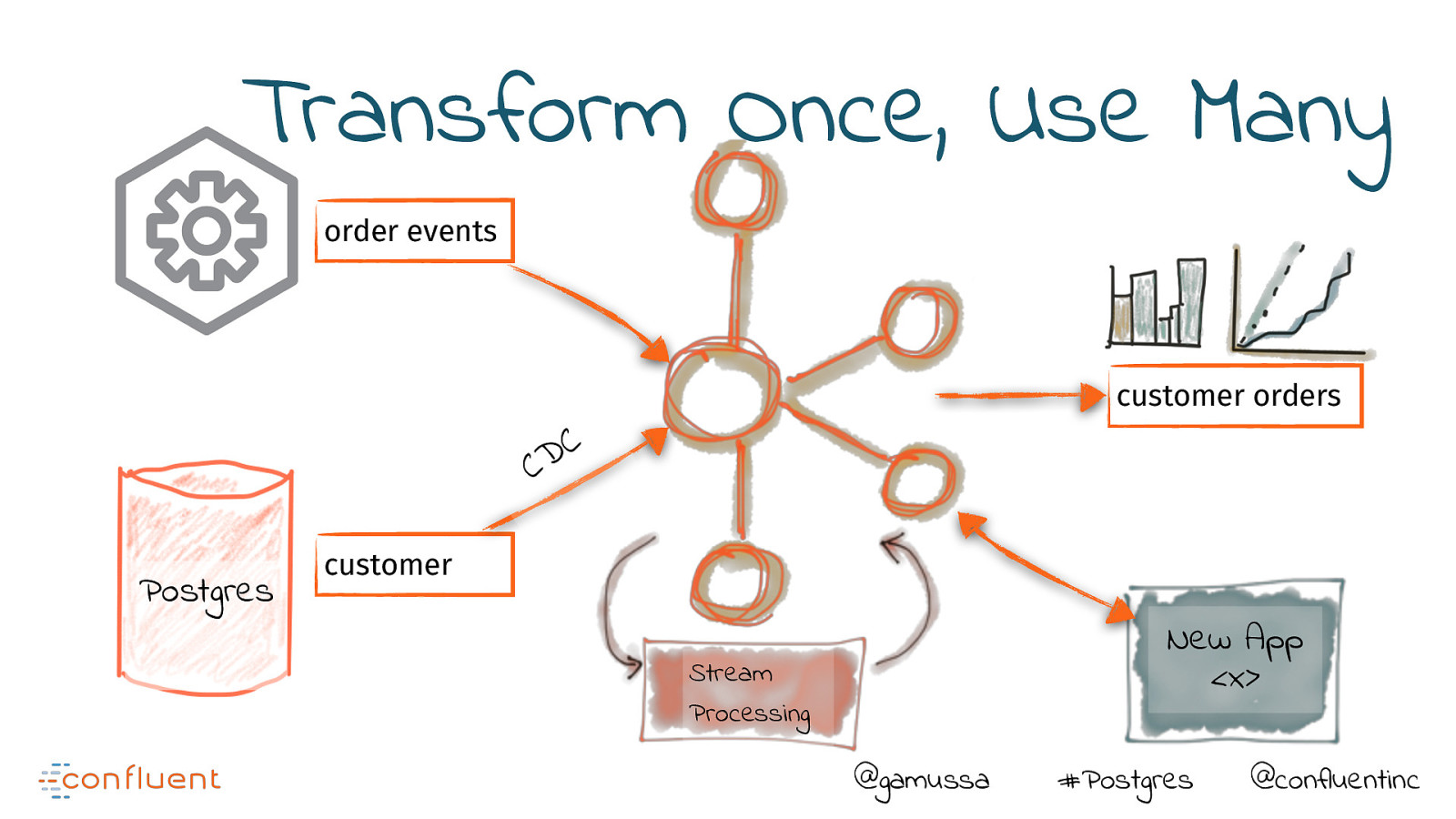
Transform Once, Use Many order events customer orders C D C Postgres customer New App <x> Stream Processing @gamussa #Postgres @confluentinc
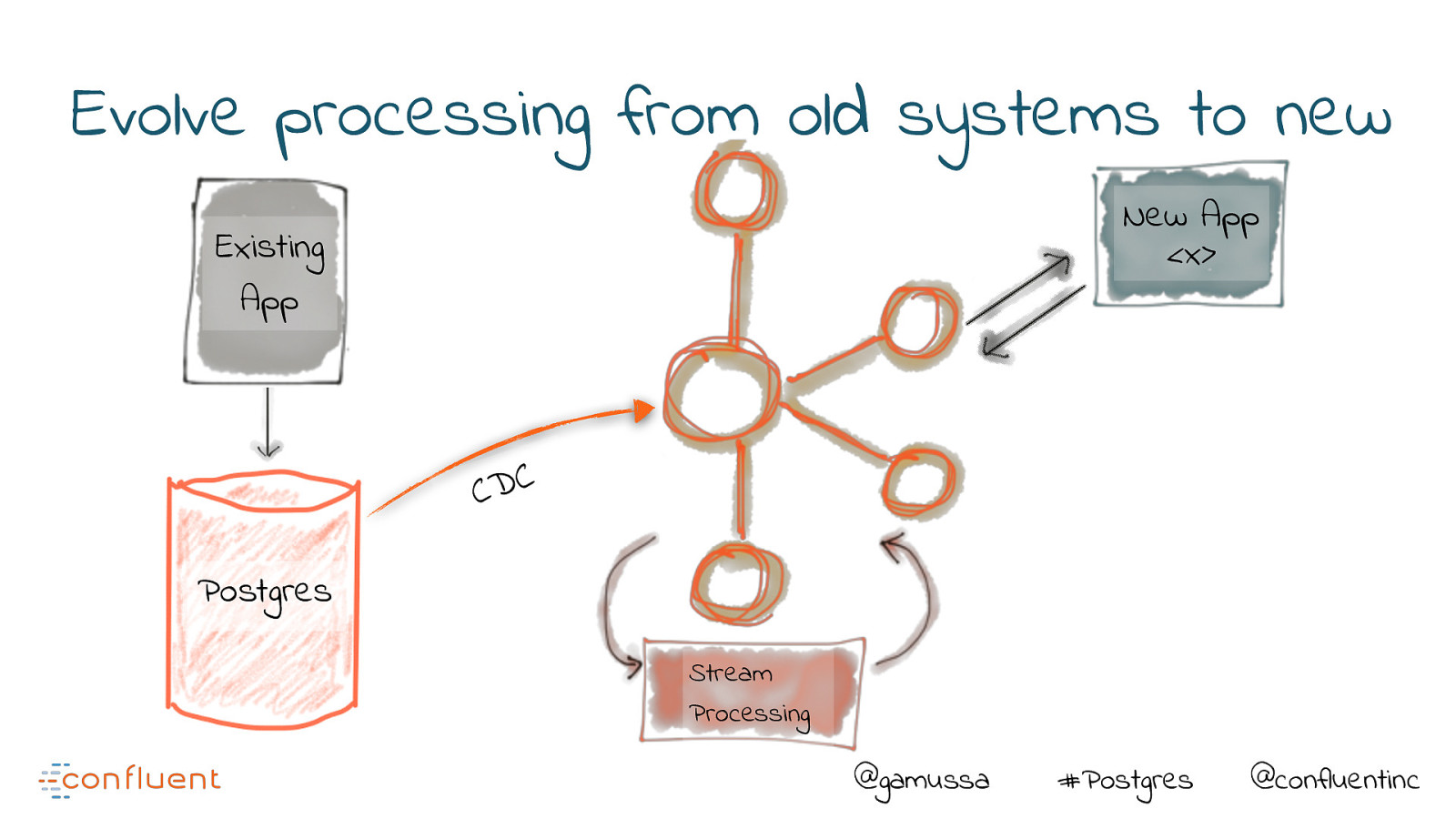
Evolve processing from old systems to new New App <x> Existing App C D C Postgres Stream Processing @gamussa #Postgres @confluentinc
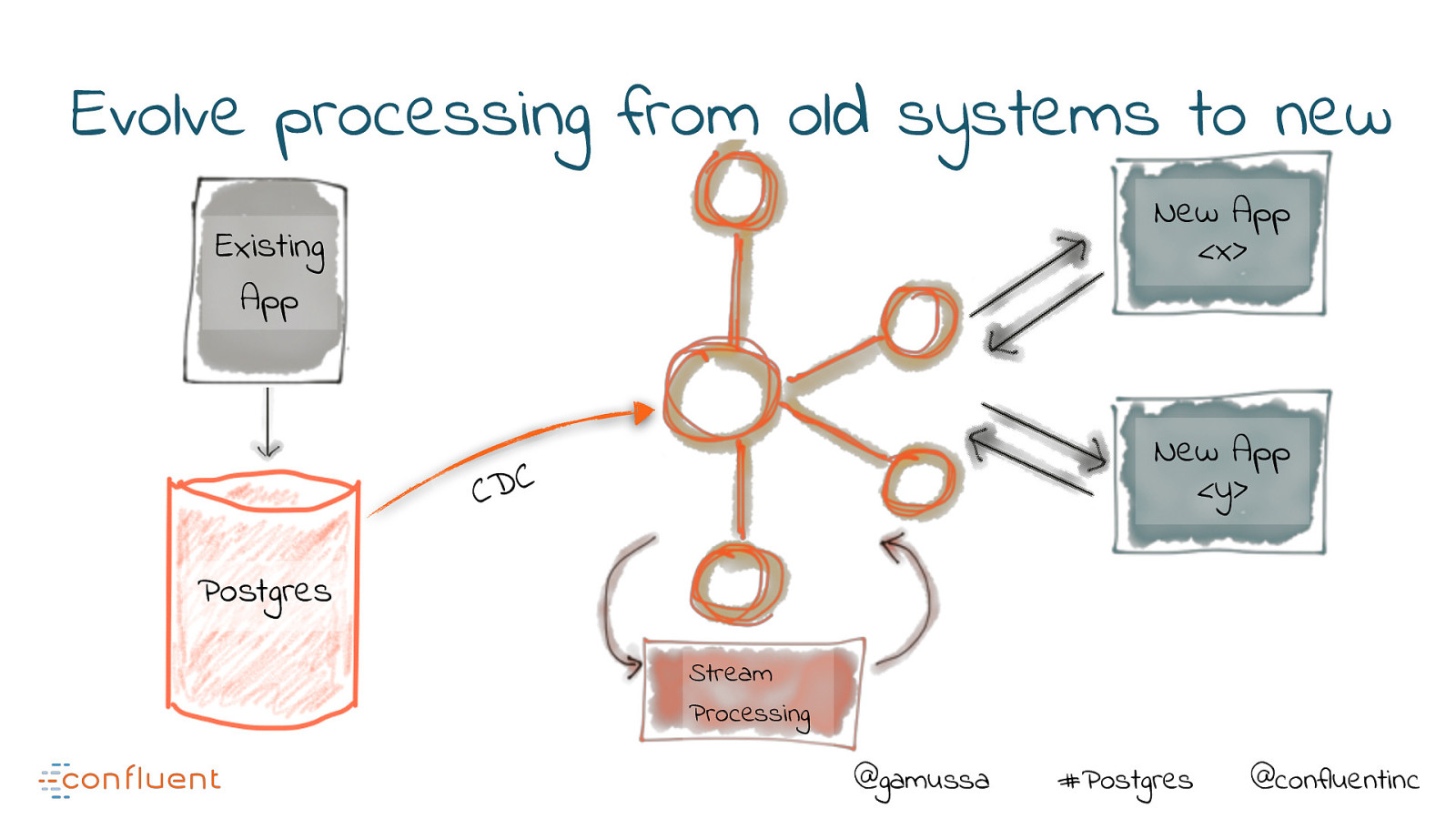
Evolve processing from old systems to new New App <x> Existing App New App <y> C D C Postgres Stream Processing @gamussa #Postgres @confluentinc
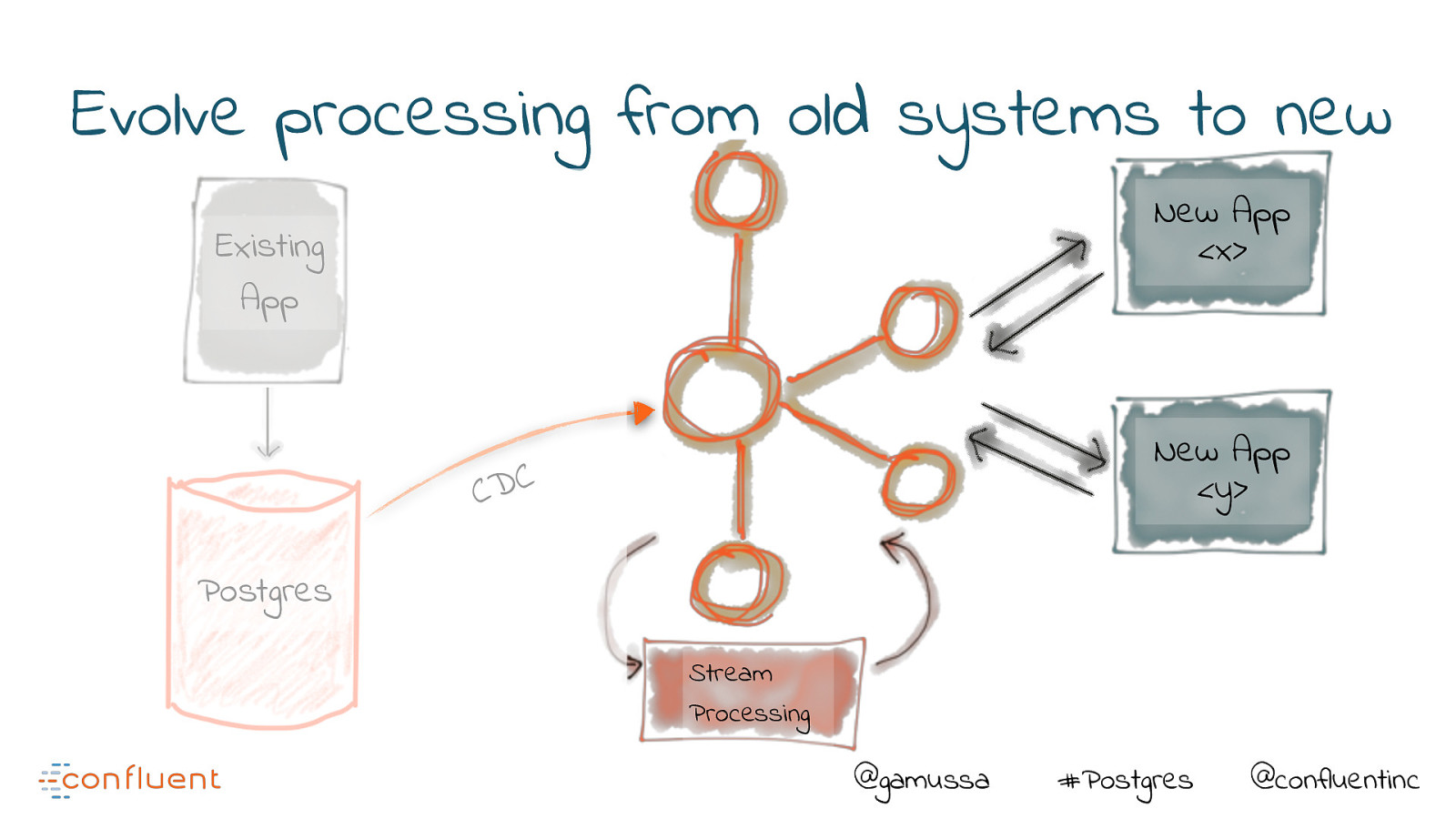
Evolve processing from old systems to new New App <x> Existing App New App <y> C D C Postgres Stream Processing @gamussa #Postgres @confluentinc
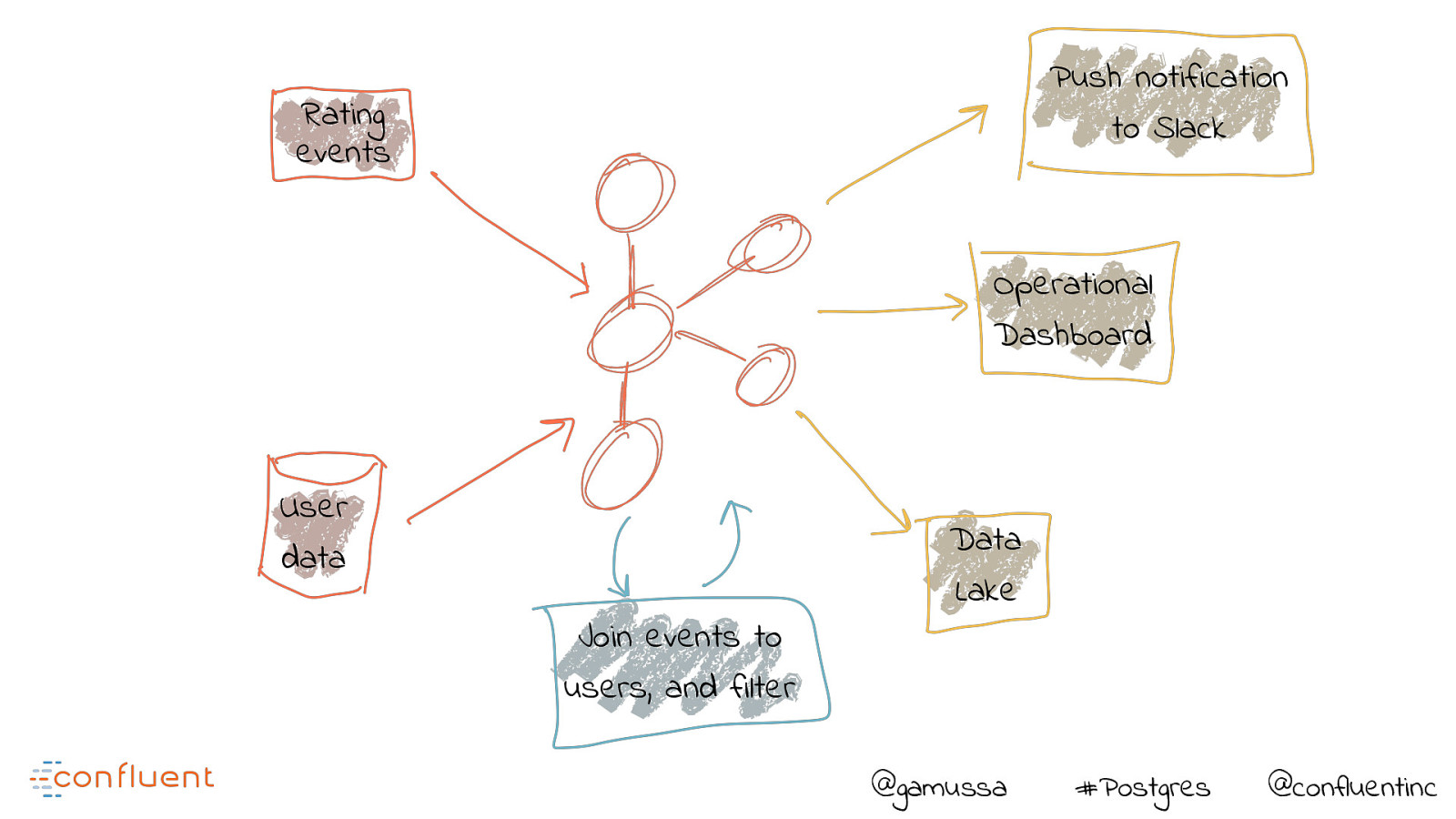
Push notification to Slack Rating events Operational Dashboard User data Join events to users, and filter Data Lake @gamussa #Postgres @confluentinc
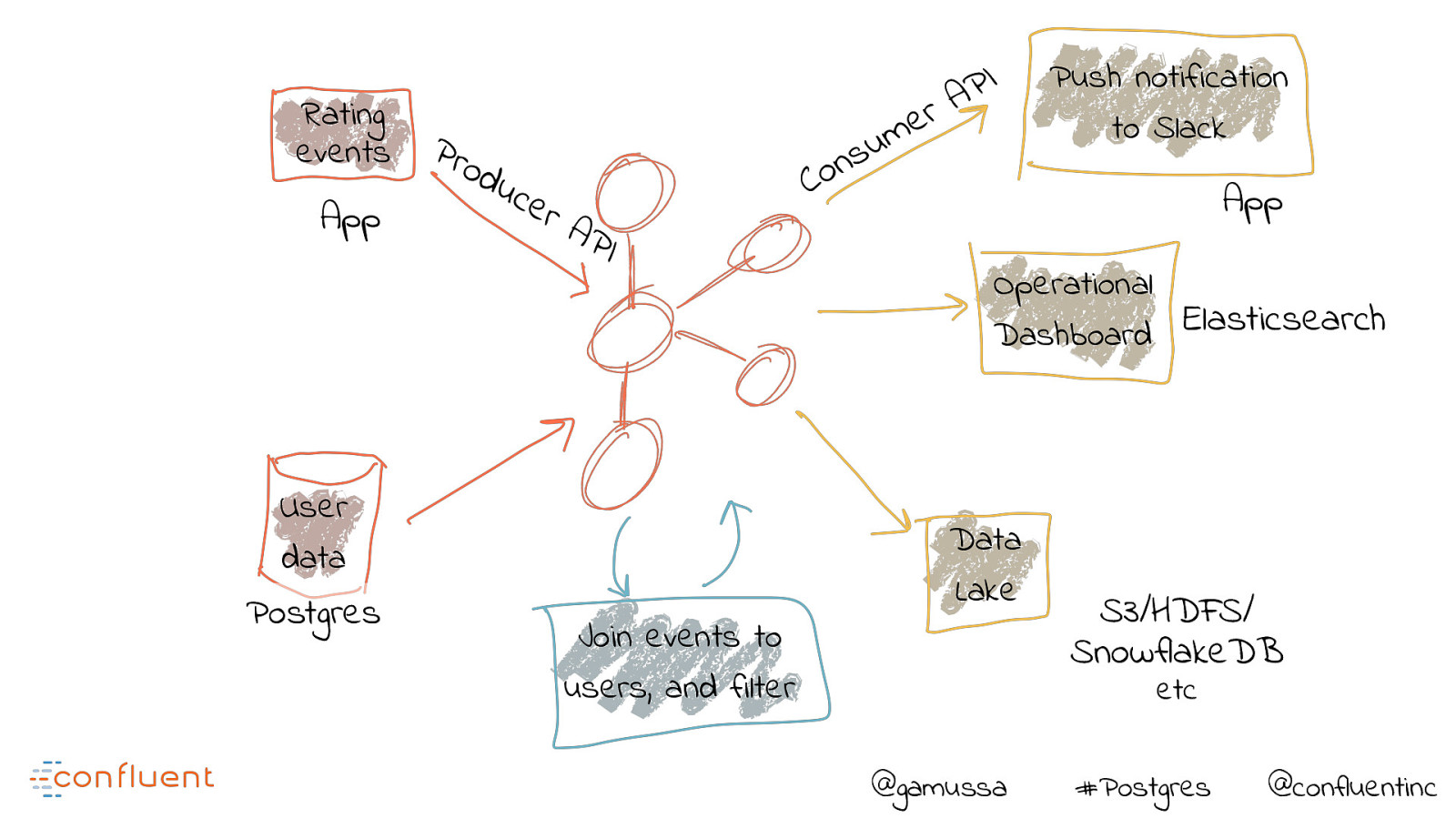
