Cloud-Native Streaming Platform: Running Apache Kafka on PKS (Pivotal Container Service)
A presentation at SpringOne Platform in in Washington, DC, USA by Viktor Gamov

Cloud-Native Streaming Platform: Running Apache Kafka on PKS Prasad Radhakrishnan, @prasad_0101, Pivotal Viktor Gamov, @gamussa, Confluent
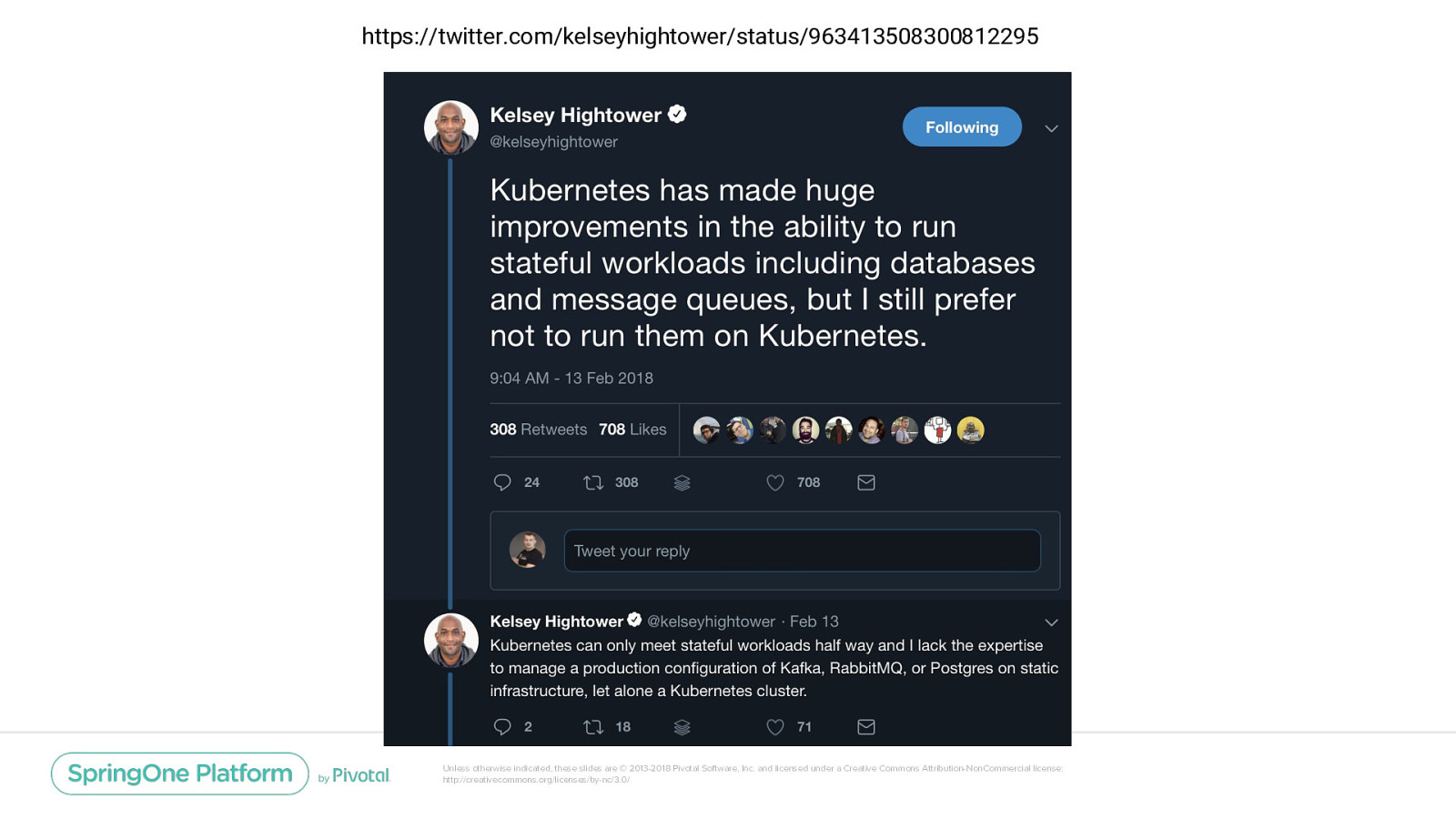
https://twitter.com/kelseyhightower/status/963413508300812295 Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Who we are Viktor Gamov Prasad Radhakrishnan Developer Advocate, Confluent Manager, Data Engineering @prasad_0101 @gamussa Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 3

Agenda • • • • • Why do you need a streaming platform Kafka on Kubernetes Pivotal ❤ Kafka Confluent Platform on PKS Demo Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 4 

Agenda • • • • • Why do you need a streaming platform Kafka on Kubernetes Pivotal ❤ Kafka Confluent Platform on PKS Demo Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 5 
Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

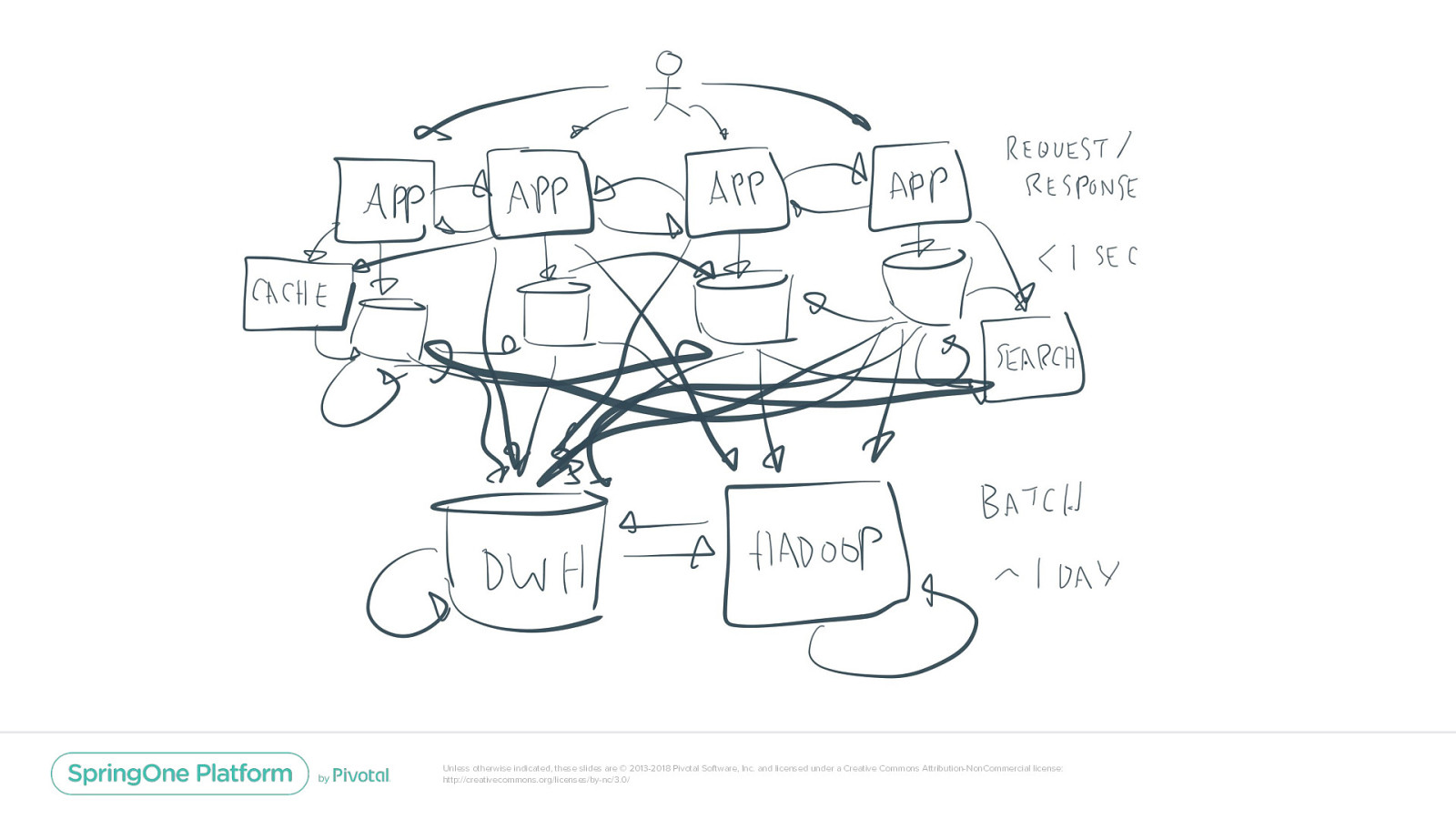
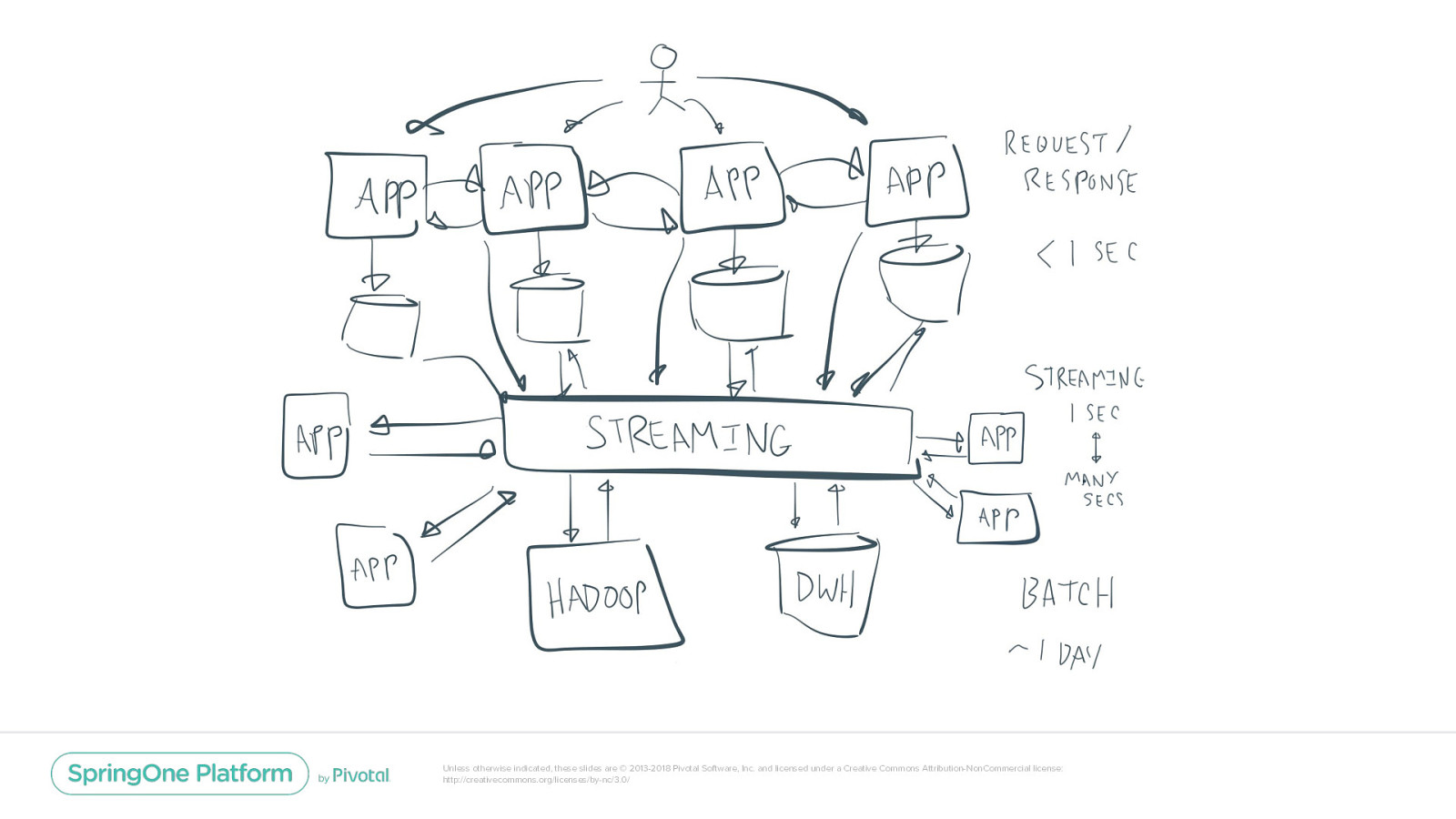
Is this streaming? Streaming Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
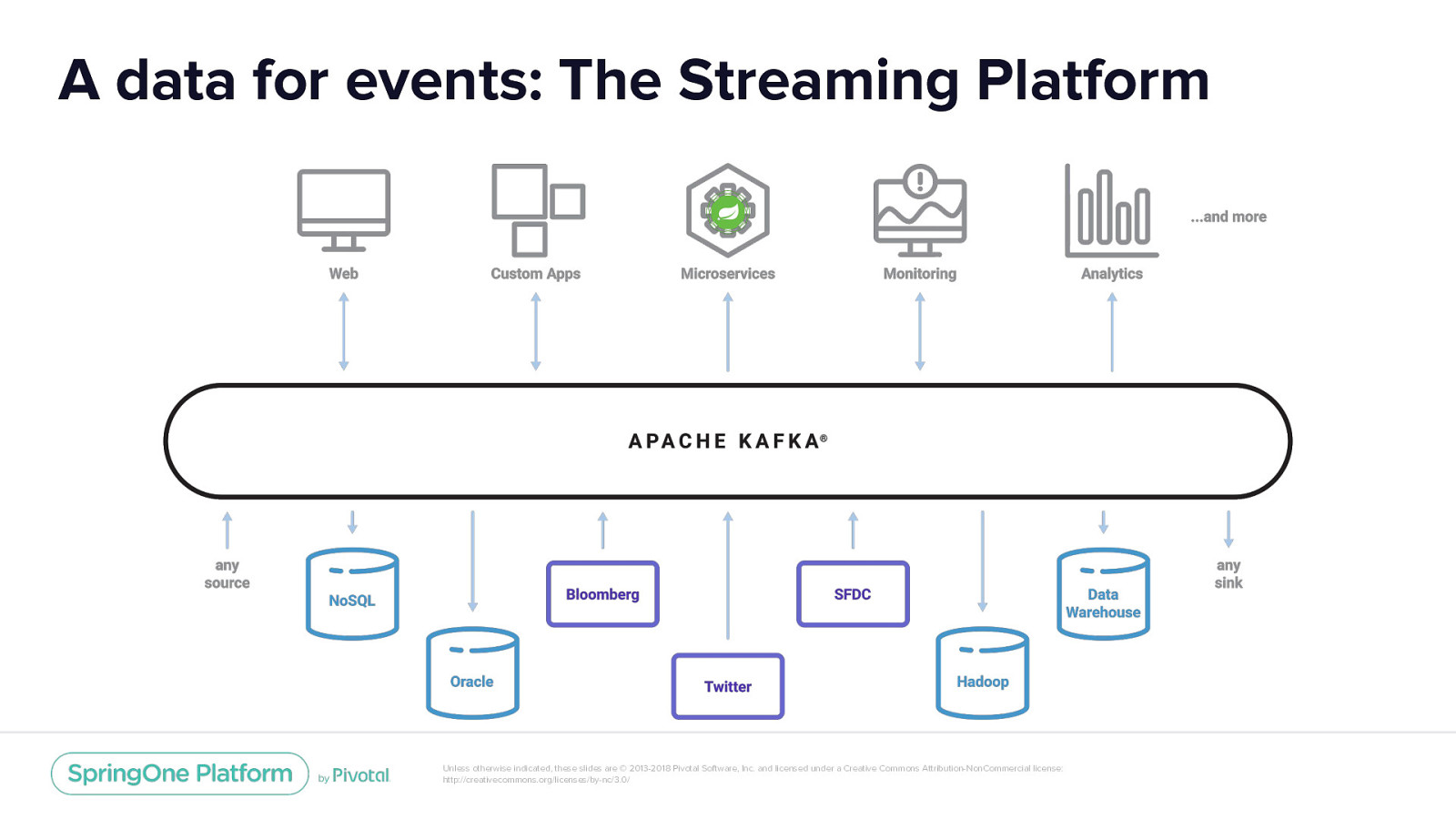
A data for events: The Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
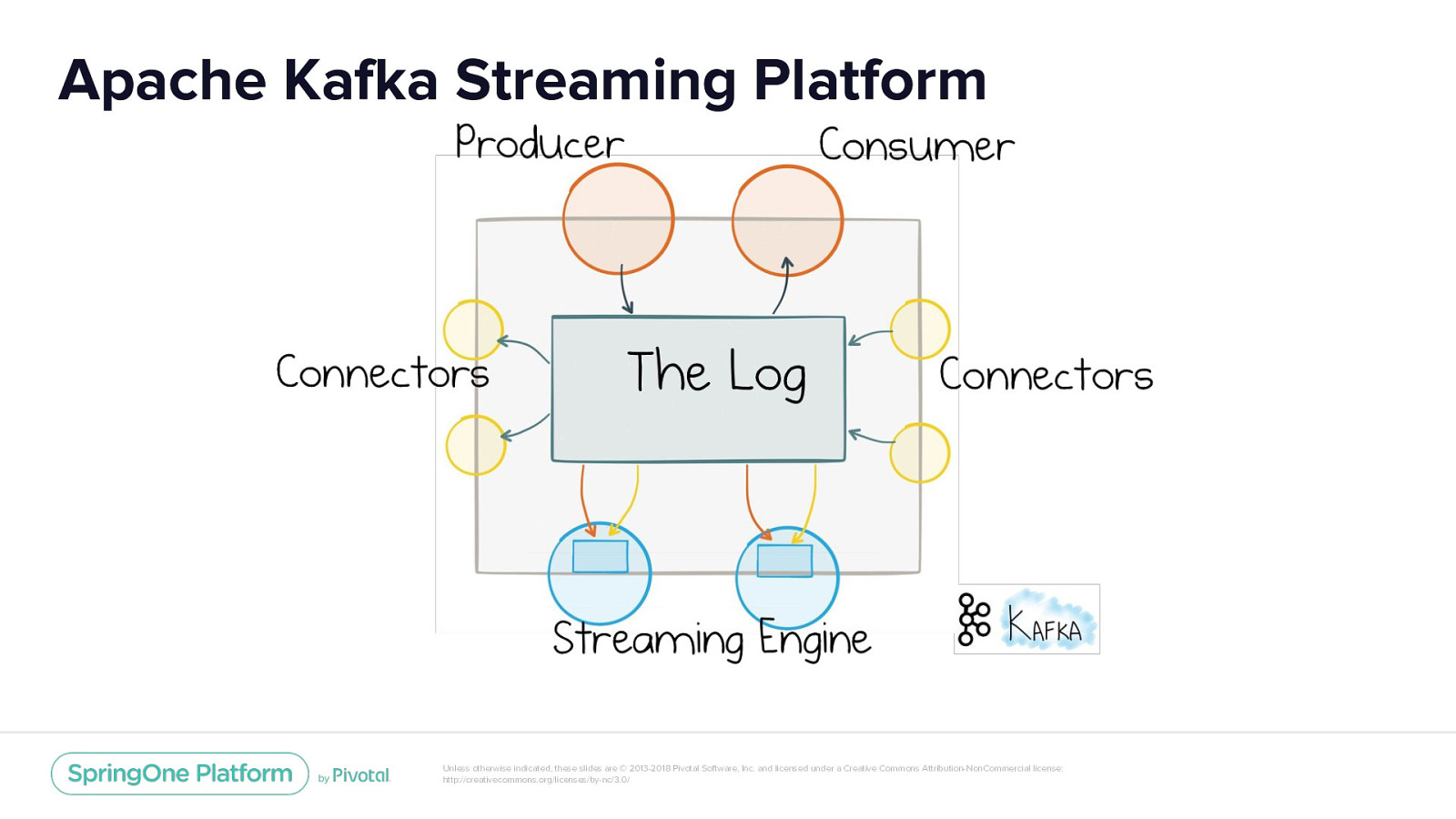
Apache Kafka Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