Rating events App Pro d uc e rA PI User data Postgres Join events to users, and filter I P A r e m u s n o C Push notification to Slack App Operational Elasticsearch Dashboard Data Lake S3/HDFS/ SnowflakeDB etc @gamussa #Postgres @confluentinc
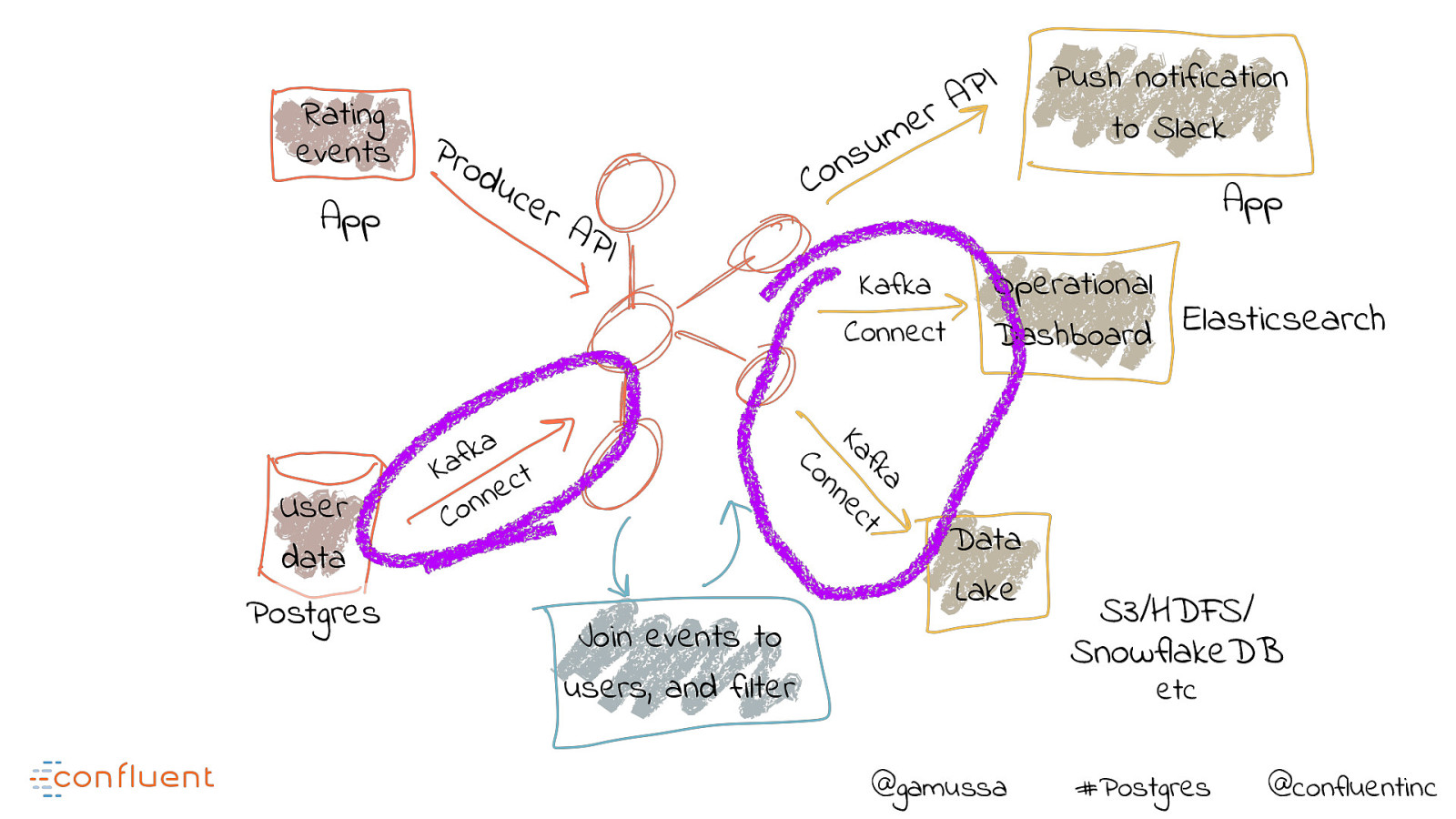
Rating events App uc e rA PI a k f a K t c e n n o C Kafka Connect a fk t Ka ec n Postgres u s n o C Push notification to Slack App Operational Elasticsearch Dashboard n Co User data Pro d I P A r e m Join events to users, and filter Data Lake S3/HDFS/ SnowflakeDB etc @gamussa #Postgres @confluentinc
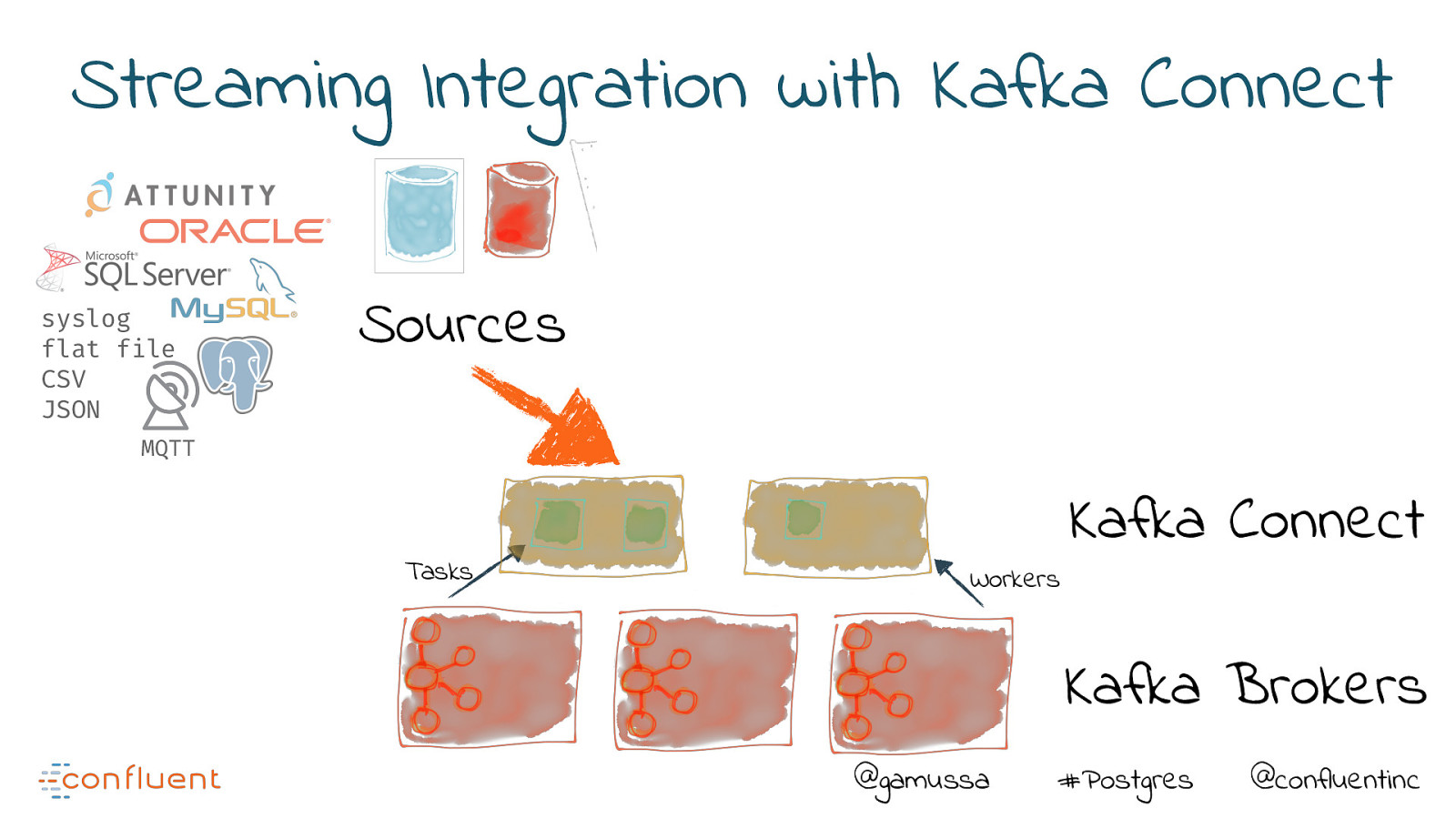
Streaming Integration with Kafka Connect syslog flat file CSV JSON Sources MQTT Tasks Workers Kafka Connect Kafka Brokers @gamussa #Postgres @confluentinc
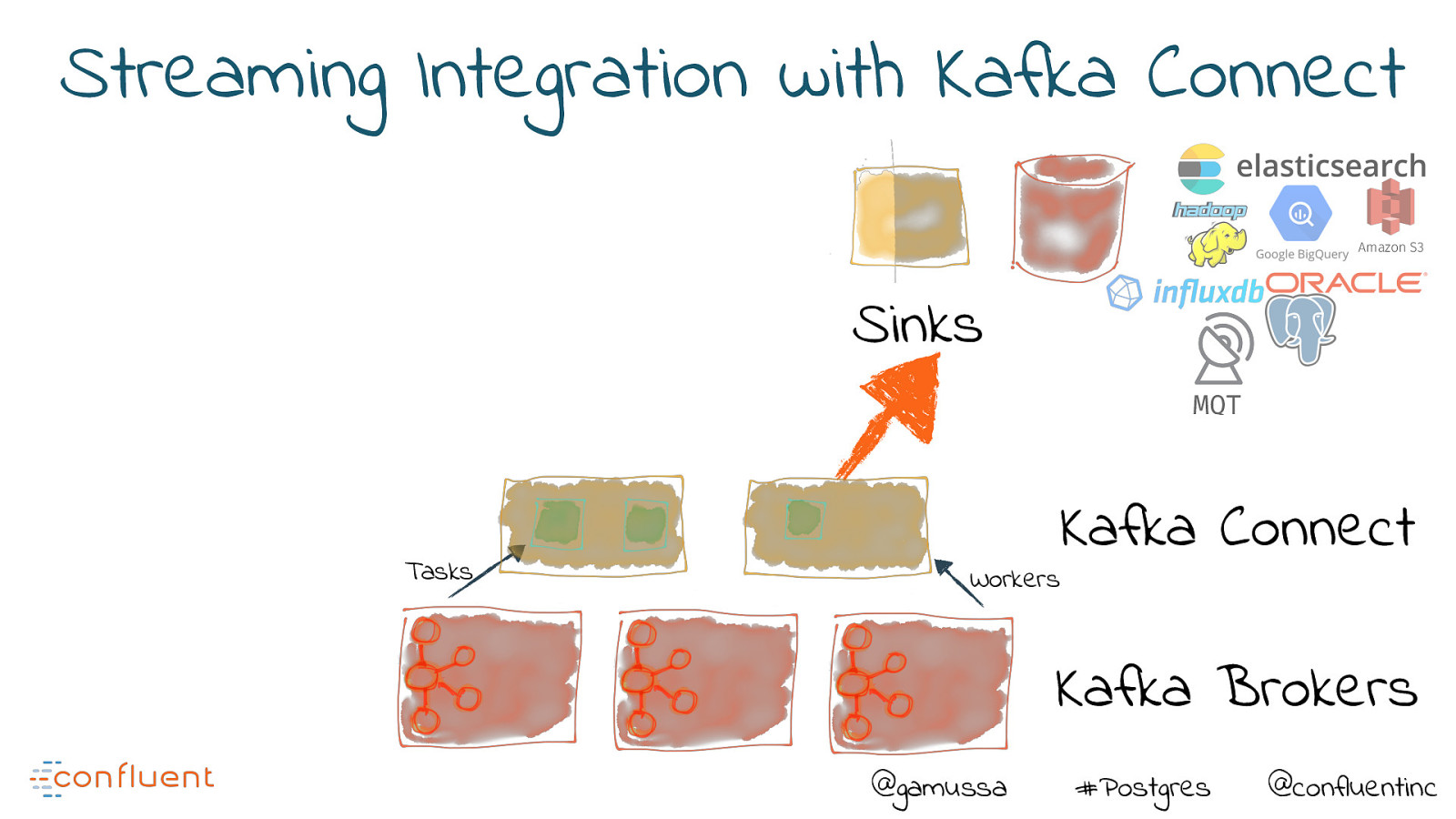
Streaming Integration with Kafka Connect Amazon S3 Sinks MQT Tasks Kafka Connect Workers Kafka Brokers @gamussa #Postgres @confluentinc
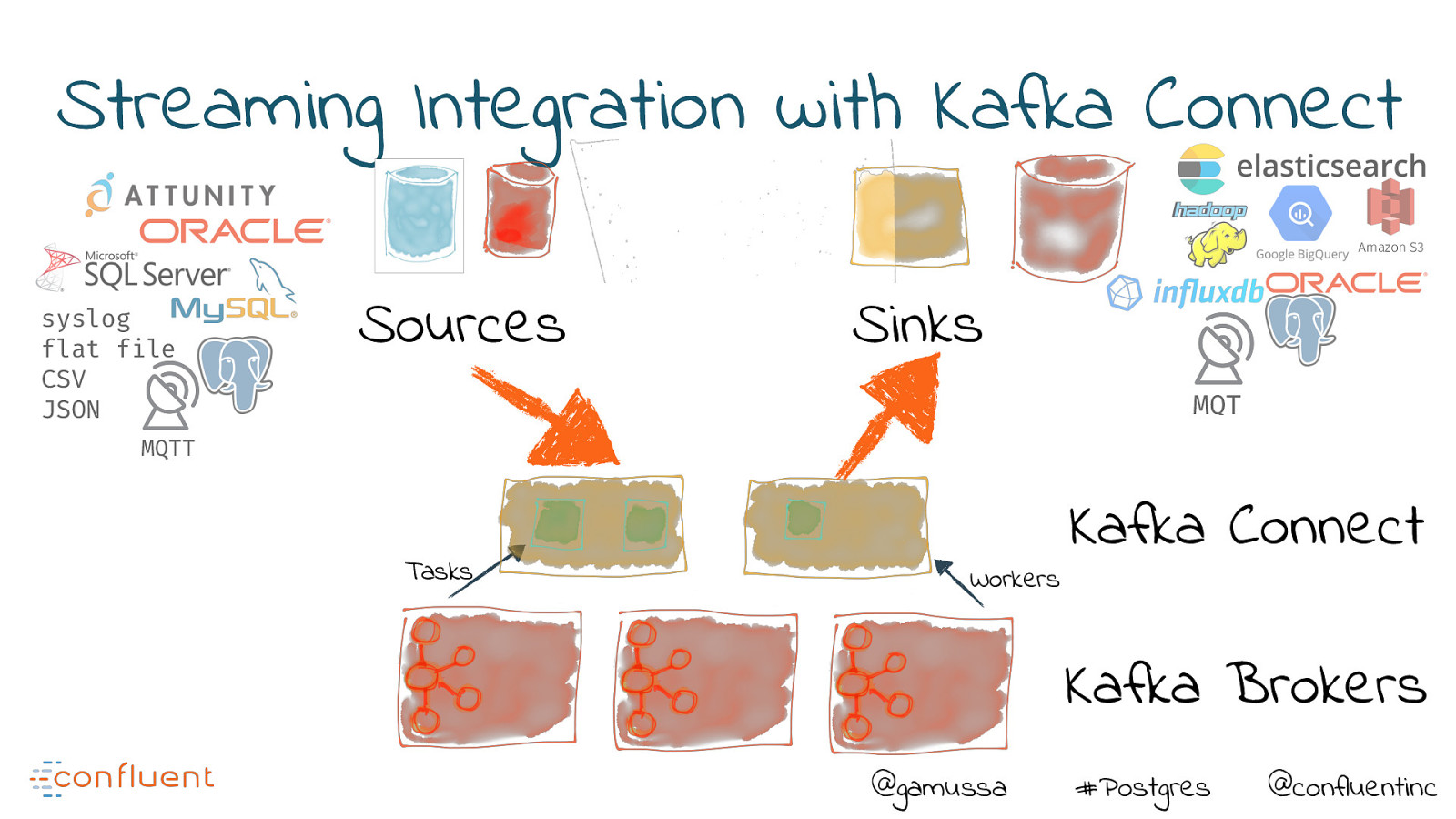
Streaming Integration with Kafka Connect Amazon S3 syslog flat file CSV JSON Sources Sinks MQT MQTT Tasks Workers Kafka Connect Kafka Brokers @gamussa #Postgres @confluentinc

Integrating Postgres with Kafka Kafka Connect & Debezium Kafka Connect & JDBC Sink @gamussa #Postgres @confluentinc

Confluent Hub •One-stop place to discover and download : •Connectors •Transformations •Converters hub.confluent.io @gamussa #Postgres @confluentinc

Stop! Demo time! Producer API Postgres t c e n n o C a k f Ka m u i z e b e D @gamussa #Postgres @confluentinc
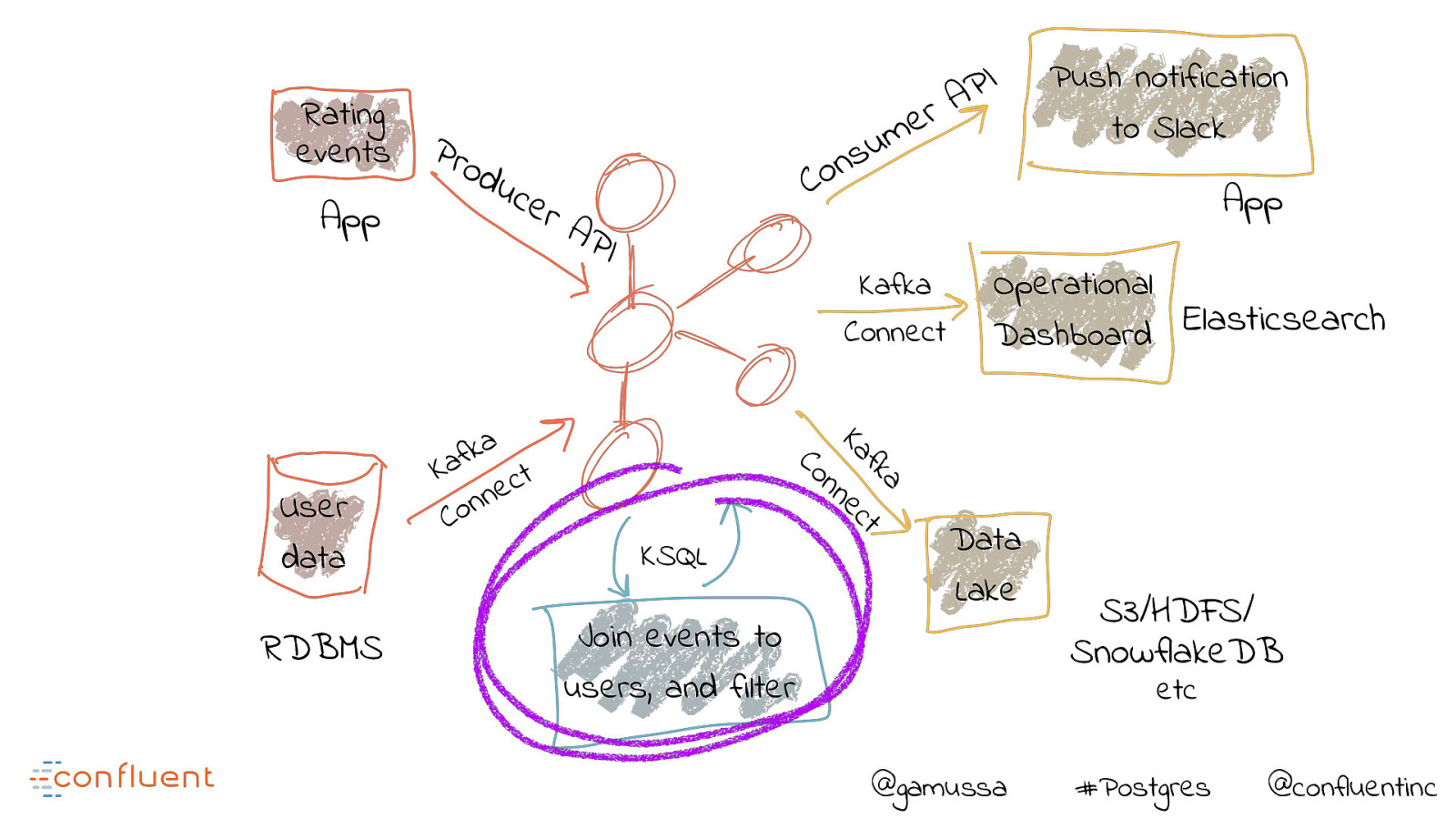
Rating events App uc e rA PI a k f a K t c e n n o C Kafka Connect a fk t Ka ec n RDBMS u s n o C Push notification to Slack App Operational Elasticsearch Dashboard n Co User data Pro d I P A r e m KSQL Join events to users, and filter Data Lake S3/HDFS/ SnowflakeDB etc @gamussa #Postgres @confluentinc
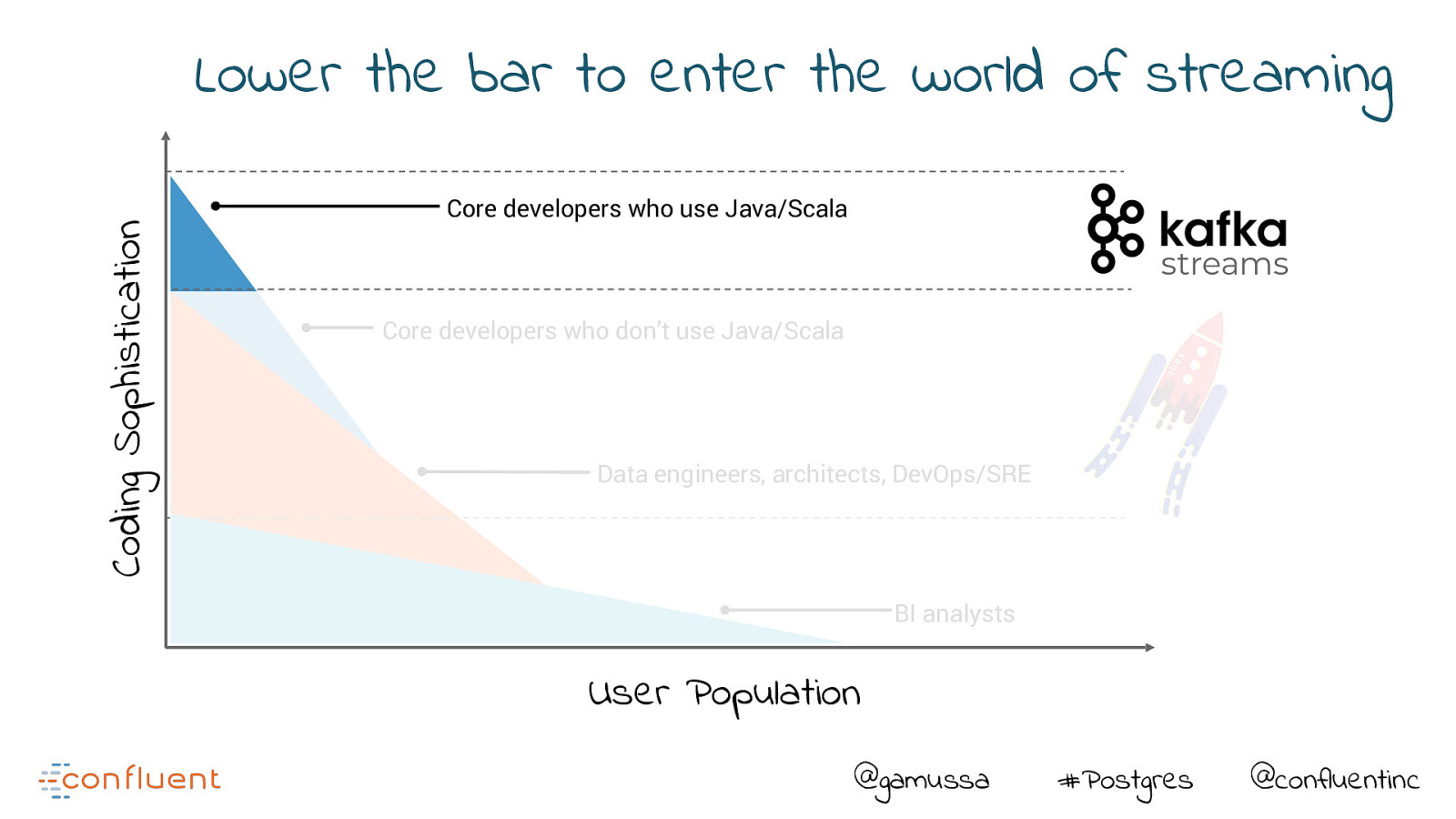