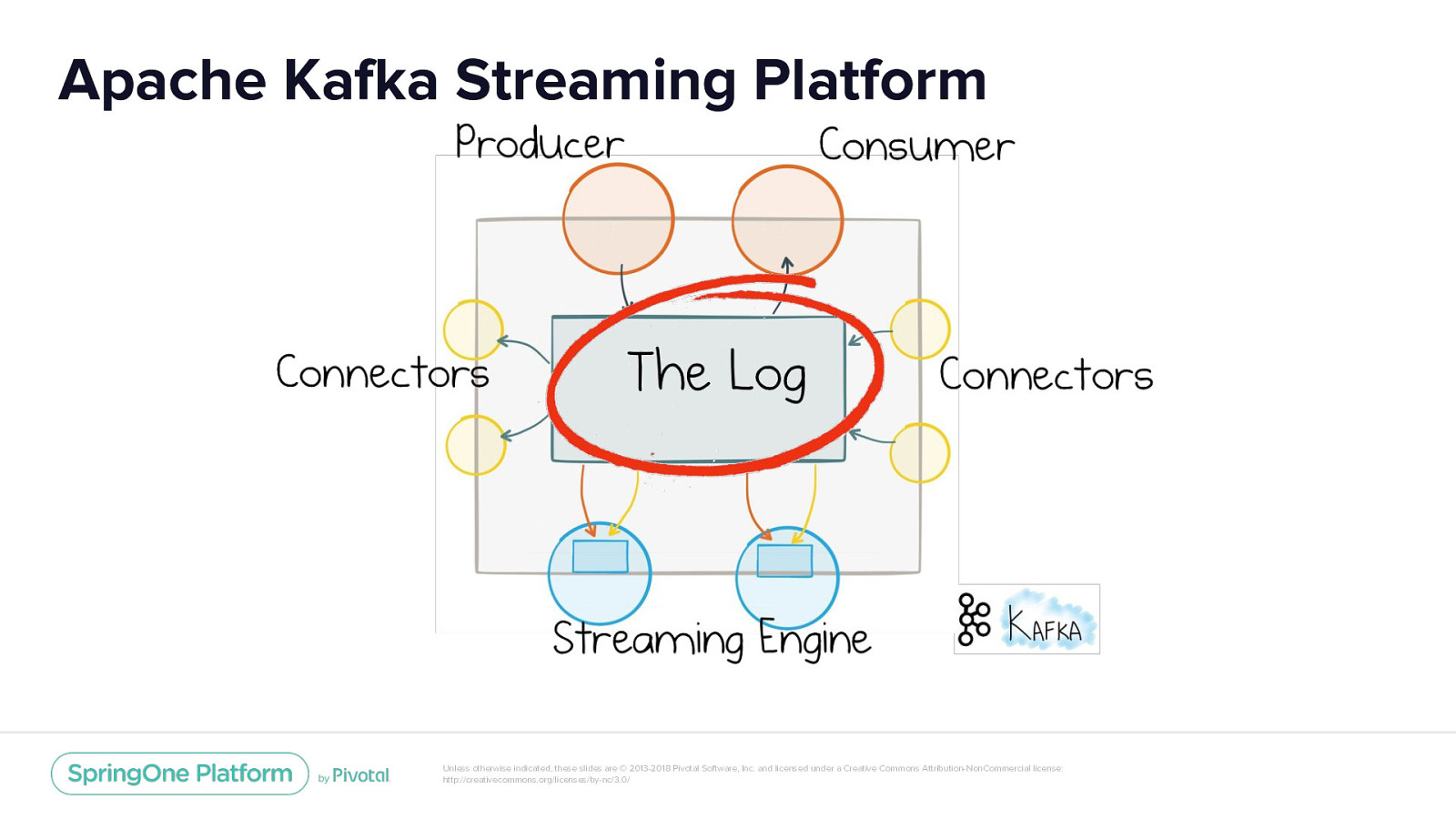
Apache Kafka Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
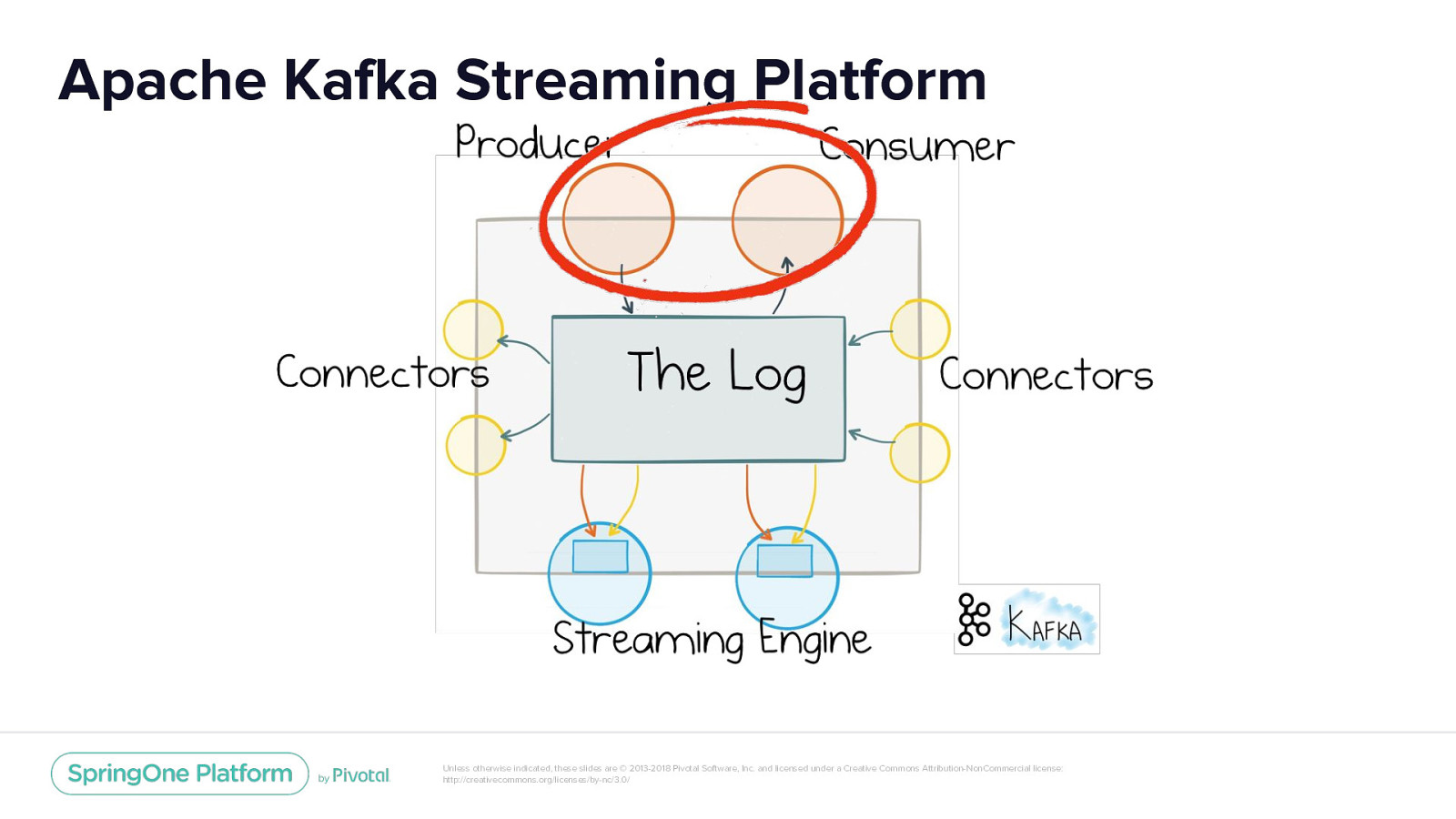
Apache Kafka Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
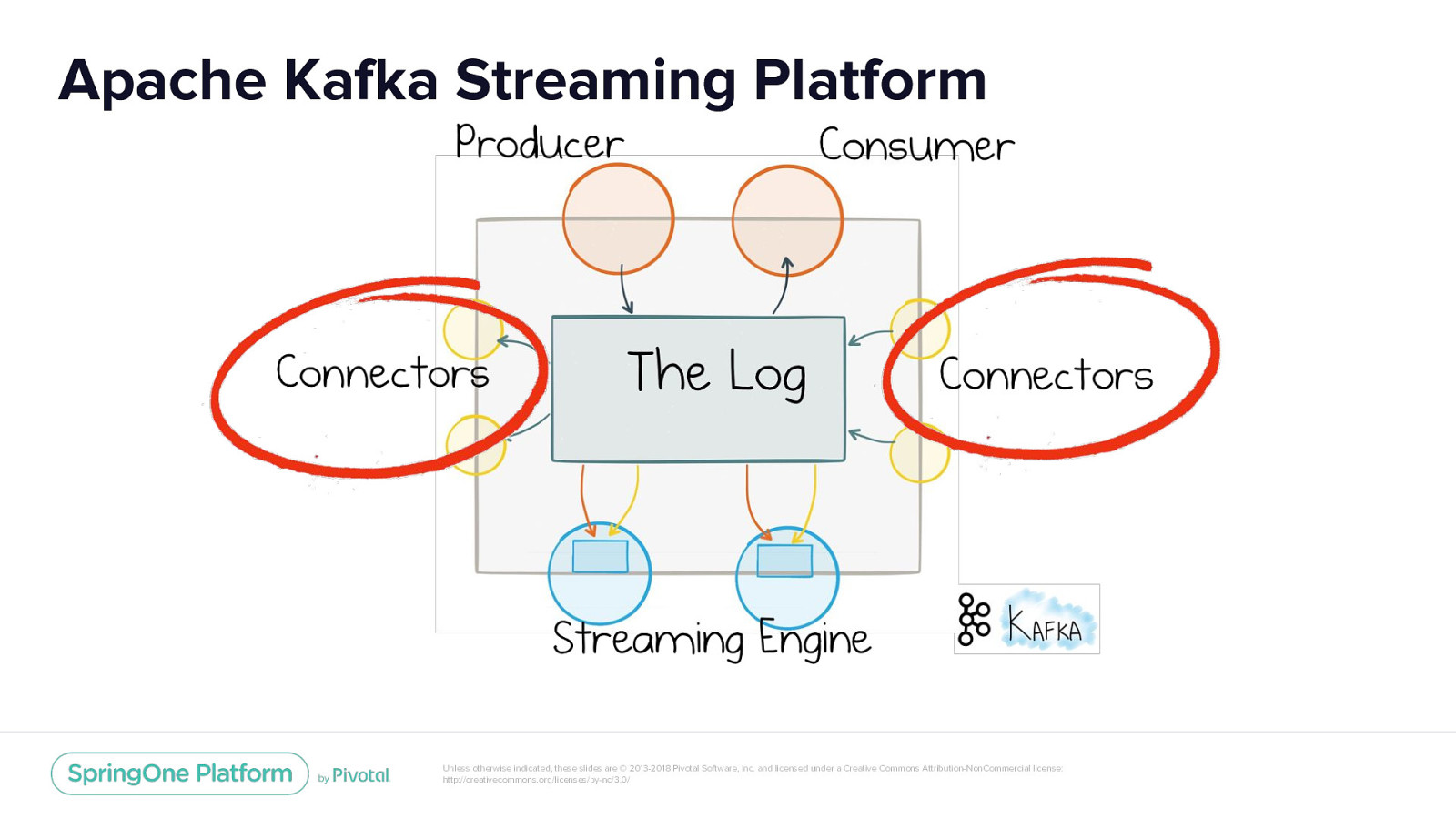
Apache Kafka Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
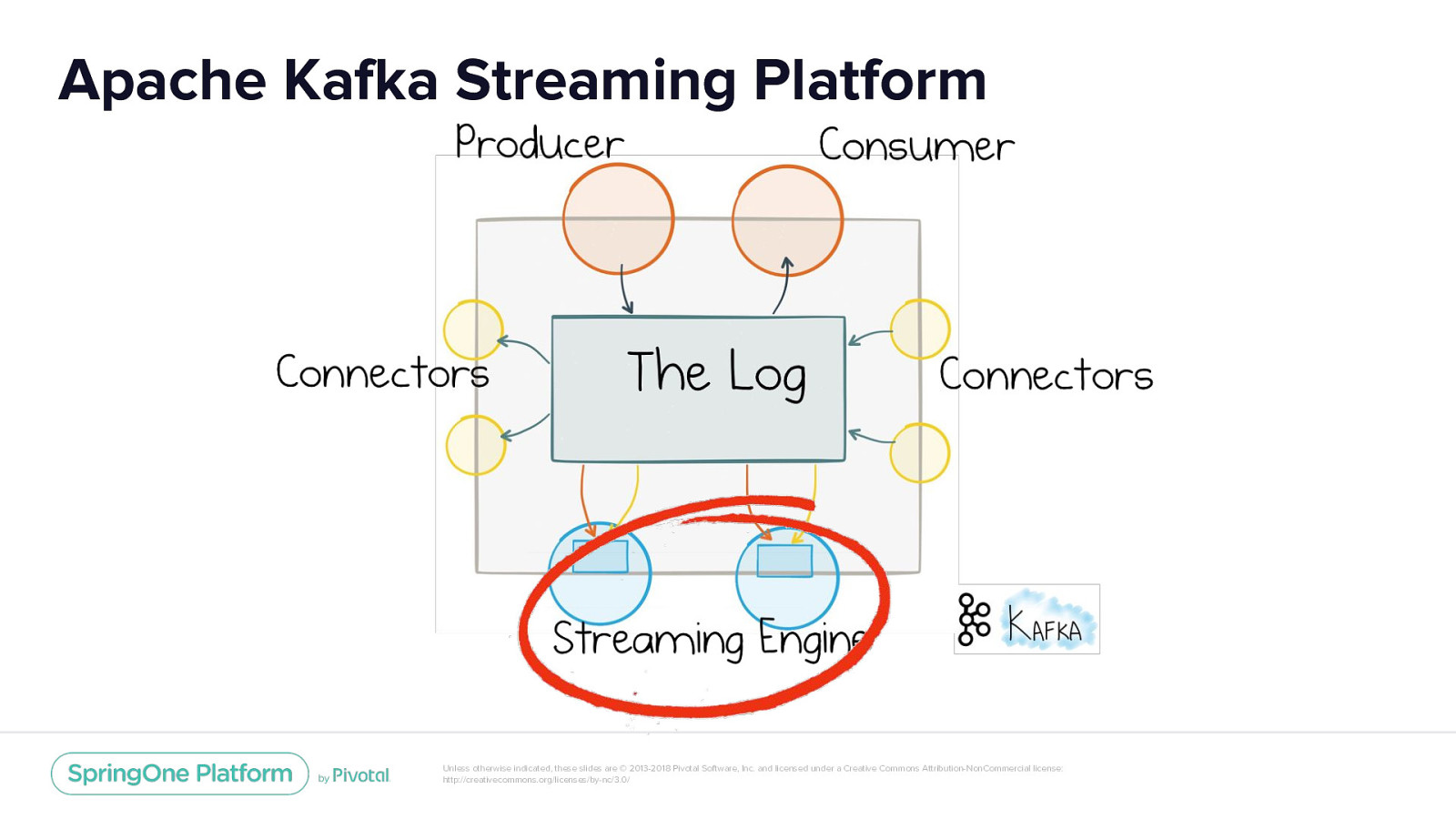
Apache Kafka Streaming Platform Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
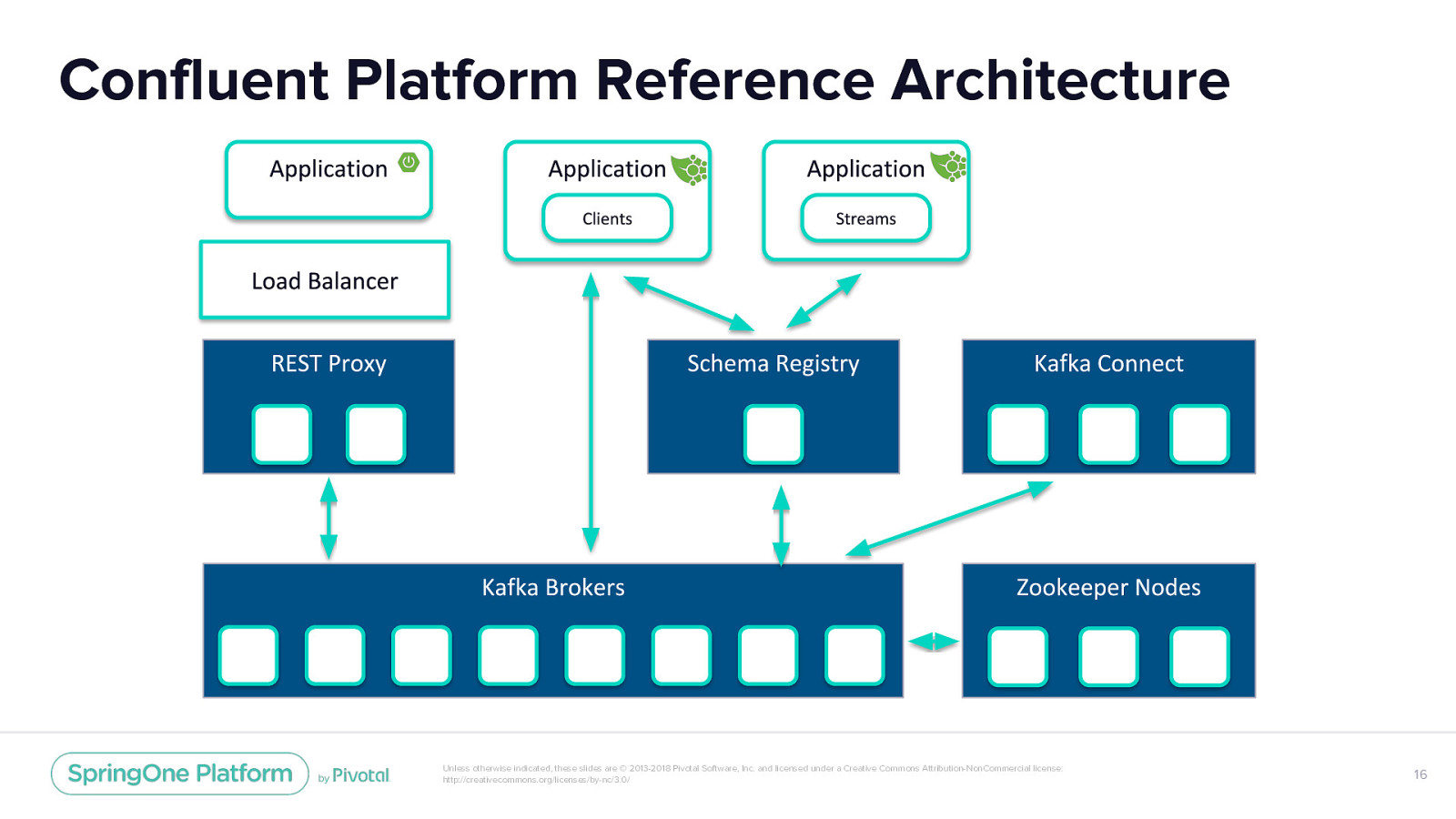
Confluent Platform Reference Architecture Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 16

Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Agenda • • • • • Why do you need a streaming platform Kafka on Kubernetes Pivotal ❤ Kafka Confluent Platform on PKS Demo Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 1 8 
Time check: What year is it? https://twitter.com/sahrizv/status/1018184792611827712 Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Orchestration ● ● ● ● Compute Networking Storage Service Discovery Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
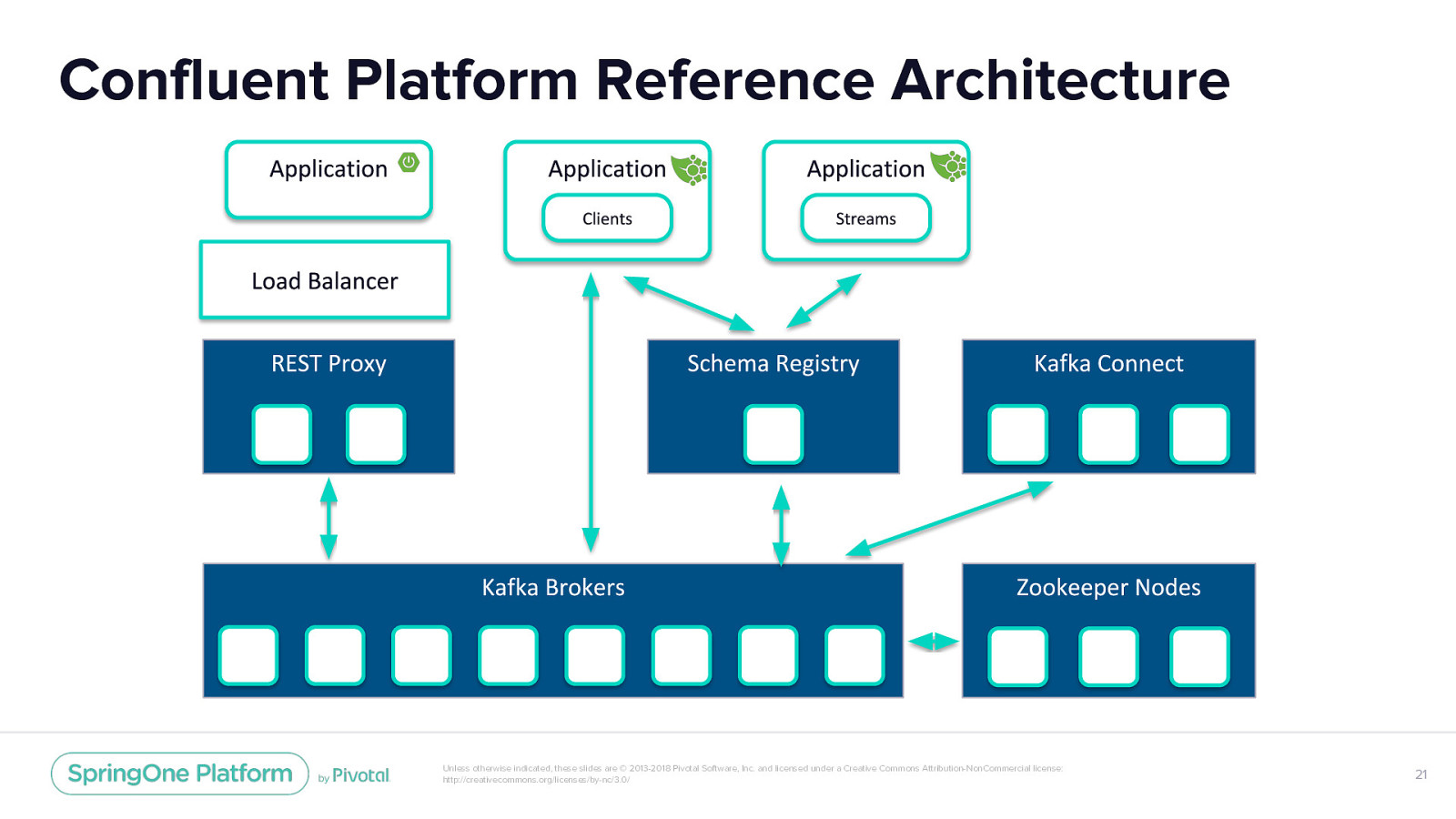
Confluent Platform Reference Architecture Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 21
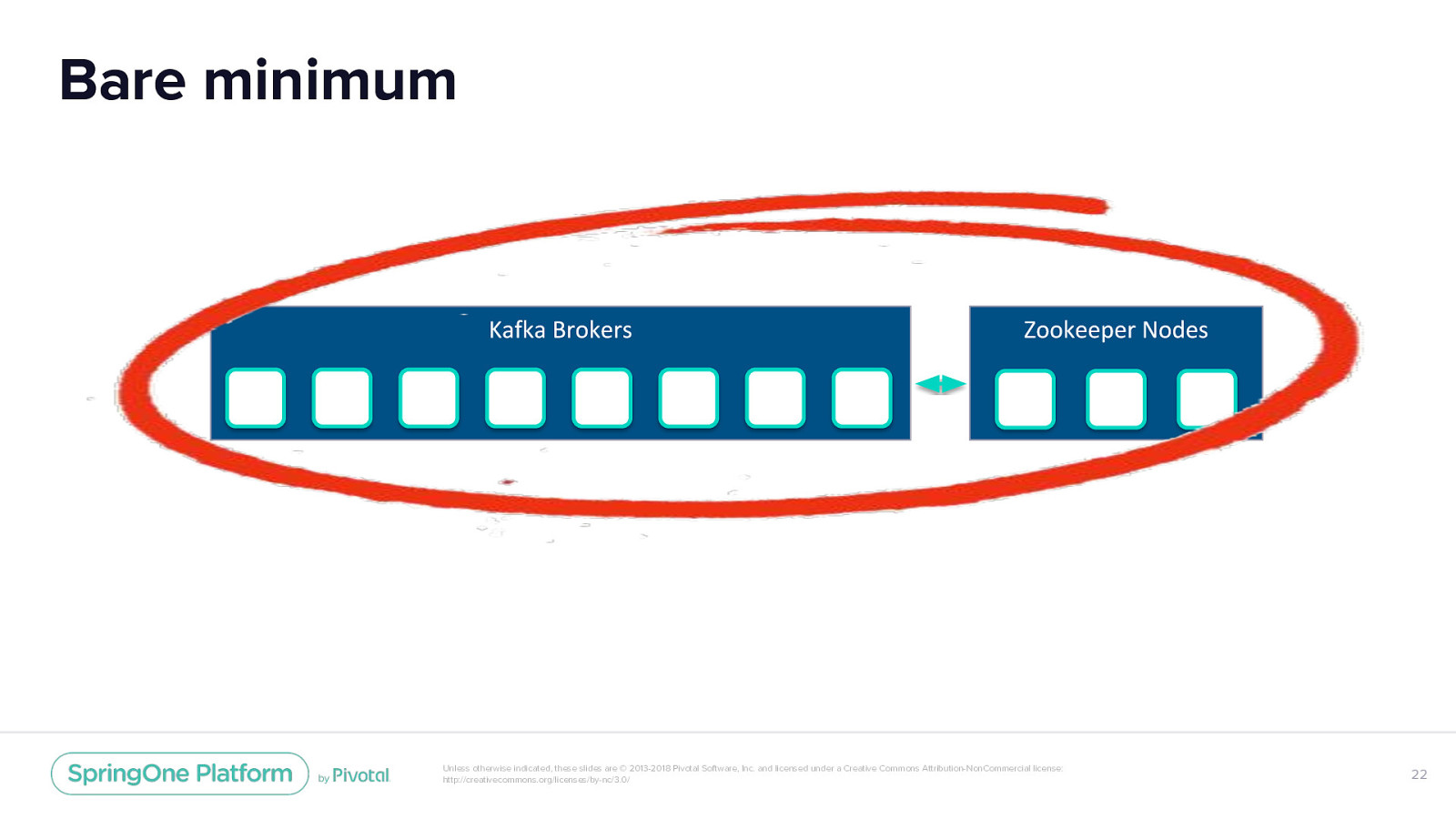
Bare minimum Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 22

Key Constructs for Stateful Workloads Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
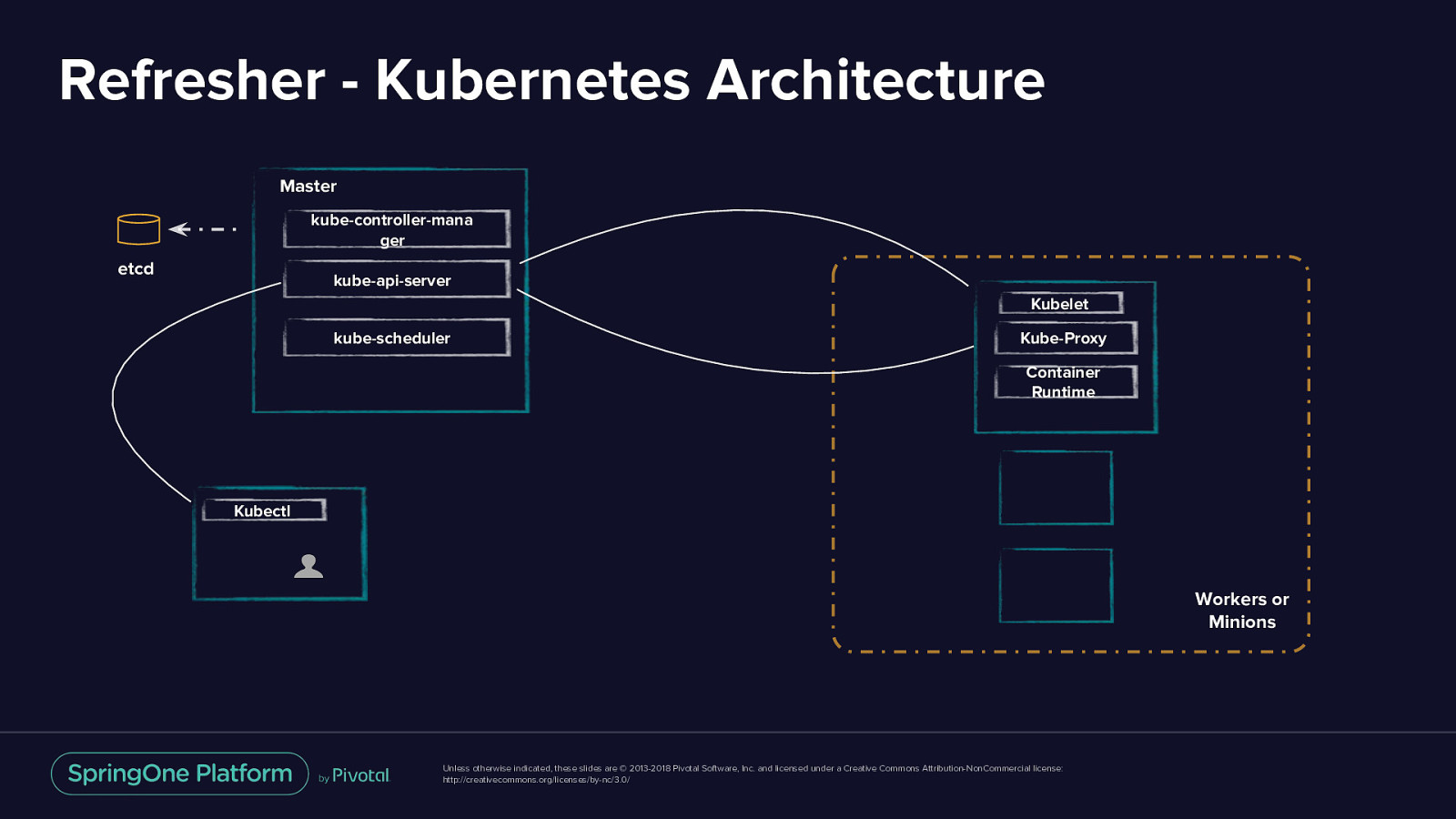
Refresher - Kubernetes Architecture Master kube-controller-mana ger etcd kube-api-server Kubelet kube-scheduler Kube-Proxy Container Runtime Kubectl Workers or Minions Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Pod Basic Unit of Deployment in Kubernetes A collection of containers sharing: • Namespace • Network • Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Pod Containers Volumes

Controller Brain behind Kubernetes resources (core and custom) • e.g. replication controller, namespace controller etc. Controller subscribes to a ‘queue’ and will handle 3 types of events: Add, Update and Delete Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
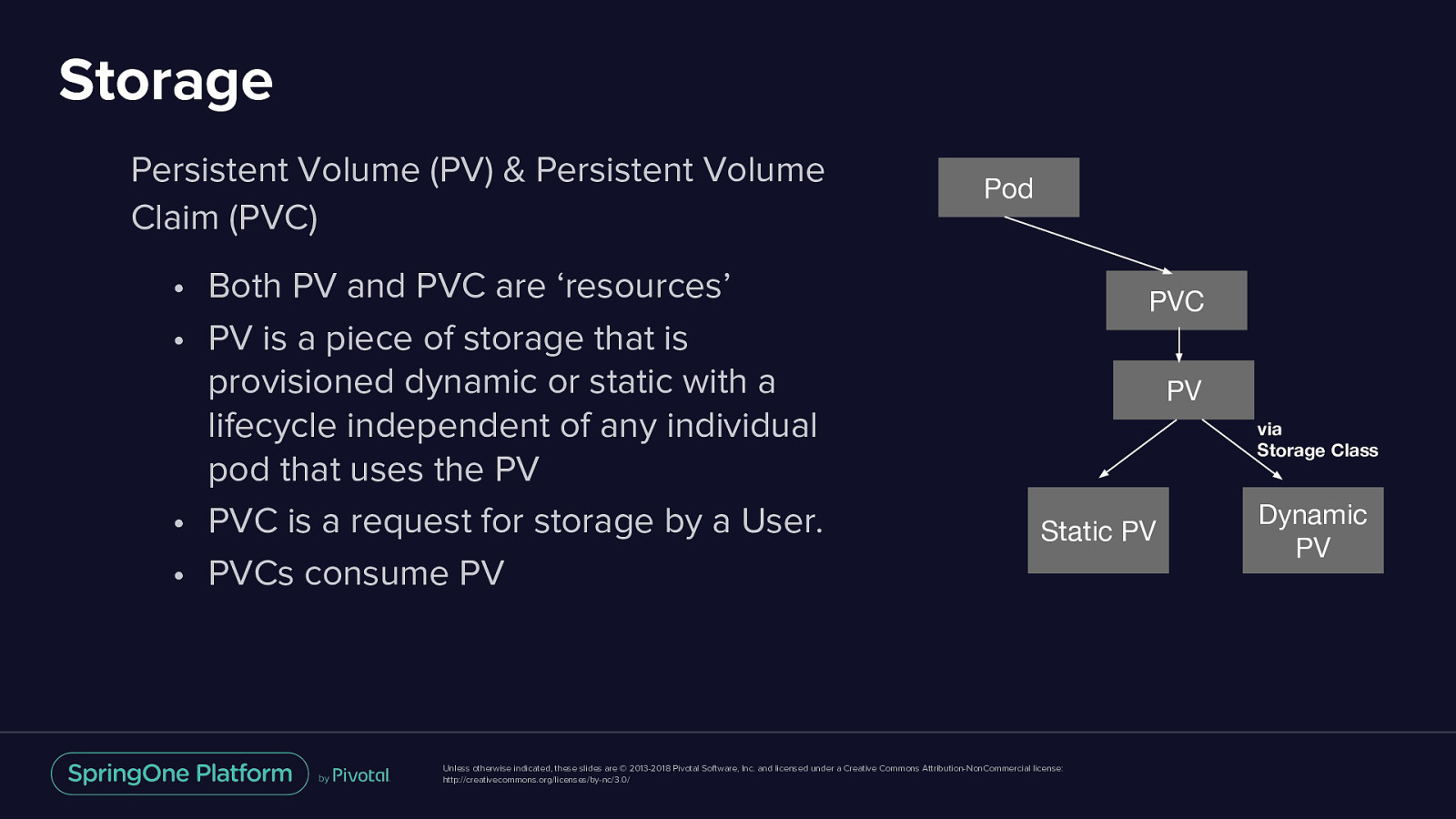
Storage Persistent Volume (PV) & Persistent Volume Claim (PVC) • Both PV and PVC are ‘resources’ • PV is a piece of storage that is provisioned dynamic or static with a lifecycle independent of any individual pod that uses the PV • PVC is a request for storage by a User. • PVCs consume PV Pod PVC PV via Storage Class Static PV Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Dynamic PV

Storage Persistent Volume (PV) & Persistent Volume Claim (PVC) • PV and PVC are ‘resources’ Pod PVC PV via Storage Class Static PV Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Dynamic PV