Coding Sophistication Lower the bar to enter the world of streaming Core developers who use Java/Scala streams Core developers who don’t use Java/Scala Data engineers, architects, DevOps/SRE BI analysts User Population @gamussa #Postgres @confluentinc
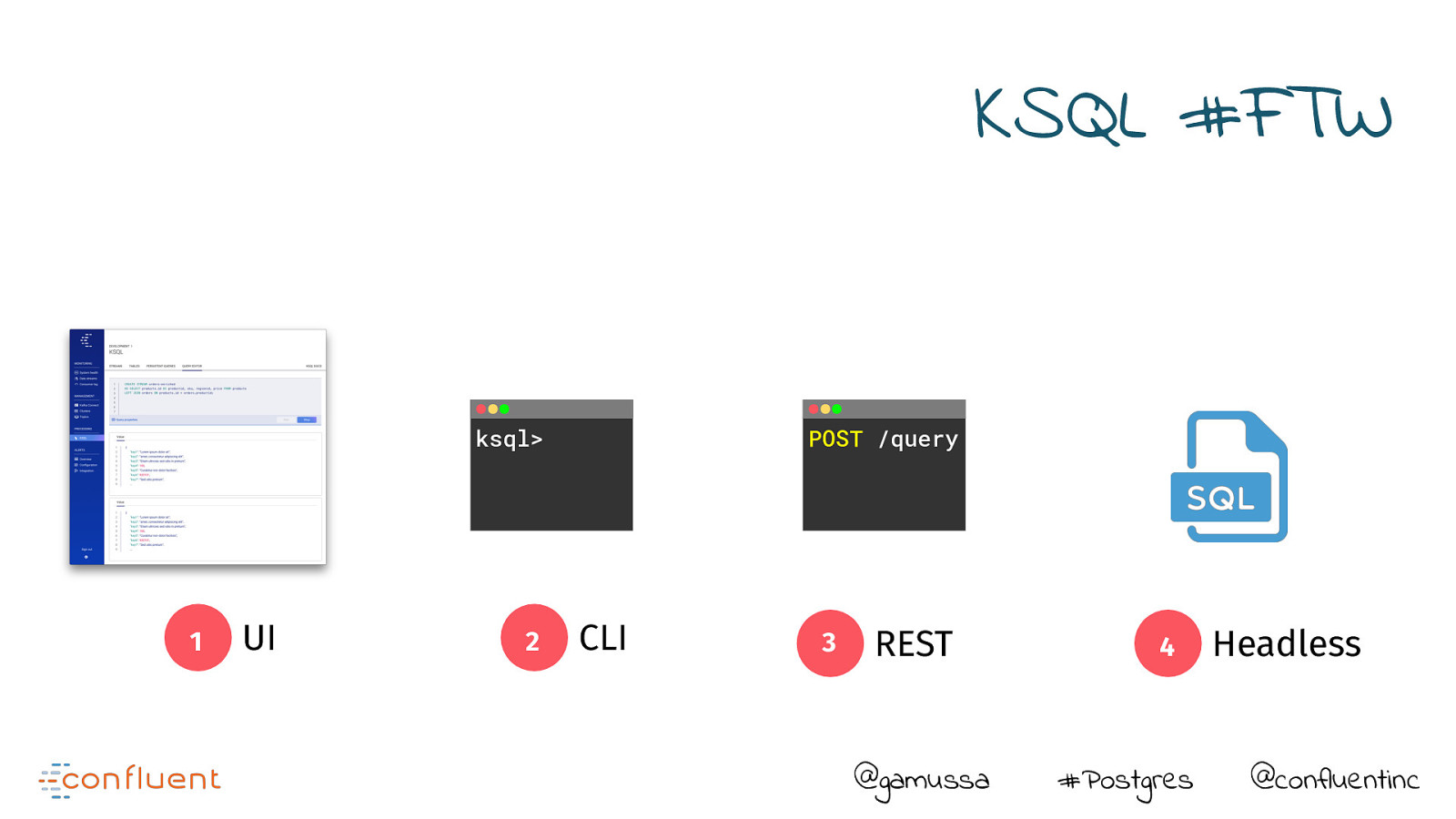
KSQL #FTW ksql> 1 UI 2 POST /query CLI 3 REST @gamussa 4 #Postgres Headless @confluentinc
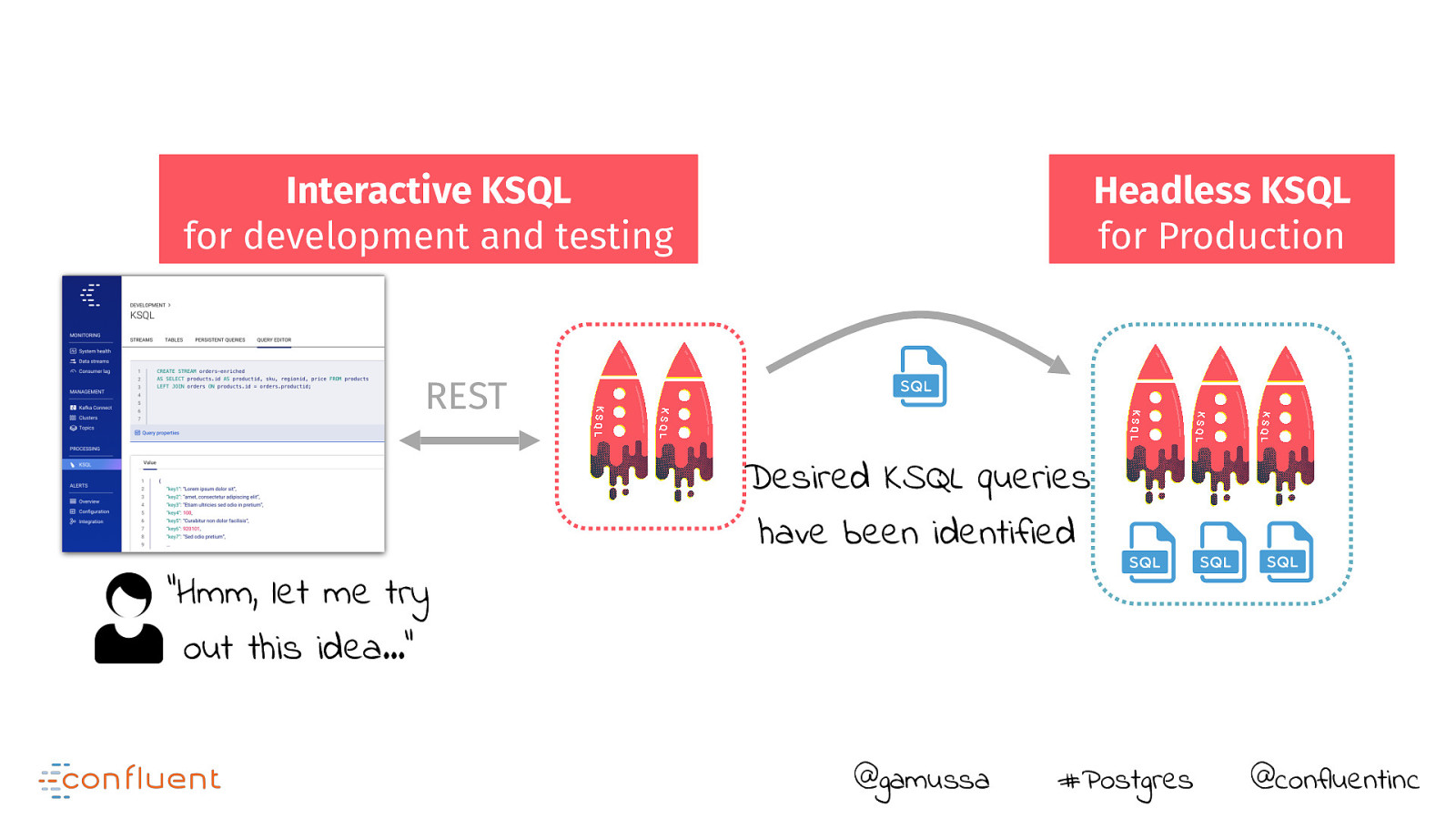
Interactive KSQL for development and testing Headless KSQL for Production REST Desired KSQL queries have been identified “Hmm, let me try out this idea…” @gamussa #Postgres @confluentinc
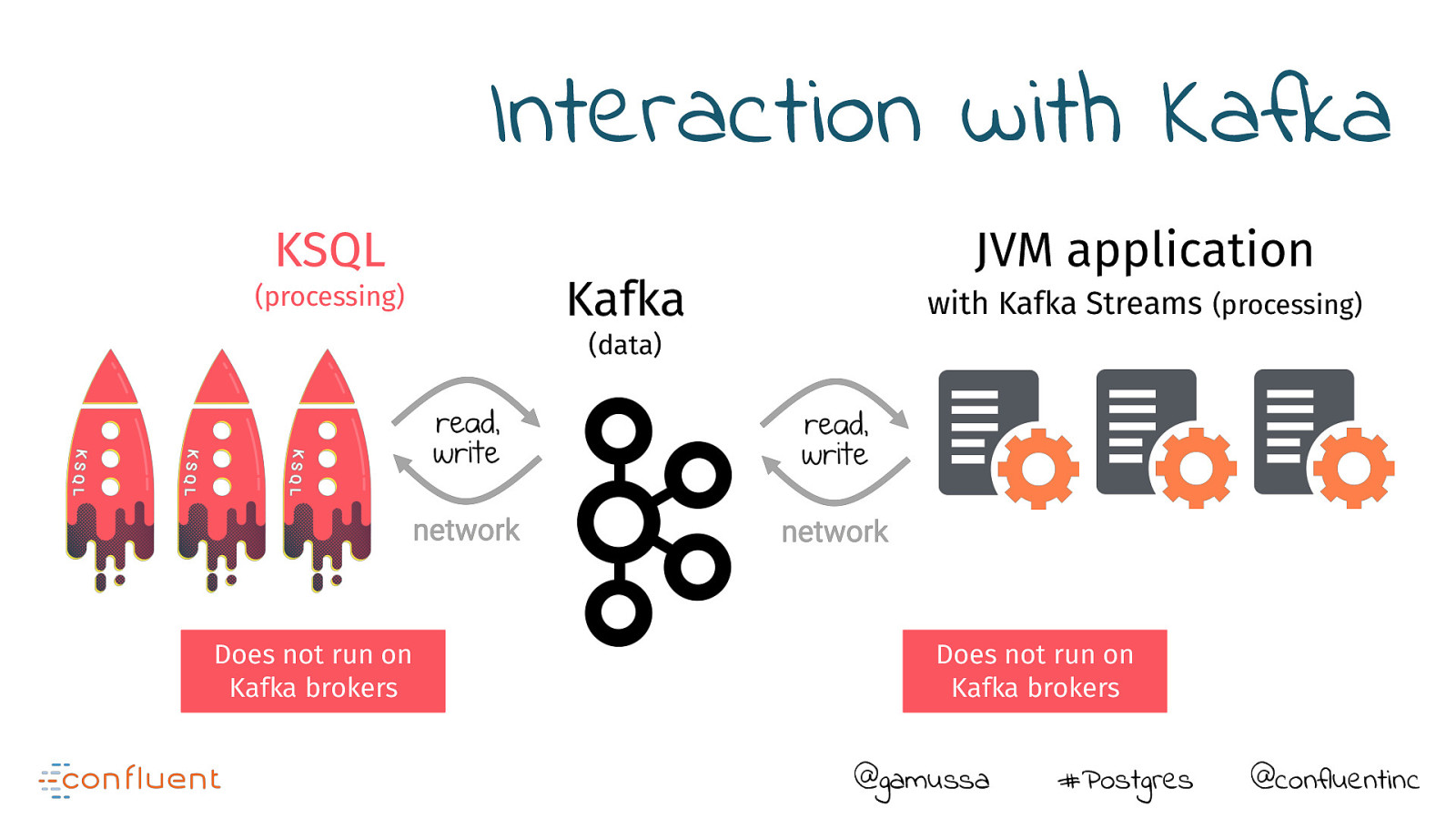
Interaction with Kafka KSQL (processing) Kafka JVM application with Kafka Streams (processing) (data) Does not run on Kafka brokers Does not run on Kafka brokers @gamussa #Postgres @confluentinc
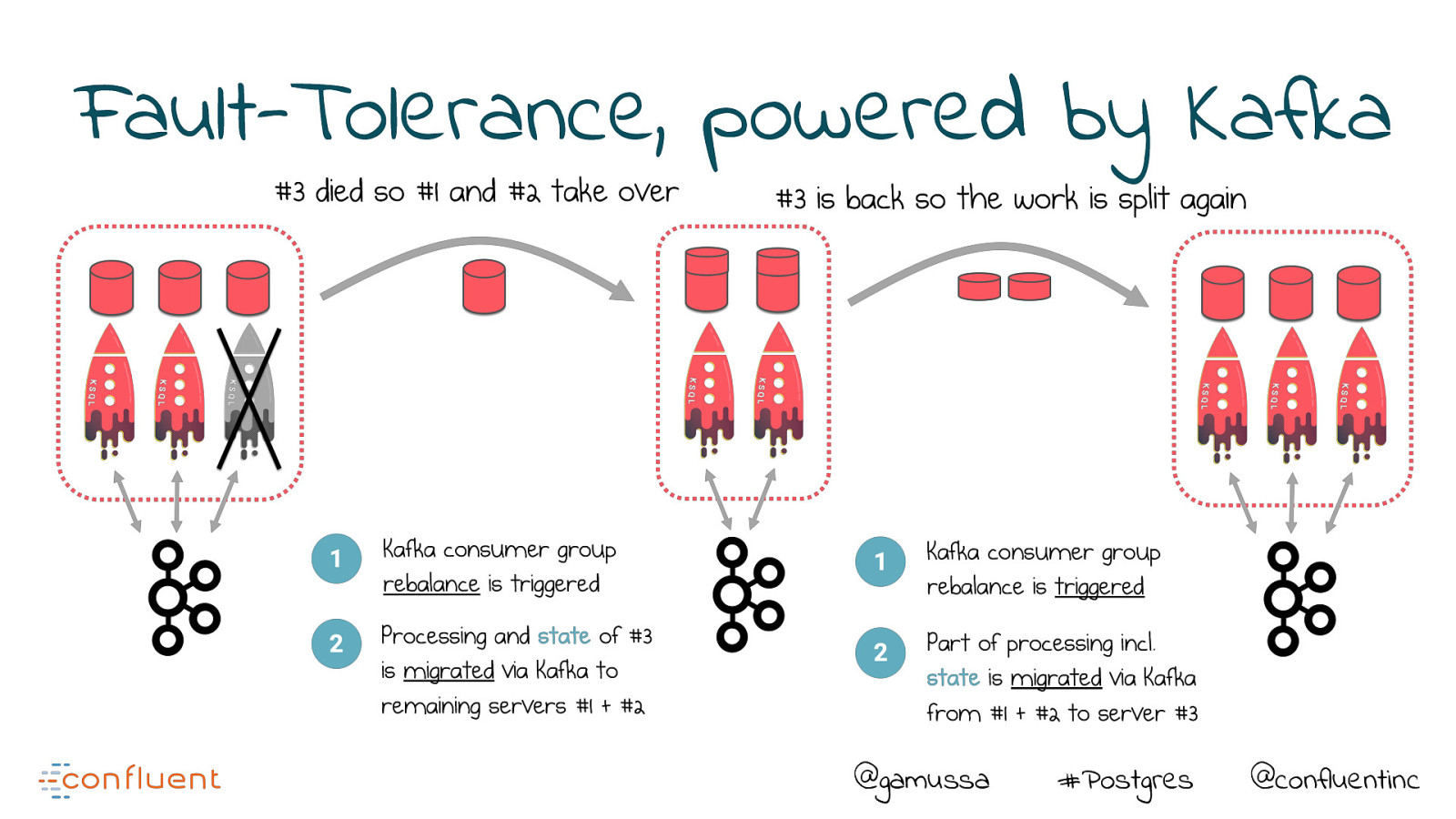
Fault-Tolerance, powered by Kafka @gamussa #Postgres @confluentinc
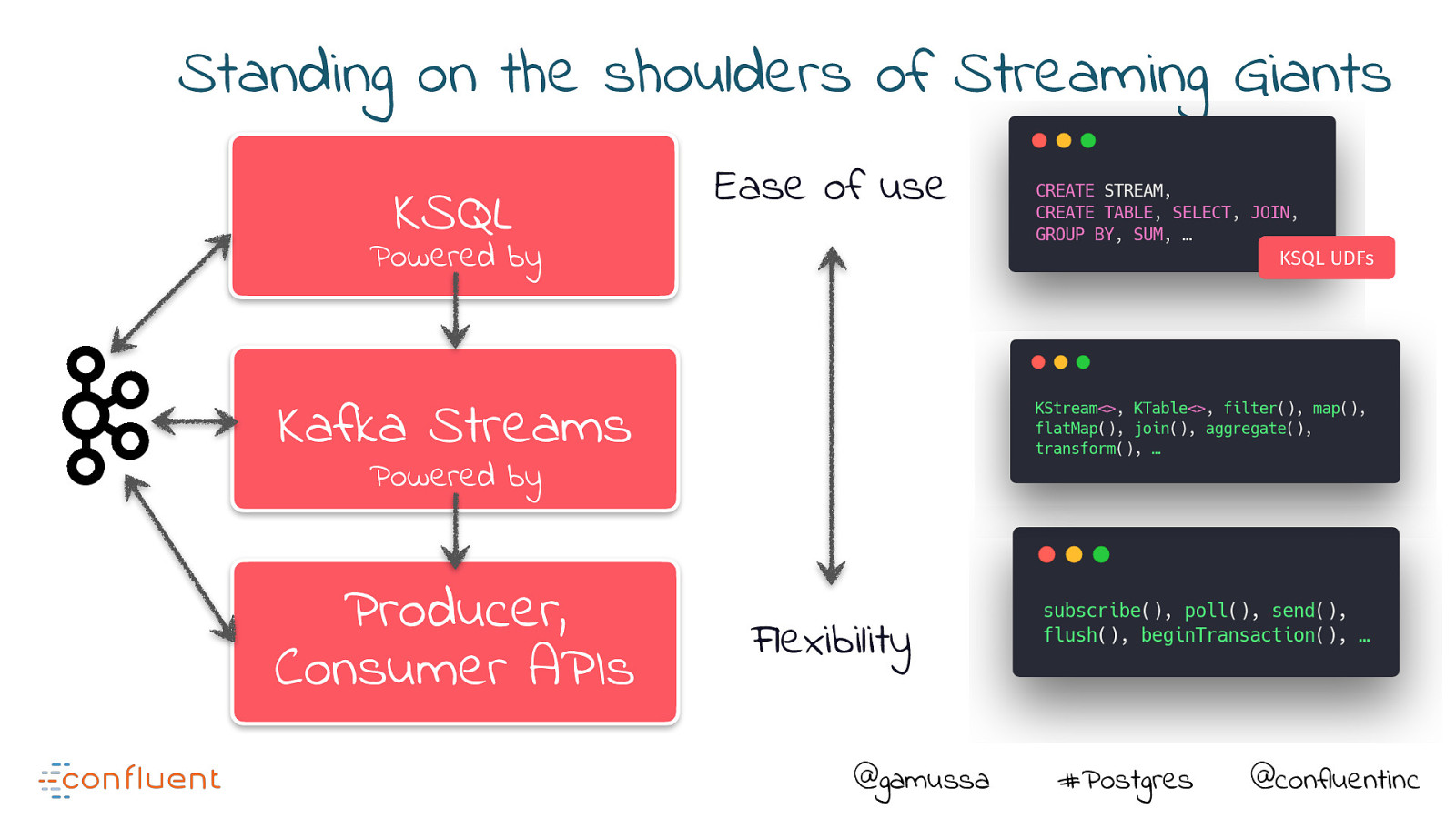