Storage PV is a piece of storage that is provisioned dynamic or static with a lifecycle independent of any individual pod that uses the PV Pod PVC PV via Storage Class Static PV Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Dynamic PV

Storage PVC is a request for storage by a User Pod PVC PV via Storage Class Static PV Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Dynamic PV
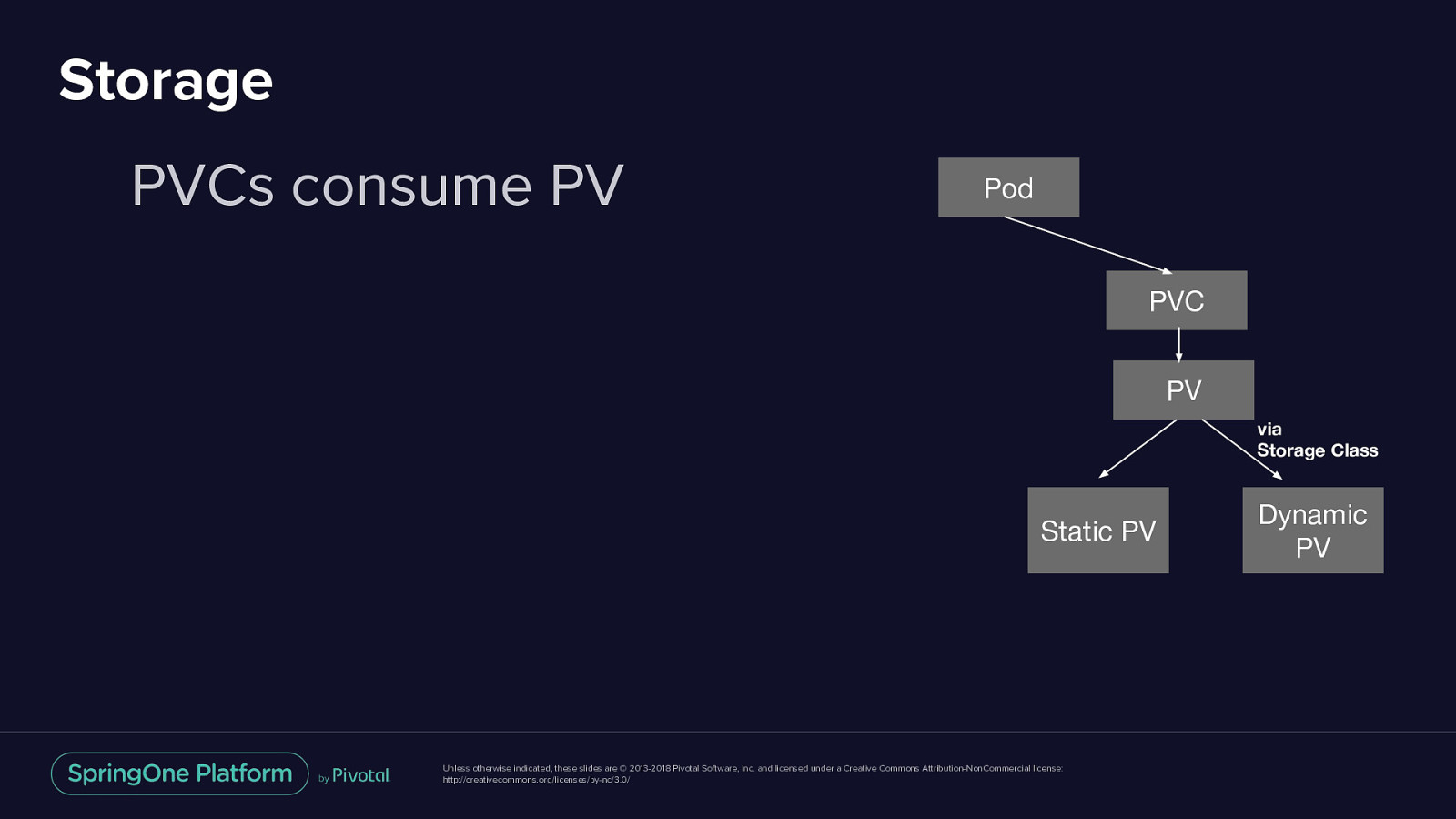
Storage PVCs consume PV Pod PVC PV via Storage Class Static PV Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ Dynamic PV
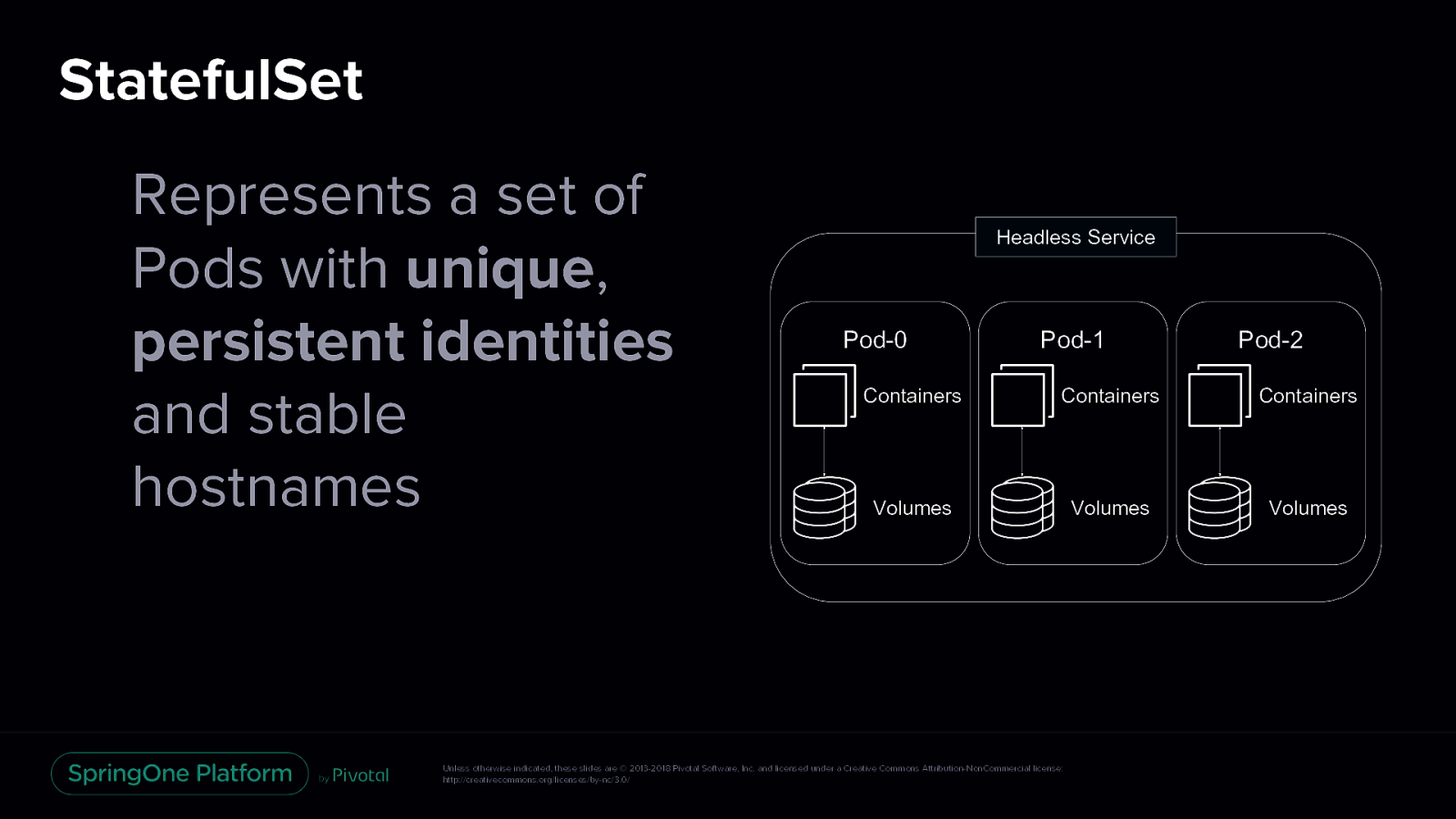
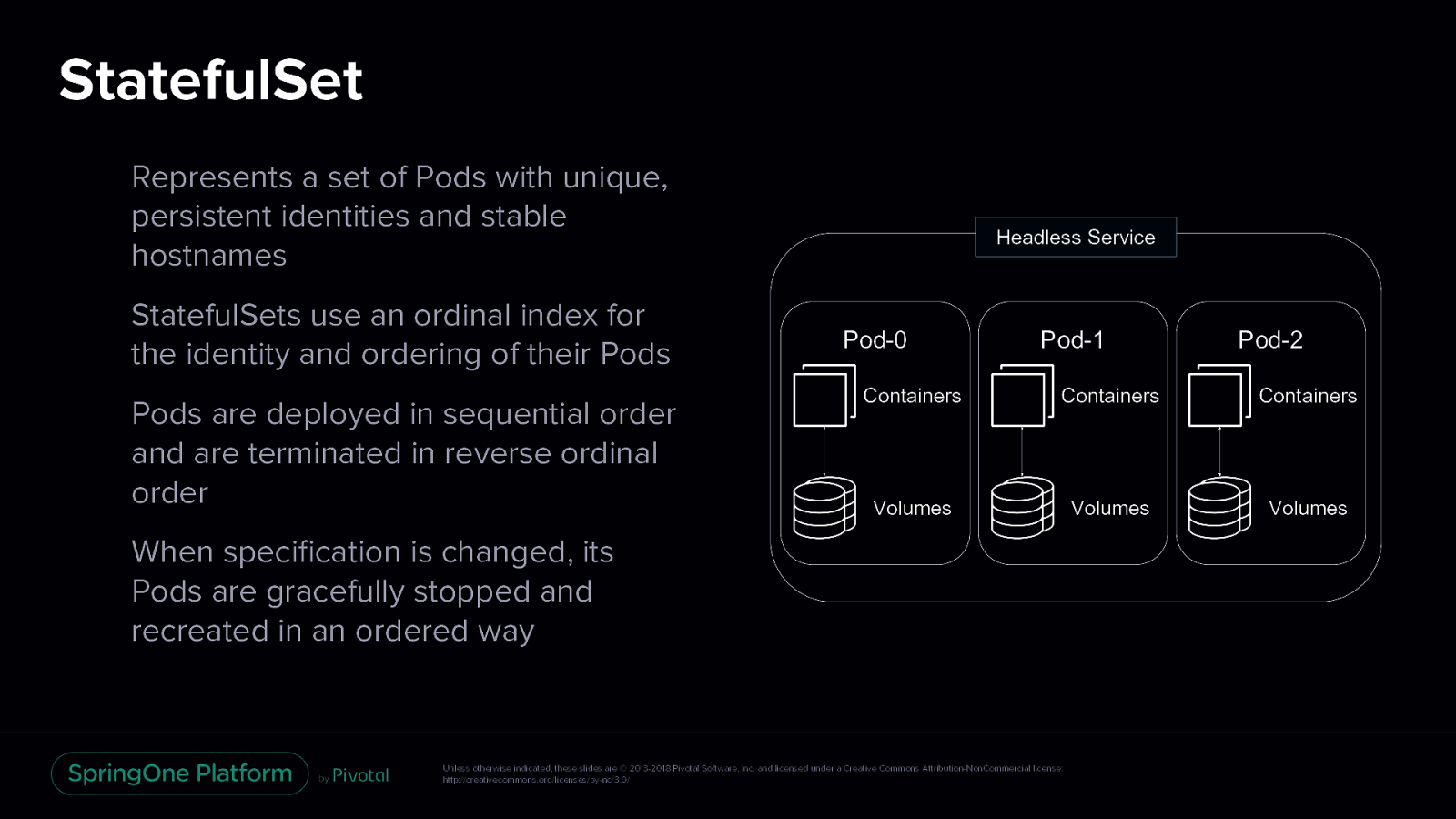
StatefulSet Represents a set of Pods with unique, persistent identities and stable hostnames Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

StatefulSet StatefulSets use an ordinal index for the identity and ordering of their Pods Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
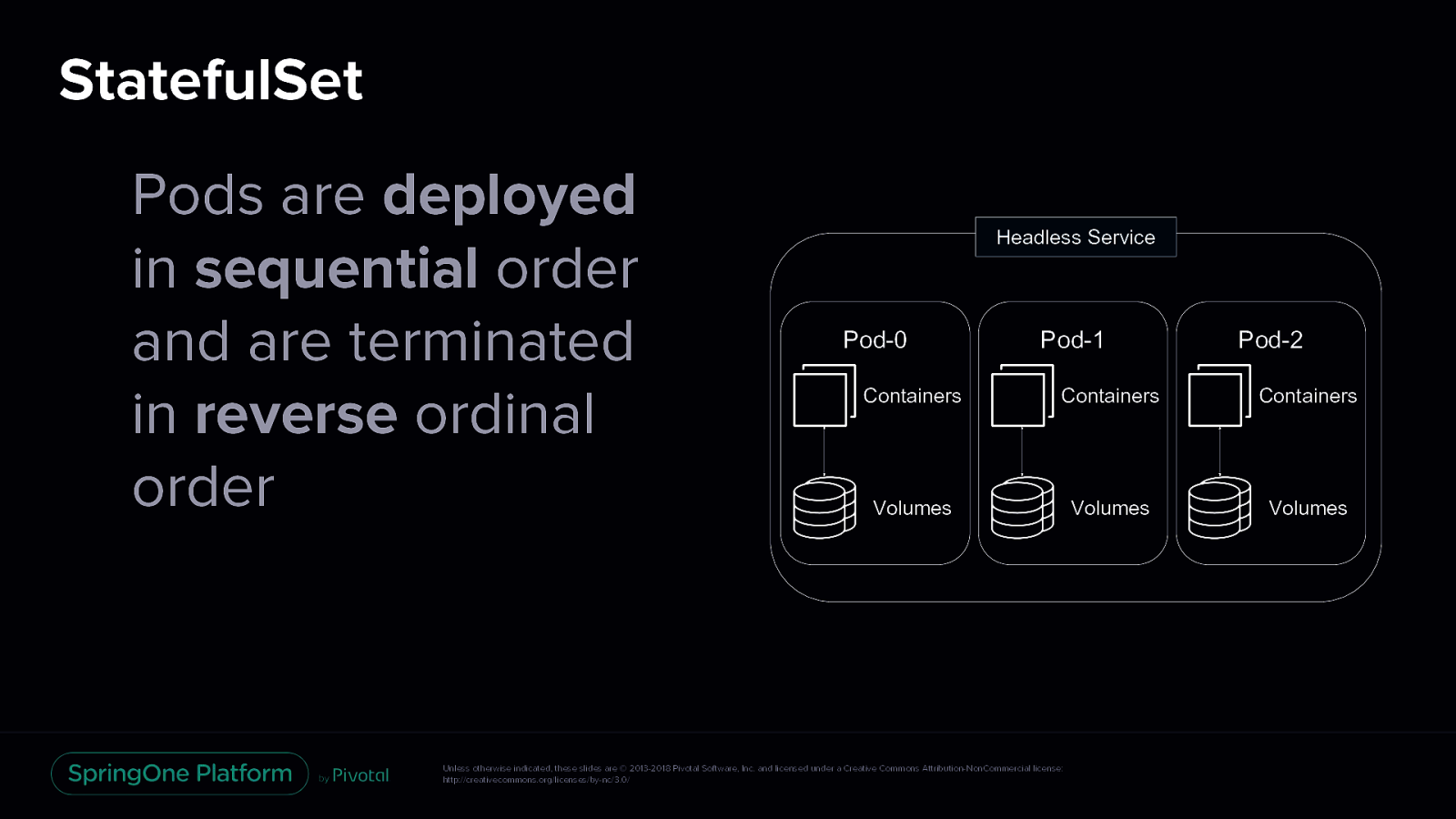
StatefulSet Pods are deployed in sequential order and are terminated in reverse ordinal order Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
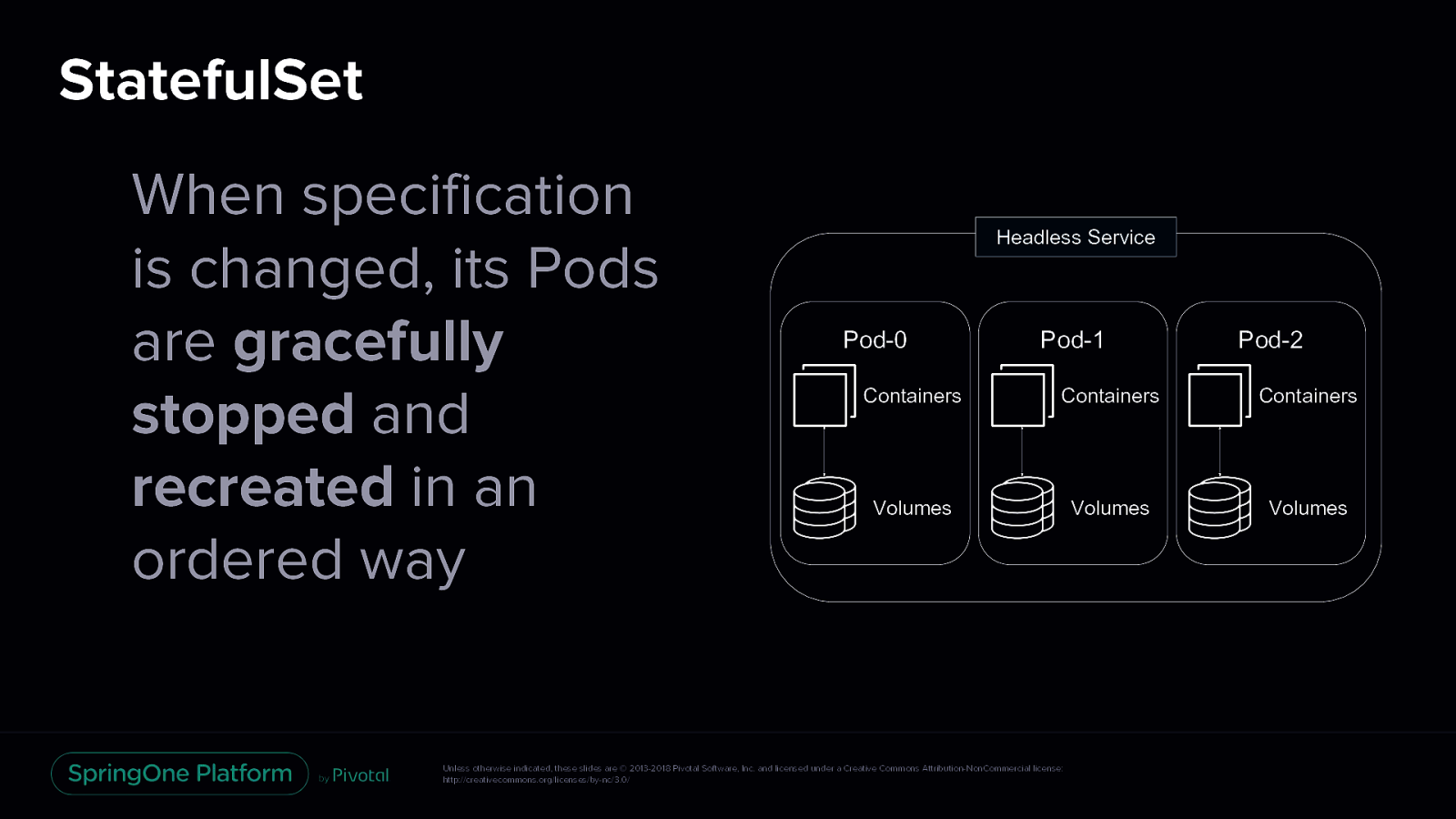
StatefulSet When specification is changed, its Pods are gracefully stopped and recreated in an ordered way Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