Standing on the shoulders of Streaming Giants KSQL Ease of use Powered by KSQL UDFs Kafka Streams Powered by Producer, Consumer APIs Flexibility @gamussa #Postgres @confluentinc
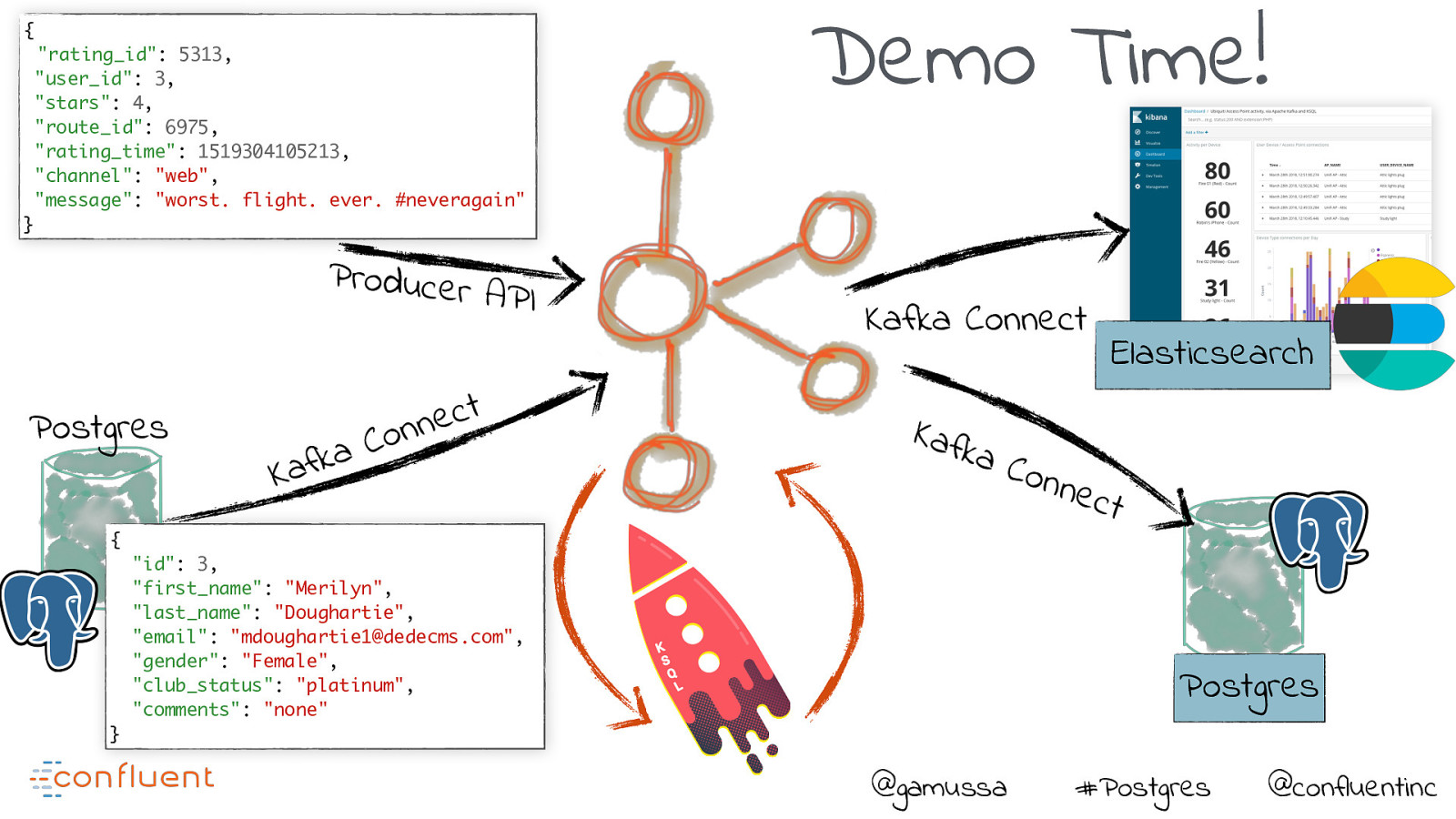
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” Demo Time! } Producer API Postgres t c e n n o C a k f Ka { Kafka Connect Kafk a Elasticsearch Con nec t “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” Postgres } @gamussa #Postgres @confluentinc
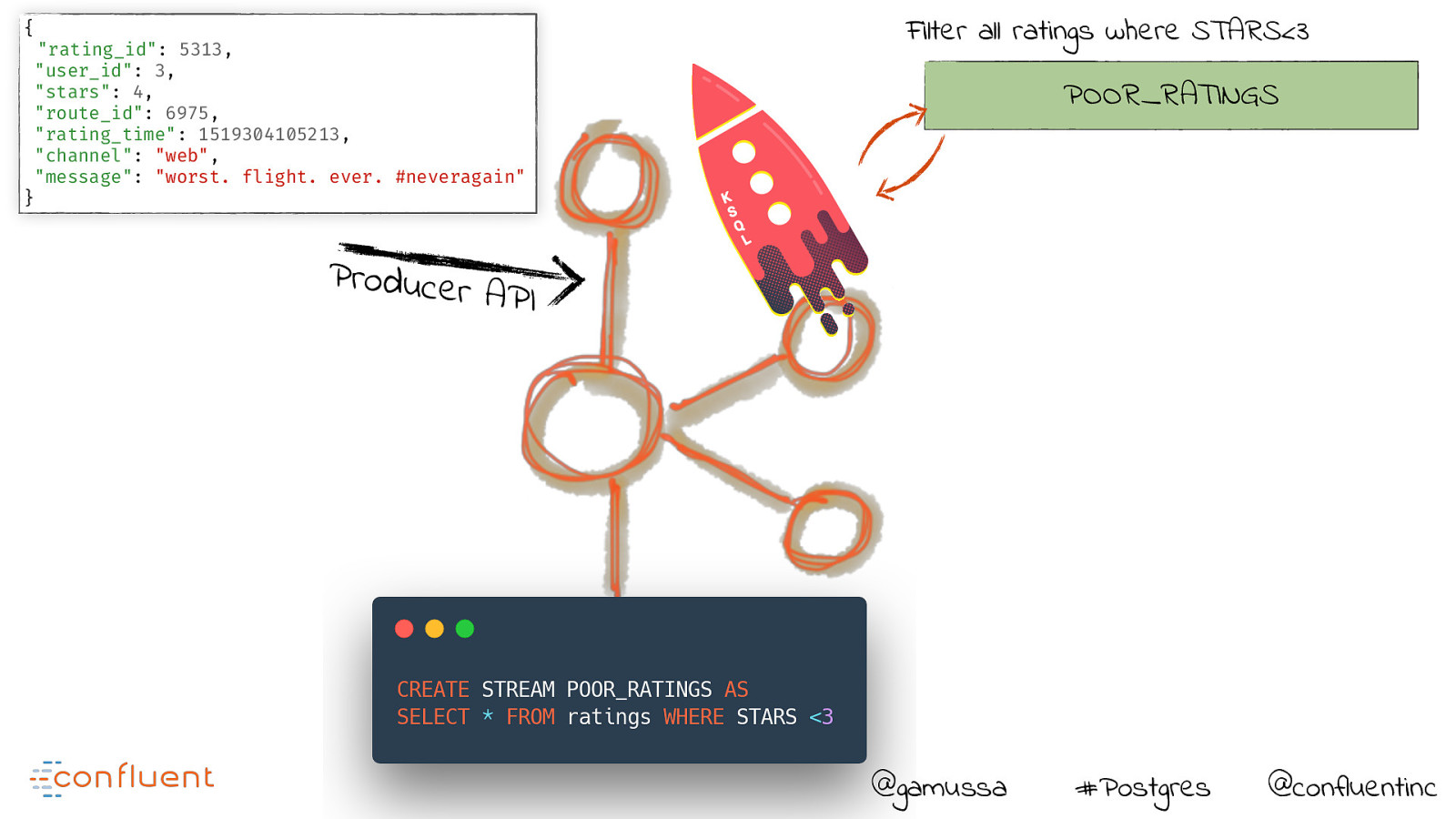
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” Filter all ratings where STARS<3 POOR_RATINGS } Producer API @gamussa #Postgres @confluentinc

Do you think that’s a table you are querying ?
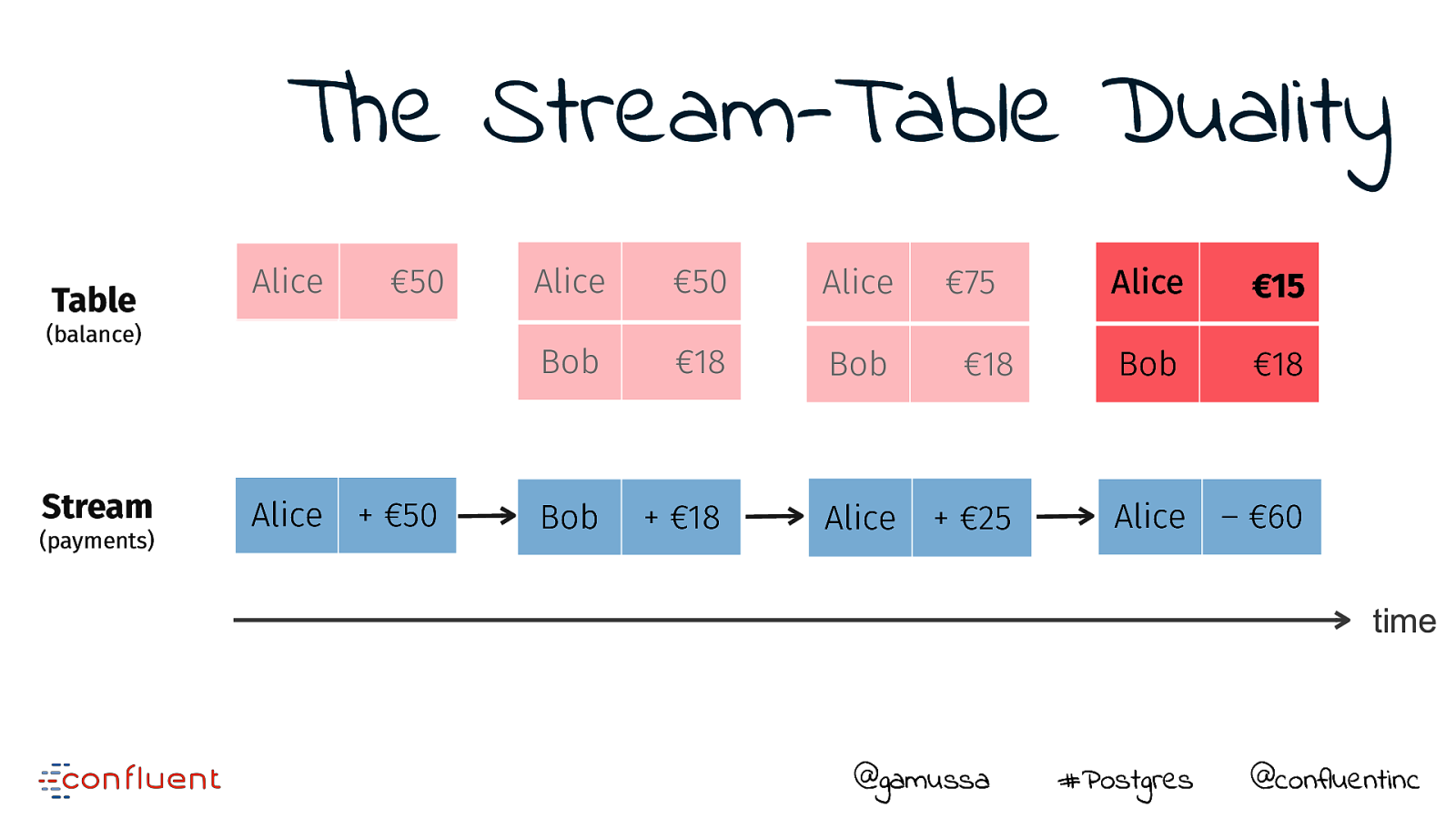
The Stream-Table Duality Table Alice €50 (balance) Stream (payments) Alice
- €50 Alice €50 Alice €75 €75 Alice €15 Bob €18 €18 Bob €18 Bob €18 Bob
- €18 Alice
- €25 Alice – €60 time @gamussa #Postgres @confluentinc