StatefulSet Represents a set of Pods with unique, persistent identities and stable hostnames StatefulSets use an ordinal index for the identity and ordering of their Pods Pods are deployed in sequential order and are terminated in reverse ordinal order Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes When specification is changed, its Pods are gracefully stopped and recreated in an ordered way Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
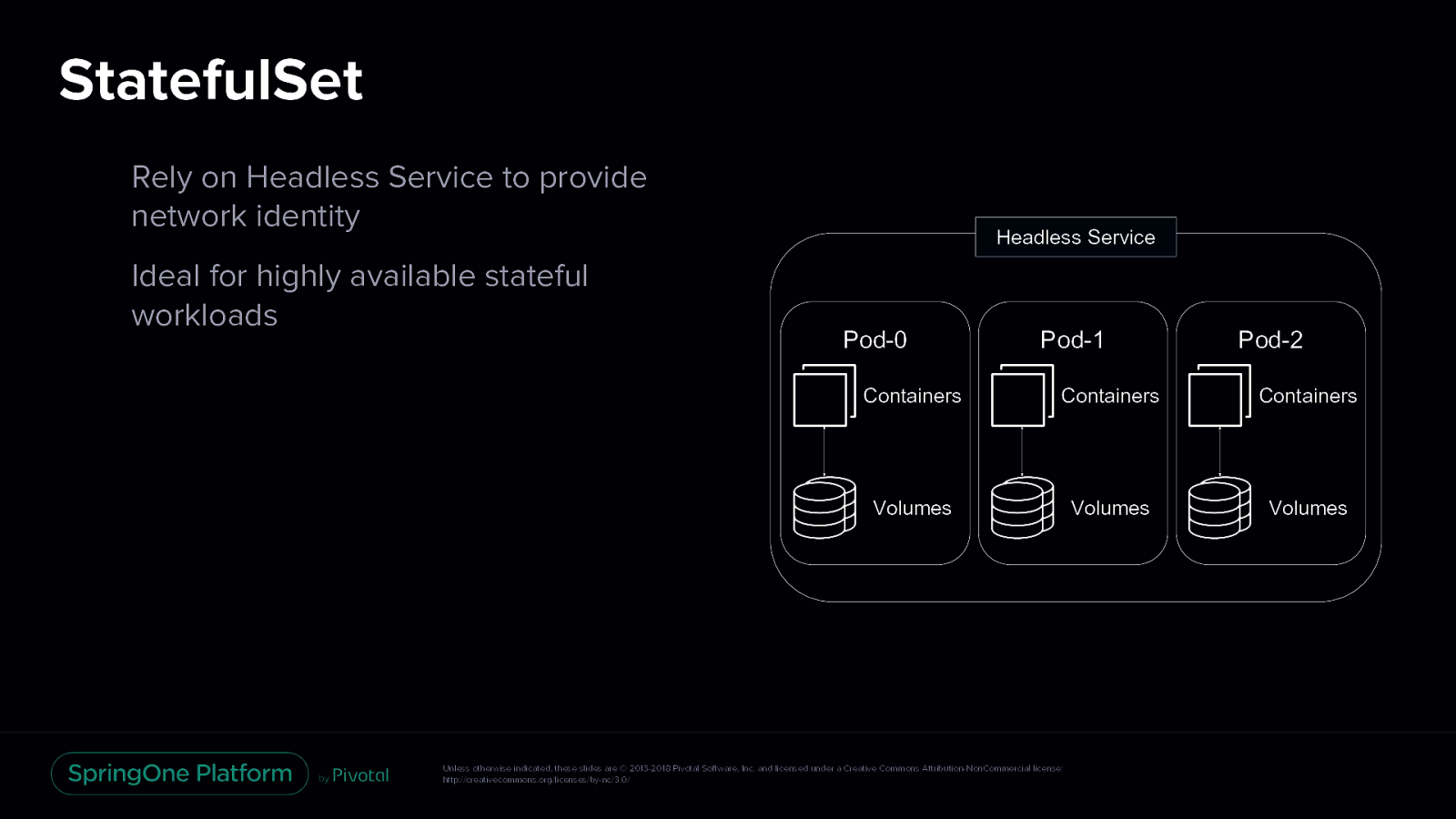
StatefulSet Rely on Headless Service to provide network identity Ideal for highly available stateful workloads Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
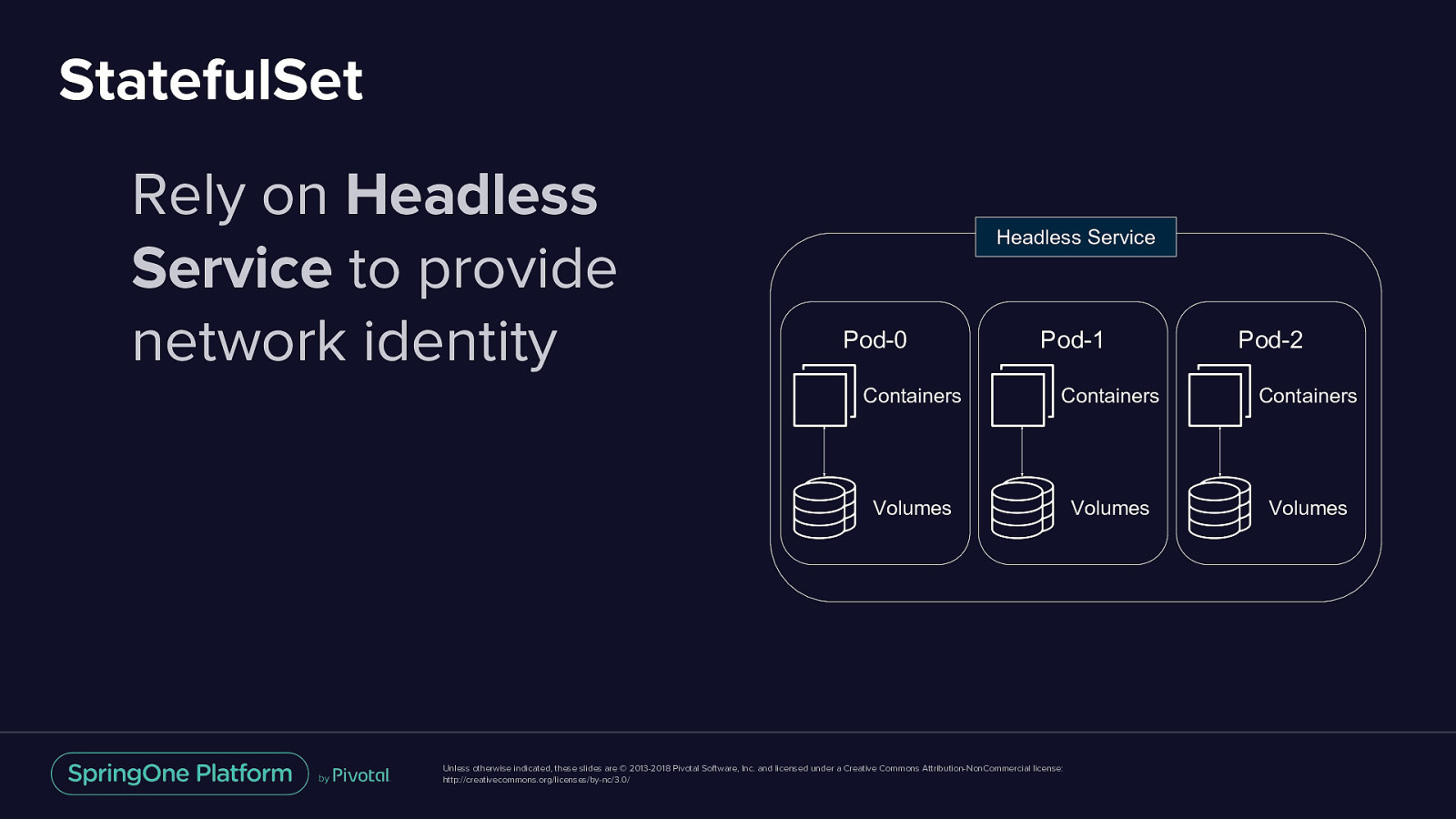
StatefulSet Rely on Headless Service to provide network identity Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
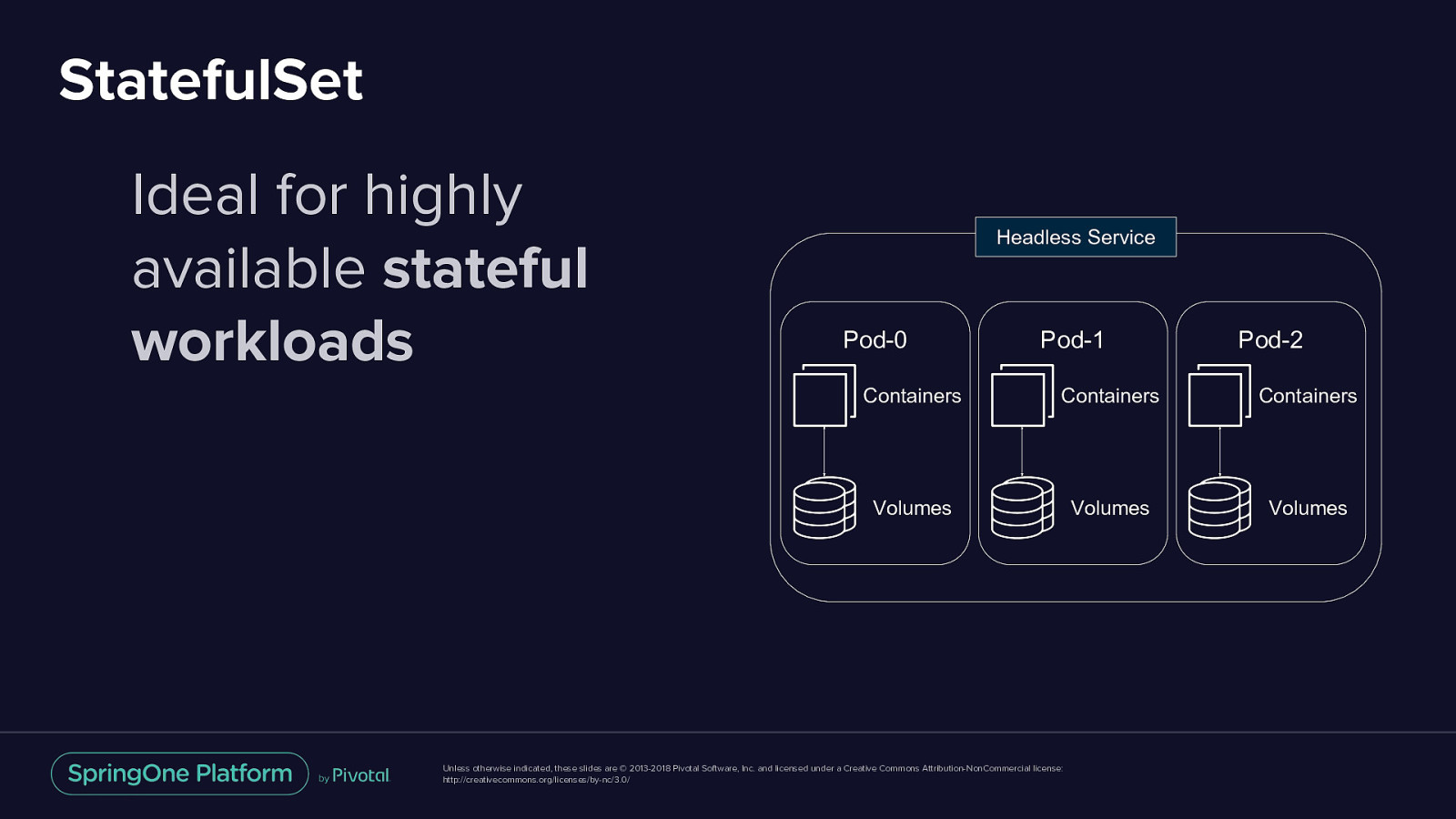
StatefulSet Ideal for highly available stateful workloads Headless Service Pod-0 Pod-1 Pod-2 Containers Containers Containers Volumes Volumes Volumes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
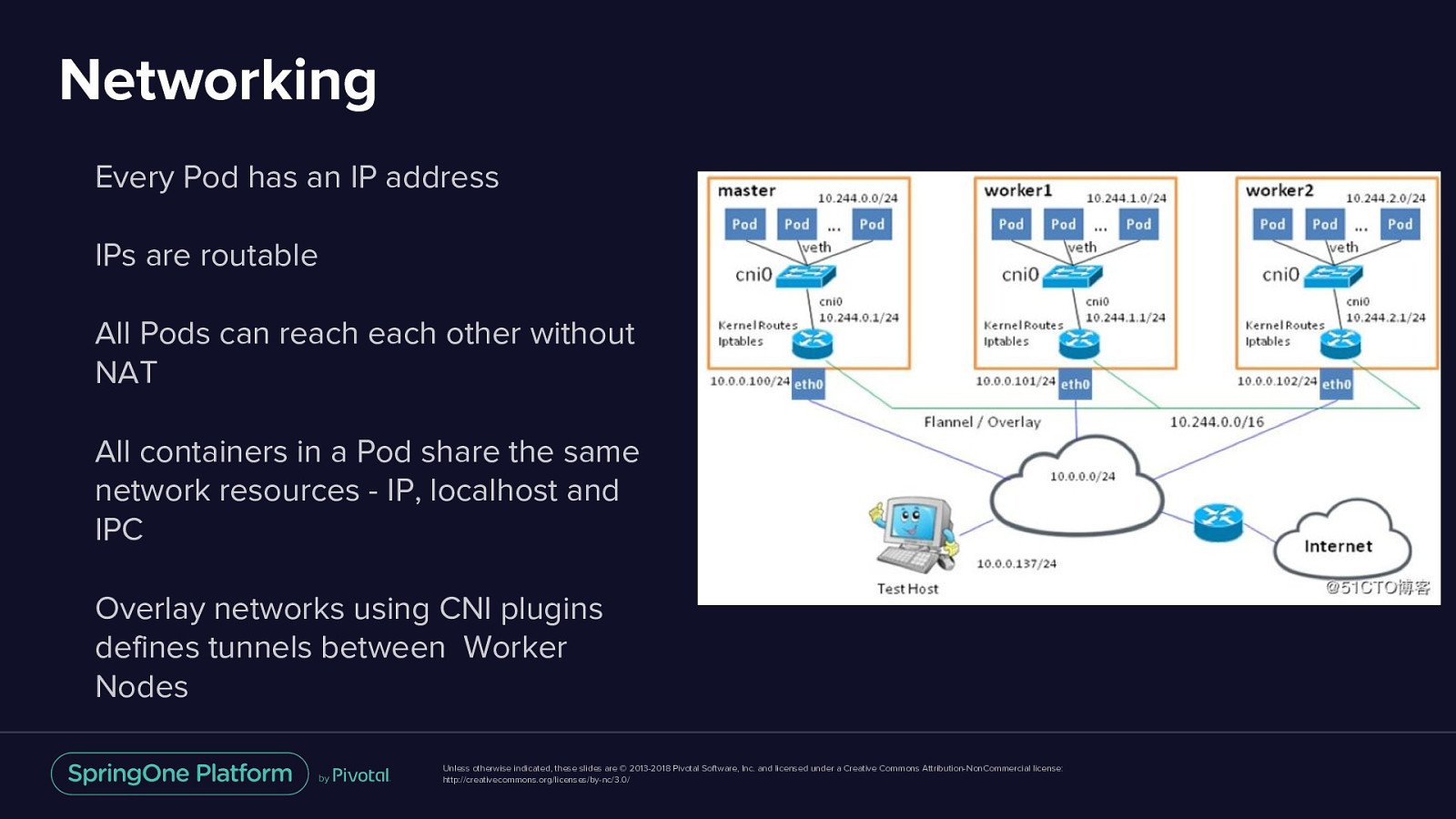
Networking Every Pod has an IP address IPs are routable All Pods can reach each other without NAT All containers in a Pod share the same network resources - IP, localhost and IPC Overlay networks using CNI plugins defines tunnels between Worker Nodes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
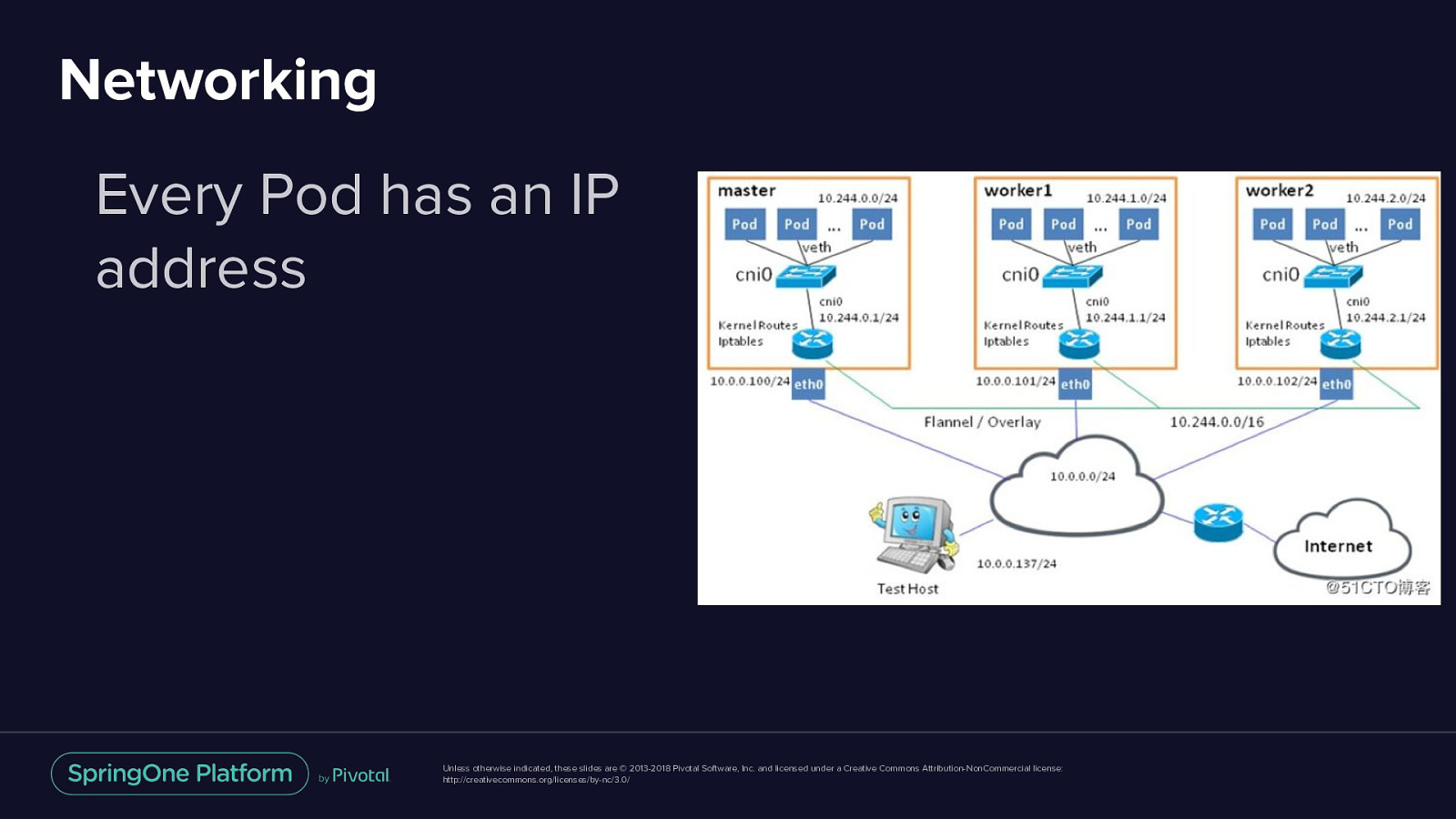
Networking Every Pod has an IP address Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
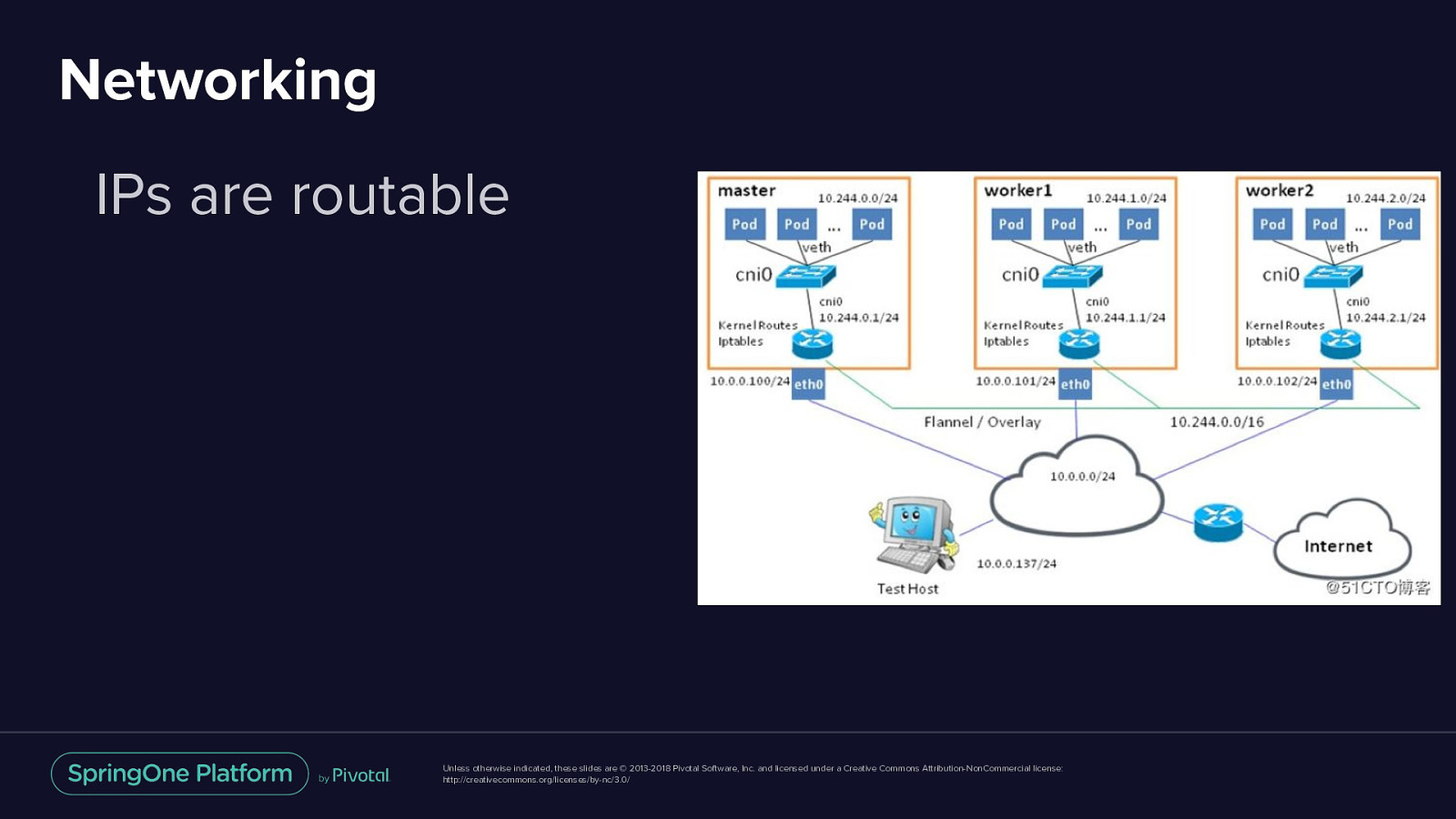
Networking IPs are routable Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
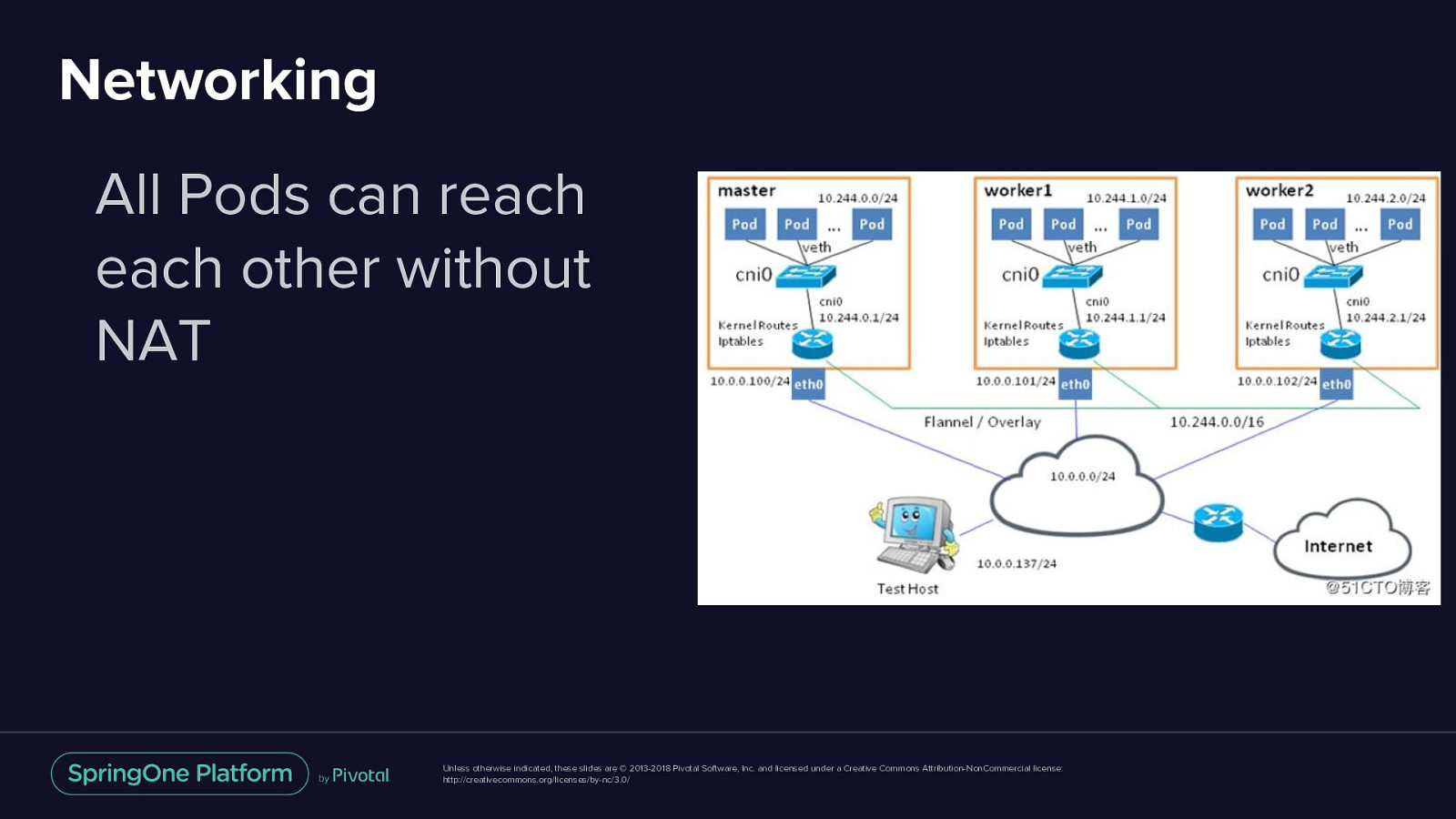
Networking All Pods can reach each other without NAT Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
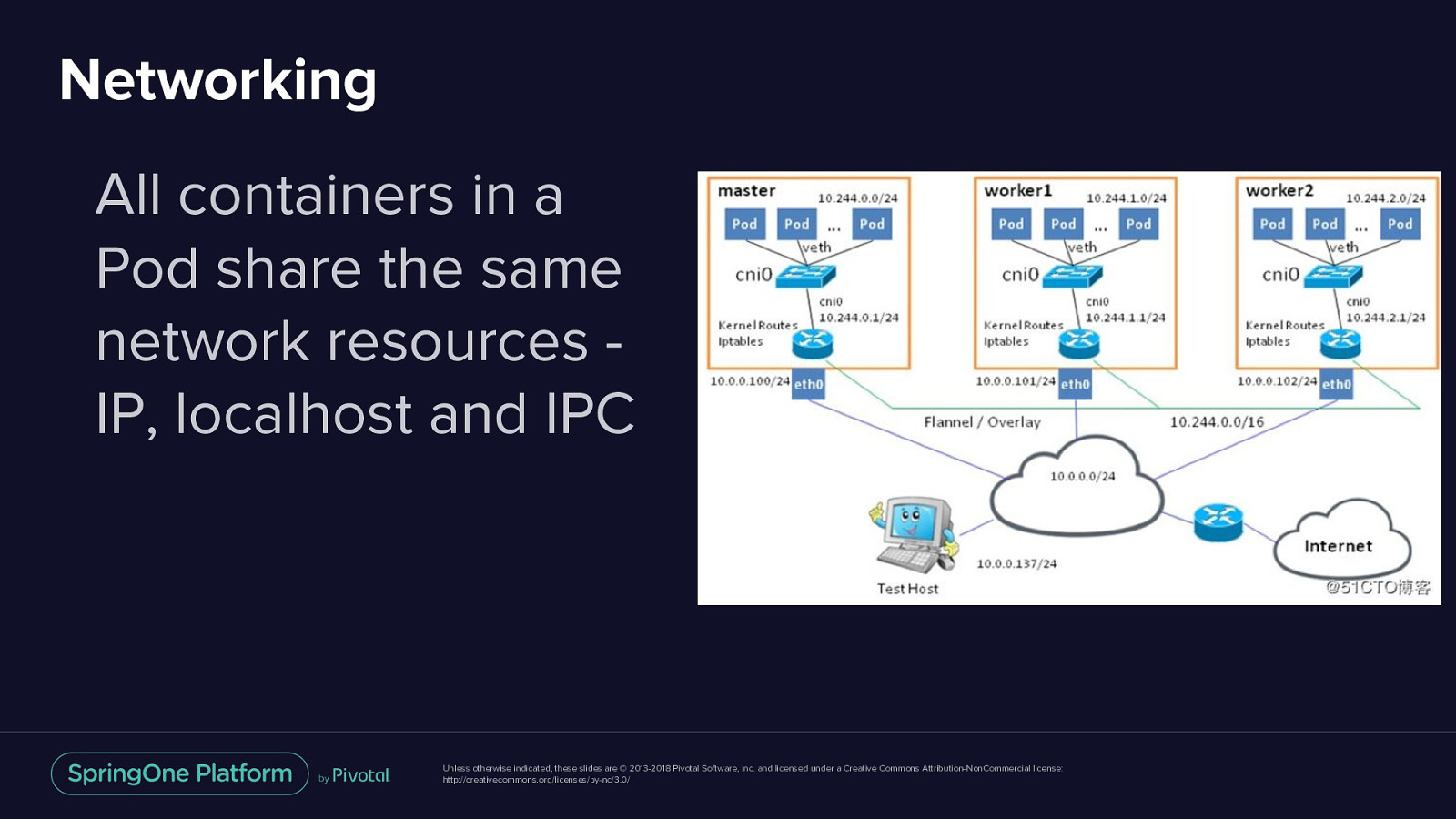
Networking All containers in a Pod share the same network resources IP, localhost and IPC Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
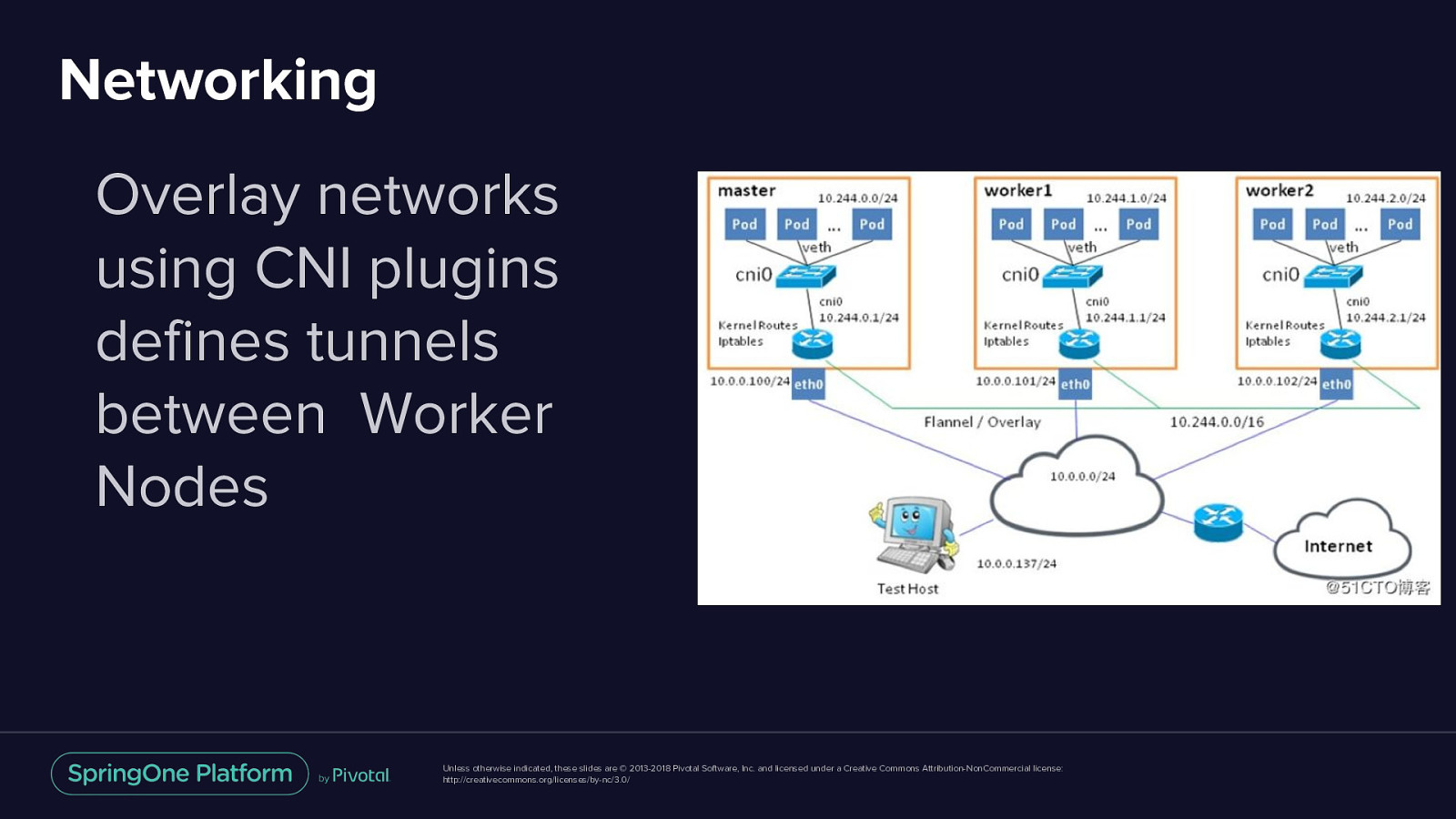
Networking Overlay networks using CNI plugins defines tunnels between Worker Nodes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Custom Resource Definition(CRD) Extend existing Kubernetes API Usually works together Custom Controller (operator pattern) Users can create and access Customer Resources(CRs) with kubectl, just as they do for built-in resources like pods. API StatefulSet ReplicaSet ... CRD Controller StatefulSet Controller ReplicaSet Controller ... Custom Controller ReplicaSet ... Custom Resource Instance StatefulSet Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Workload Deployments Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
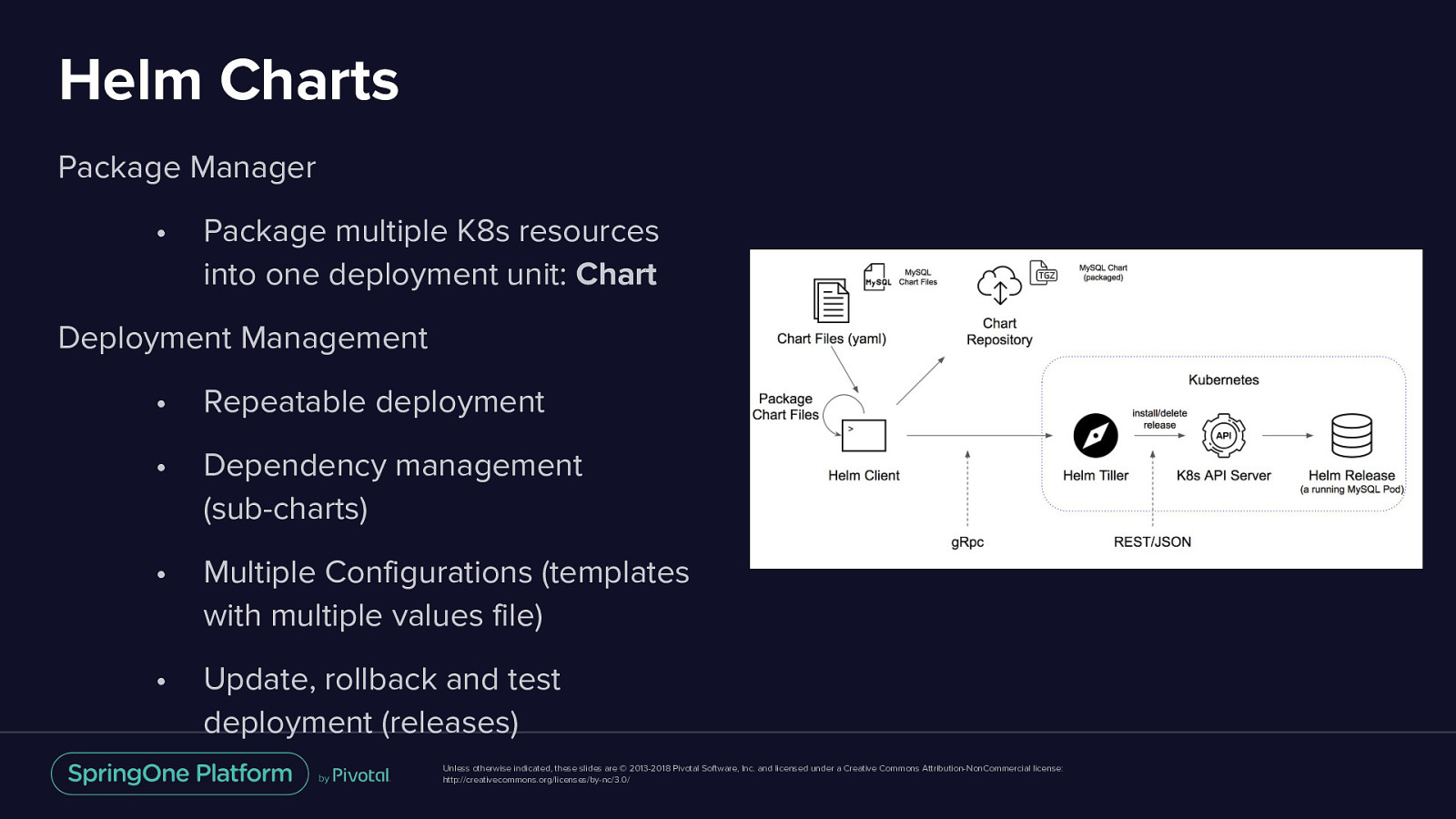
Helm Charts Package Manager • Package multiple K8s resources into one deployment unit: Chart Deployment Management • Repeatable deployment • Dependency management (sub-charts) • Multiple Configurations (templates with multiple values file) • Update, rollback and test deployment (releases) Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