The truth is the log. The database is a cache of a subset of the log. —Pat Helland Immutability Changes Everything http://cidrdb.org/cidr2015/Papers/CIDR15_Paper16.pdf @gamussa #Postgres @confluentinc
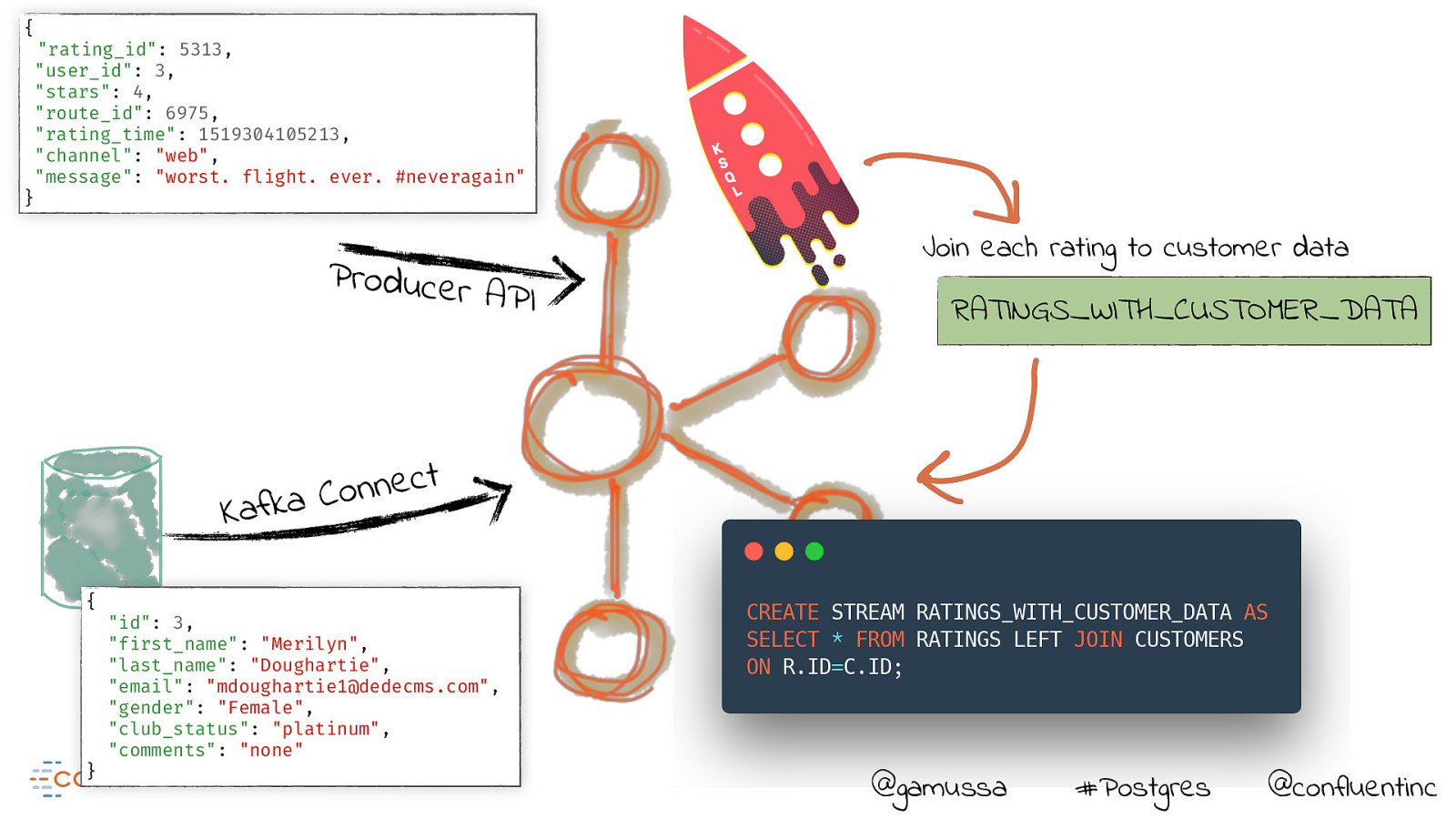
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” } Producer API Join each rating to customer data RATINGS_WITH_CUSTOMER_DATA t c e n n o C a k f a K { } “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” @gamussa #Postgres @confluentinc
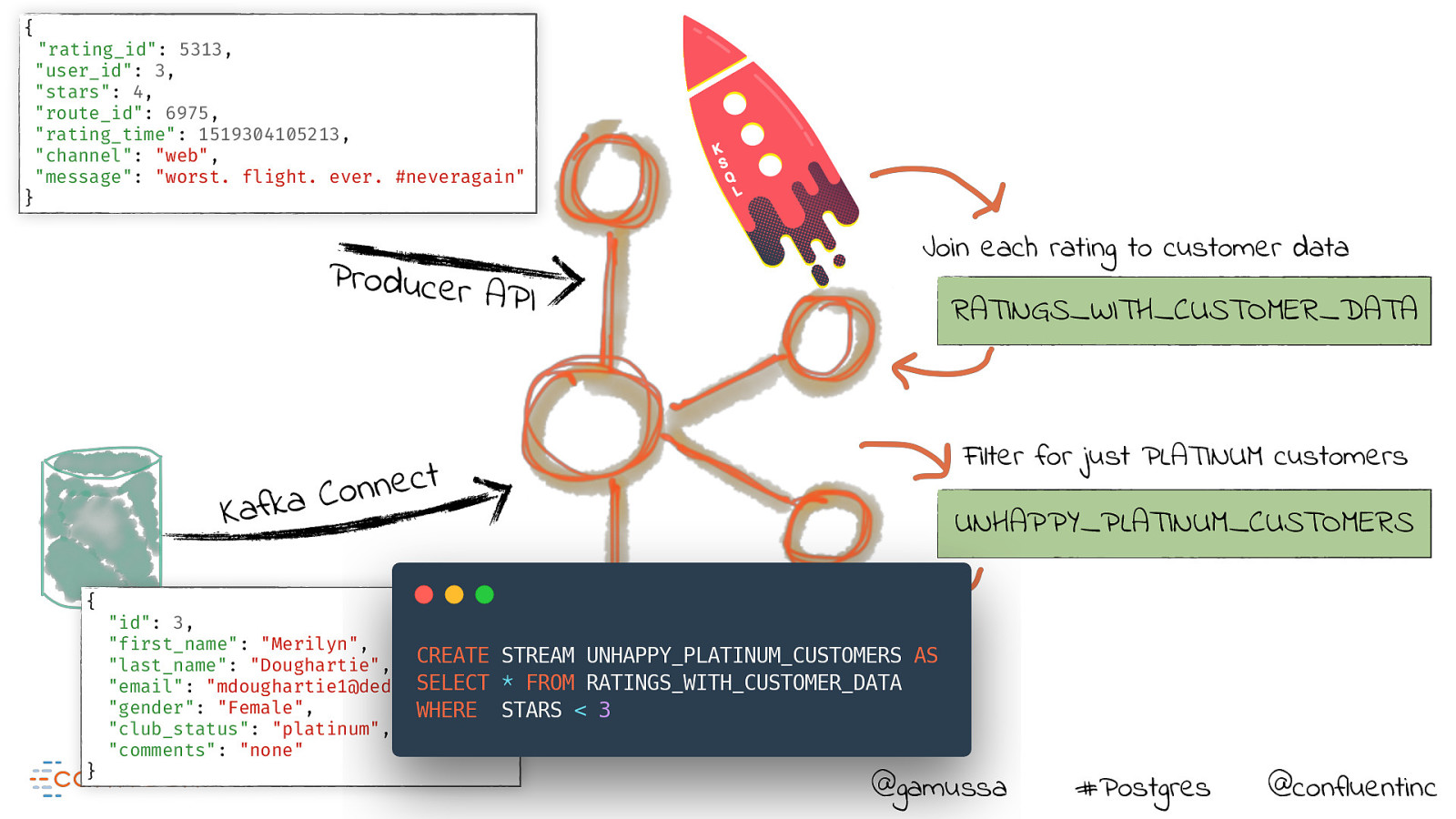
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” } Producer API t c e n n o C a k f a K { } Join each rating to customer data RATINGS_WITH_CUSTOMER_DATA Filter for just PLATINUM customers UNHAPPY_PLATINUM_CUSTOMERS “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” @gamussa #Postgres @confluentinc
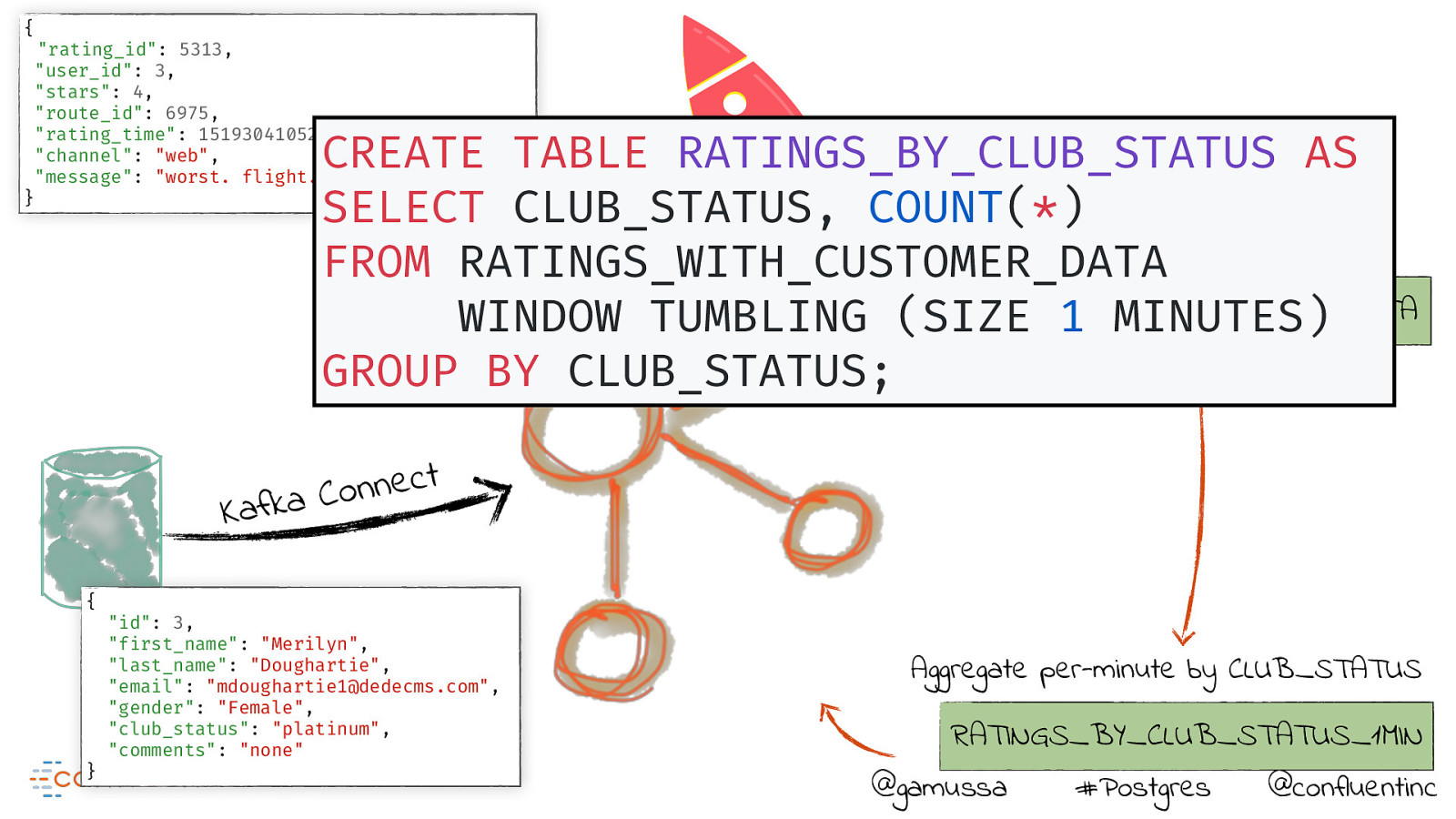
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” CREATE TABLE RATINGS_BY_CLUB_STATUS AS SELECT CLUB_STATUS, COUNT(*) Join each rating to customer data FROM ProducerRATINGS_WITH_CUSTOMER_DATA API