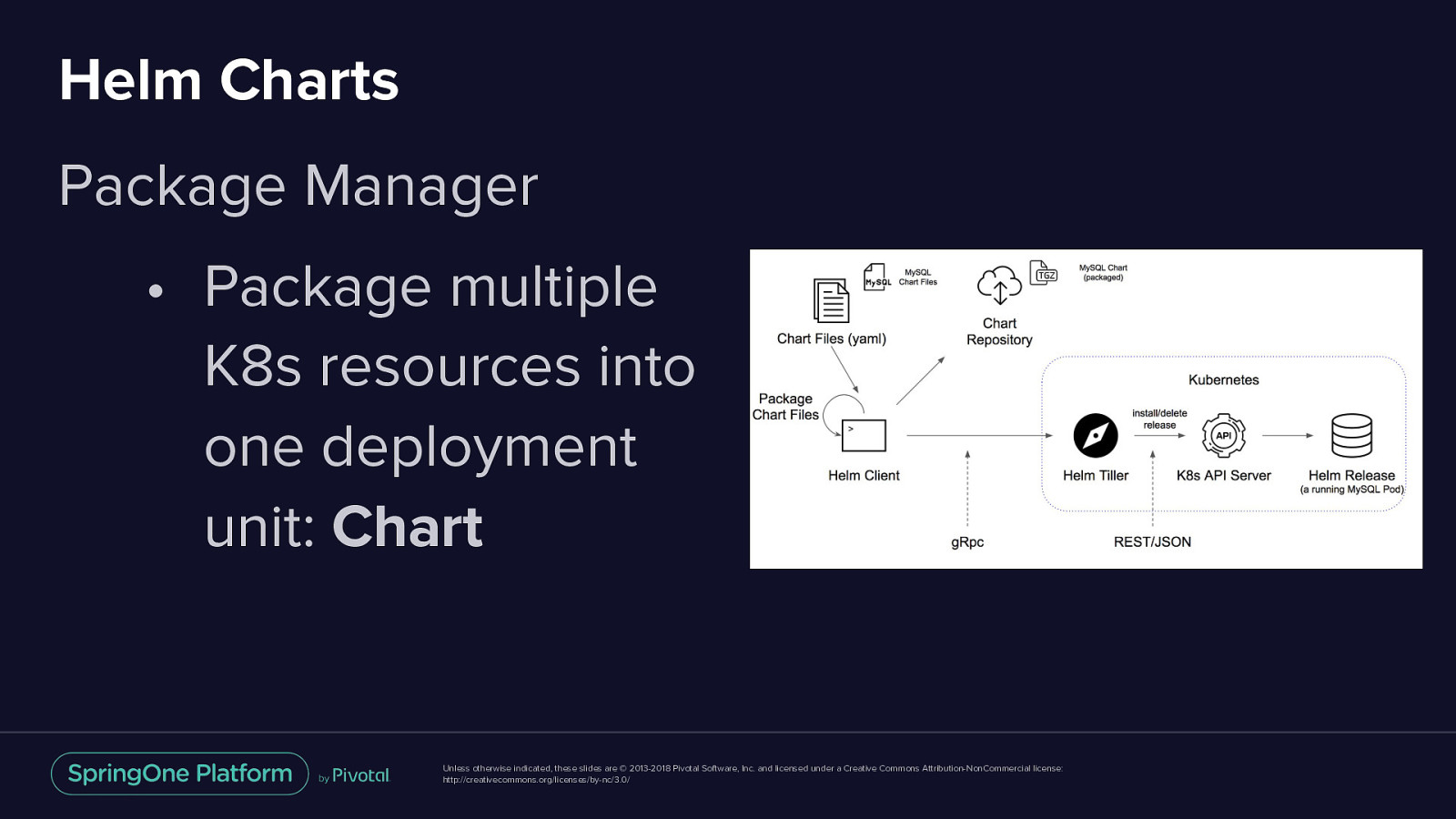
Helm Charts Package Manager • Package multiple K8s resources into one deployment unit: Chart Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
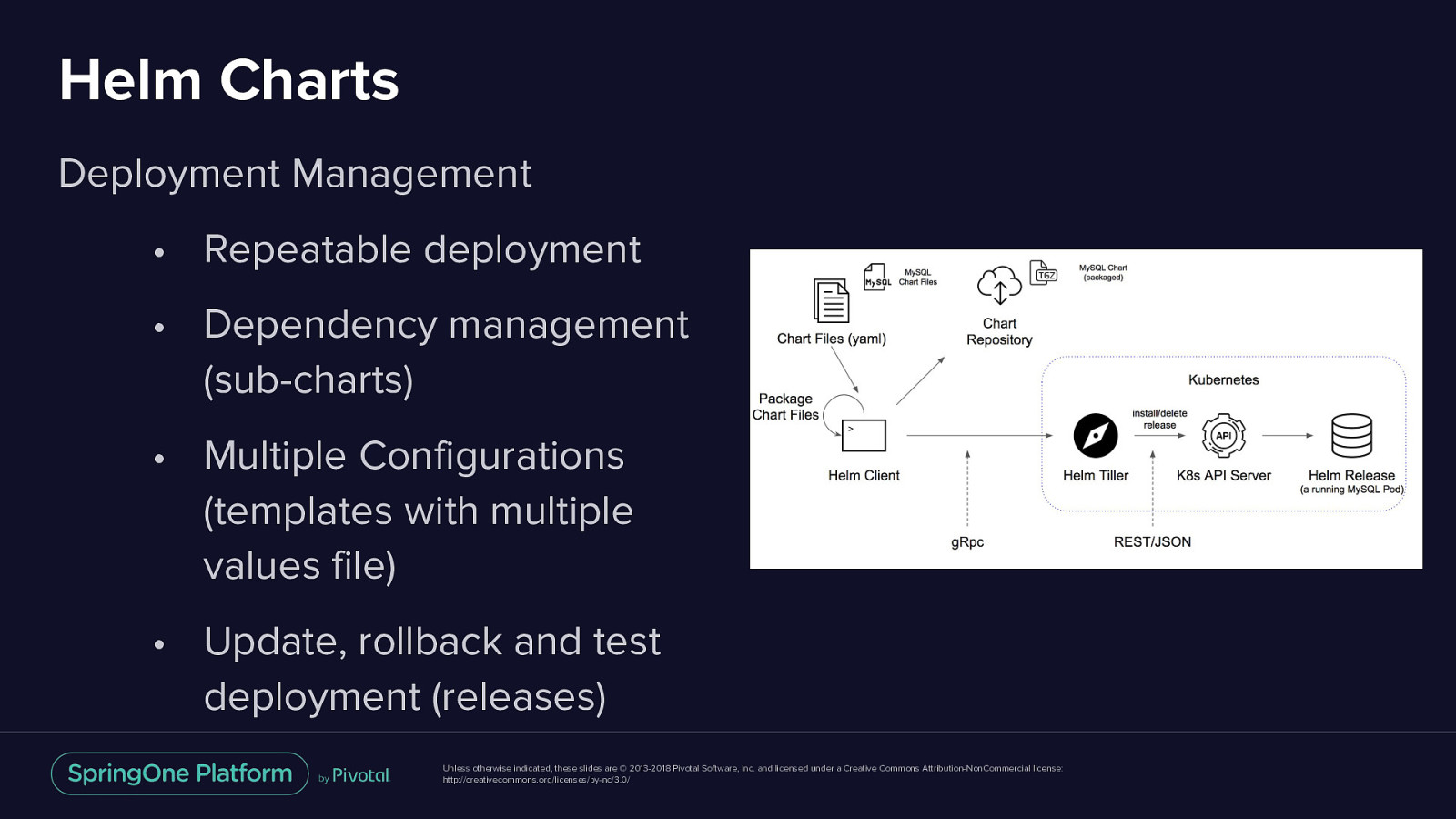
Helm Charts Deployment Management • Repeatable deployment • Dependency management (sub-charts) • Multiple Configurations (templates with multiple values file) • Update, rollback and test deployment (releases) Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Helm Charts Deployment Management • Repeatable deployment Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Helm Charts Deployment Management • Dependency management (sub-charts) Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Helm Charts Deployment Management • Multiple Configurations (templates with multiple values file) Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Helm Charts Deployment Management • Update, rollback and test deployment (releases) Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
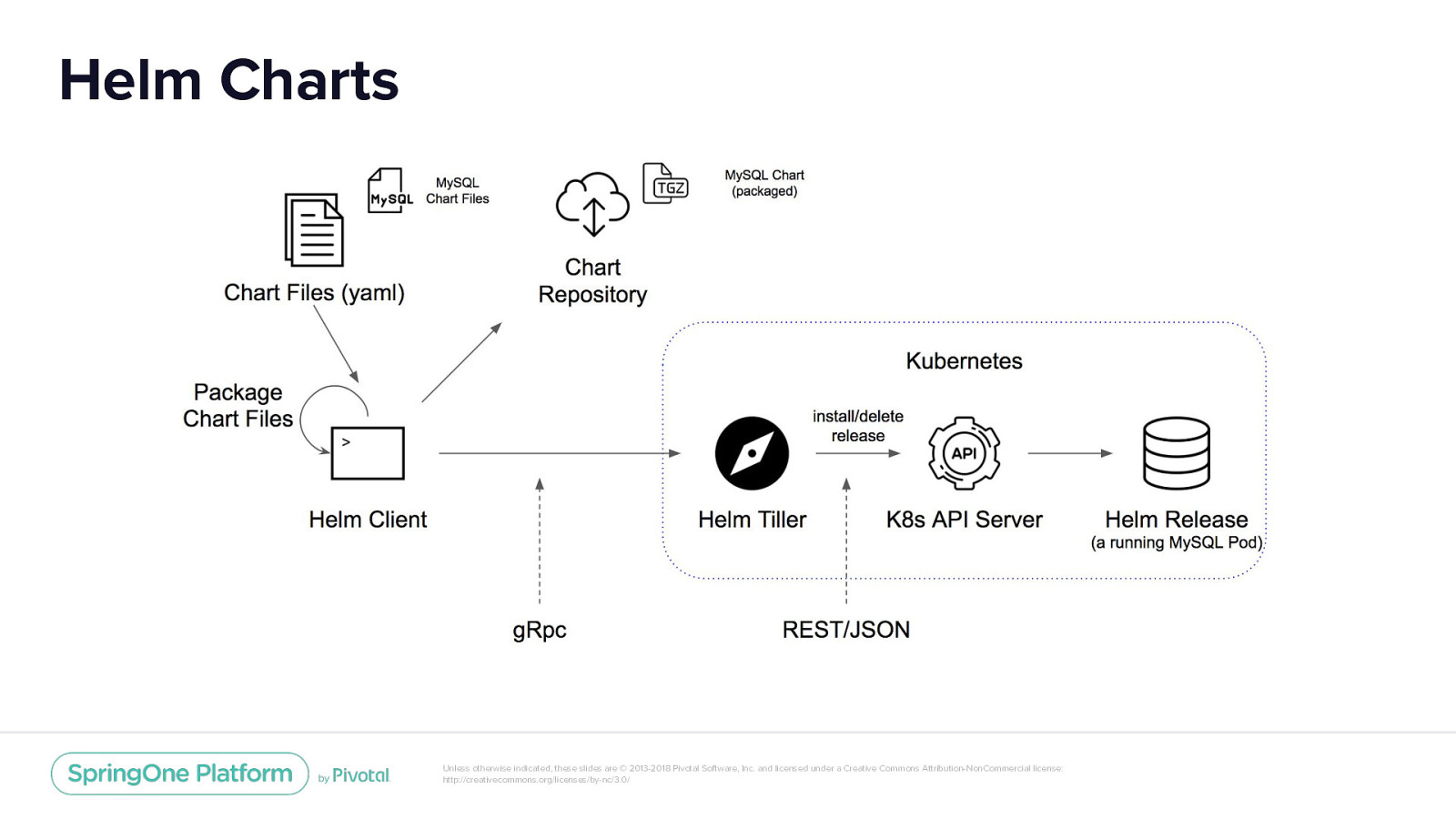
Helm Charts Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
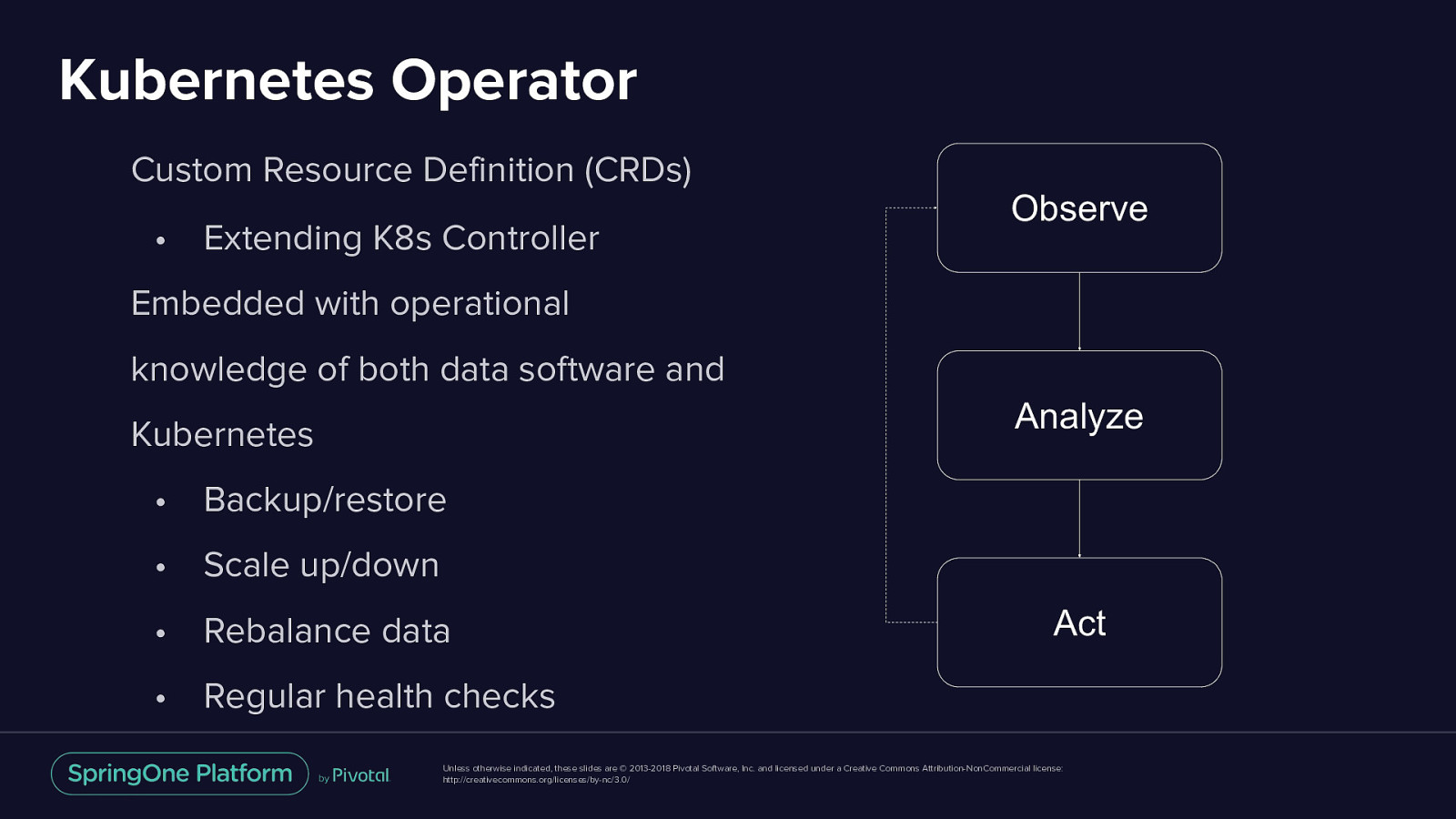
Kubernetes Operator Custom Resource Definition (CRDs) • Extending K8s Controller Observe Embedded with operational knowledge of both data software and Analyze Kubernetes • Backup/restore • Scale up/down • Rebalance data Act • Regular health checks Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