RATINGS_WITH_CUSTOMER_DATA WINDOW TUMBLING (SIZE 1 MINUTES) GROUP BY CLUB_STATUS; } t c e n n o C a k f a K { } “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” Aggregate per-minute by CLUB_STATUS RATINGS_BY_CLUB_STATUS_1MIN @gamussa #Postgres @confluentinc

Resources and Next Steps https://github.com/confluentinc/examples http://confluent.io https://slackpass.io/confluentcommunity #ksql #connect @gamussa #Postgres @confluentinc

Free Books! https://www.confluent.io/apache-kafka-stream-processing-book-bundle @gamussa #Postgres @confluentinc

One last thing… @gamussa #Postgres @confluentinc

https://kafka-summit.org Gamov30 @gamussa #Postgres @confluentinc

Thanks! @gamussa viktor@confluent.io @gamussa #Postgres @confluentinc

Have you ever thought that you needed to be a programmer to do stream processing and build streaming data pipelines? Think again!
Companies new and old are all recognizing the importance of a low-latency, scalable, fault-tolerant data backbone, in the form of the Apache Kafka® streaming platform.
With Kafka, developers can integrate multiple sources and systems, which enables low latency analytics, event-driven architectures and the population of multiple downstream systems.
These data pipelines can be built using configuration alone.
In this talk, we’ll see how easy it is to stream data from a database such as PostgreSQL into Kafka using CDC and Kafka Connect.
Besides, we’ll use KSQL to filter, aggregate and join it to other data, and then stream this from Kafka out into multiple targets such as Elasticsearch and S3.
All of this will be accomplished without a single line of code!
Why should programming buffs have all the fun?
Resources
The following resources were mentioned during the presentation or are useful additional information.
-
Demos
This demo shows how to enrich event stream data with CDC data from Postgres and then stream into Elasticsearch.
Code
The following code examples from the presentation can be tried out live.