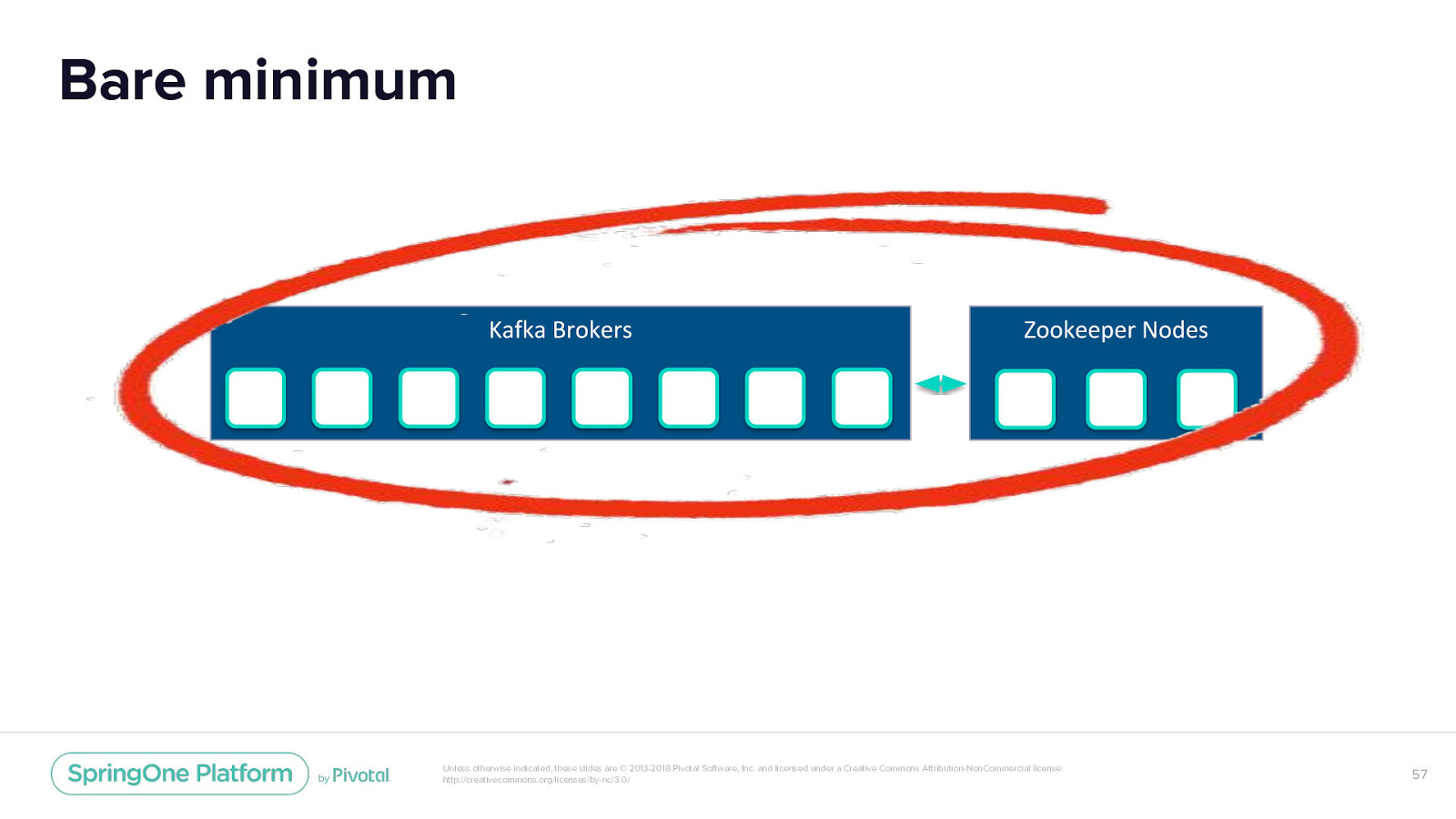
Bare minimum Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 57

ZK & Kafka install ZooKeeper Kafka PVC for Storage Uses ZK Headless Svc StatefulSet for 3-node zk PVC for Storage Optional Pod Anti-Affinity to spread the ZK ensemble across nodes. StatefulSet for n-node Kafka Headless Service A group of NodePort Services for external traffic ConfigMap for Prometheus JMX exporter ConfigMap for Prometheus JMX exporter Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
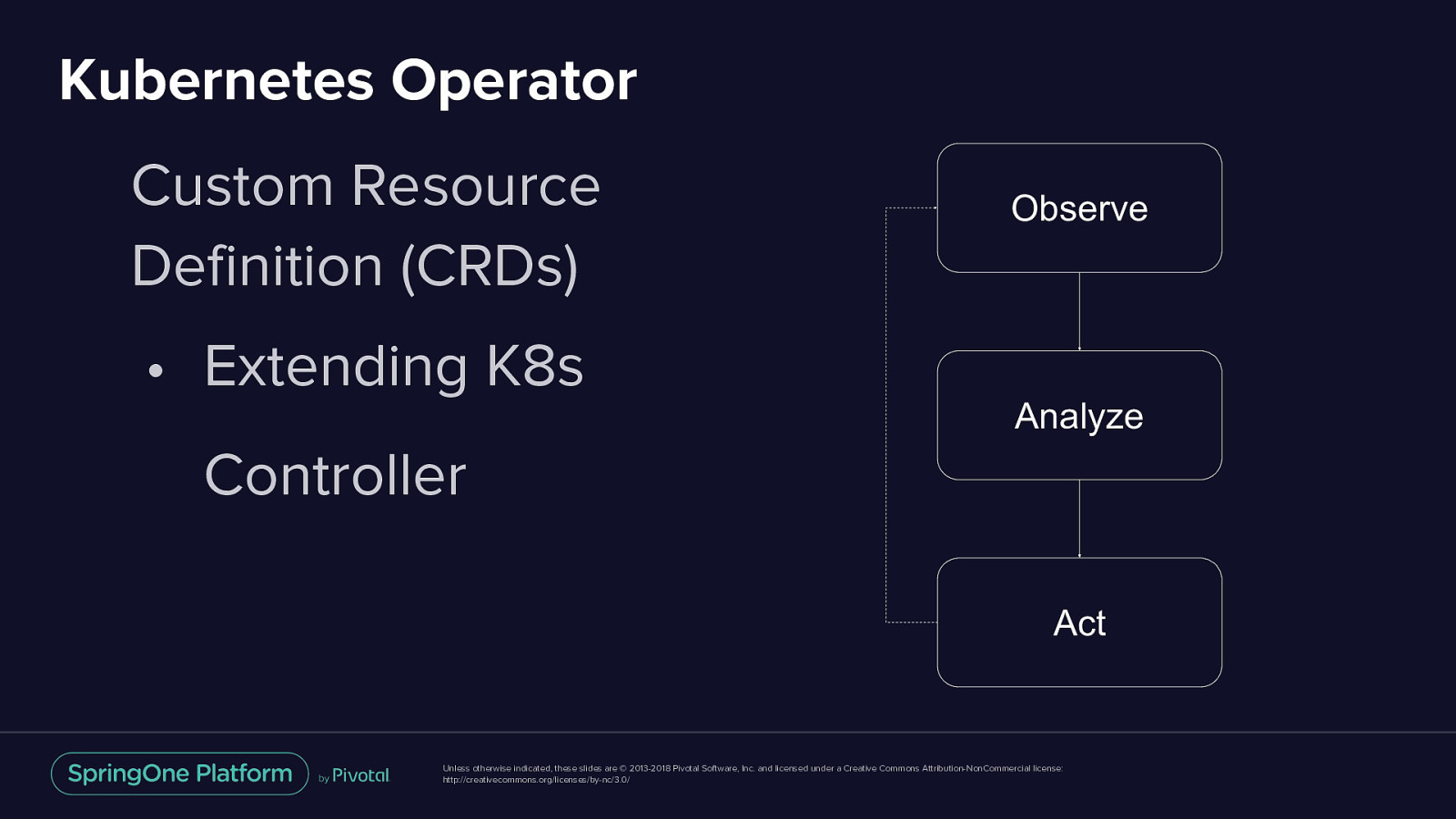
Kubernetes Operator Custom Resource Definition (CRDs) • Extending K8s Observe Analyze Controller Act Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
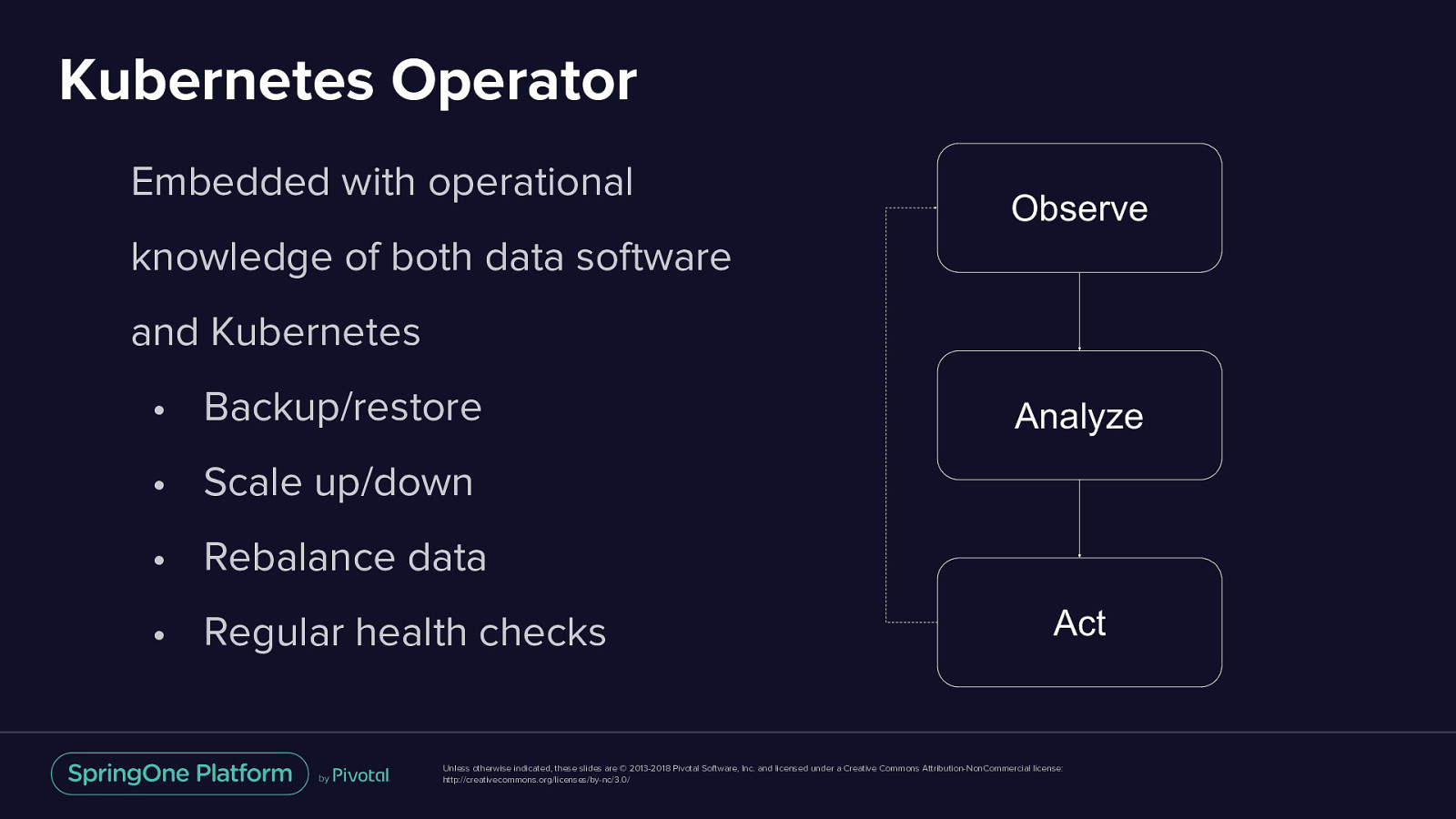
Kubernetes Operator Embedded with operational Observe knowledge of both data software and Kubernetes • Backup/restore Analyze • Scale up/down • Rebalance data • Regular health checks Act Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
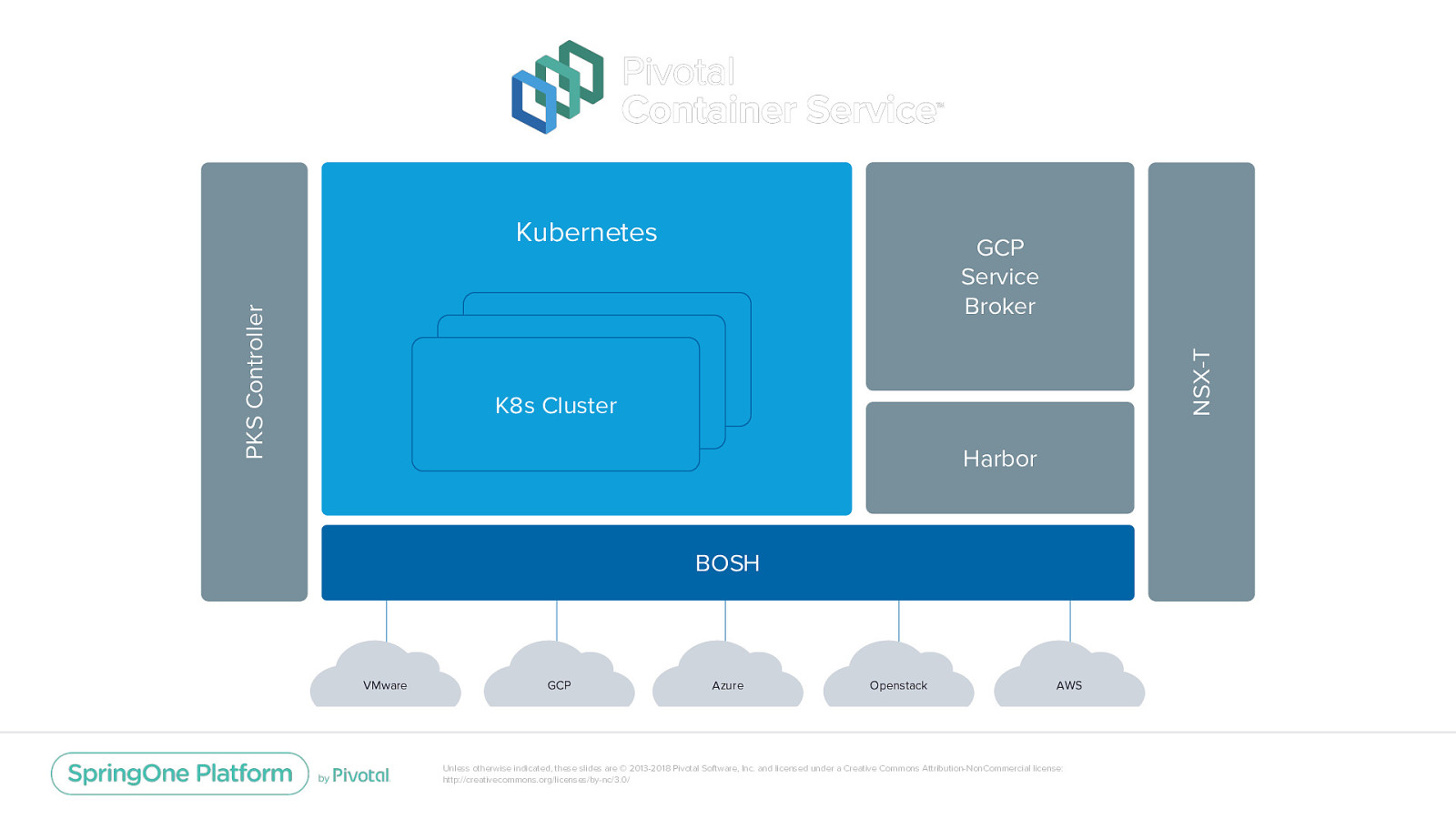
GCP Service Broker NSX-T PKS Controller Kubernetes K8s Cluster K8s Cluster K8s Cluster Harbor BOSH VMware GCP Azure Openstack AWS Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

That’s Kubernetes, what’s PKS? Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
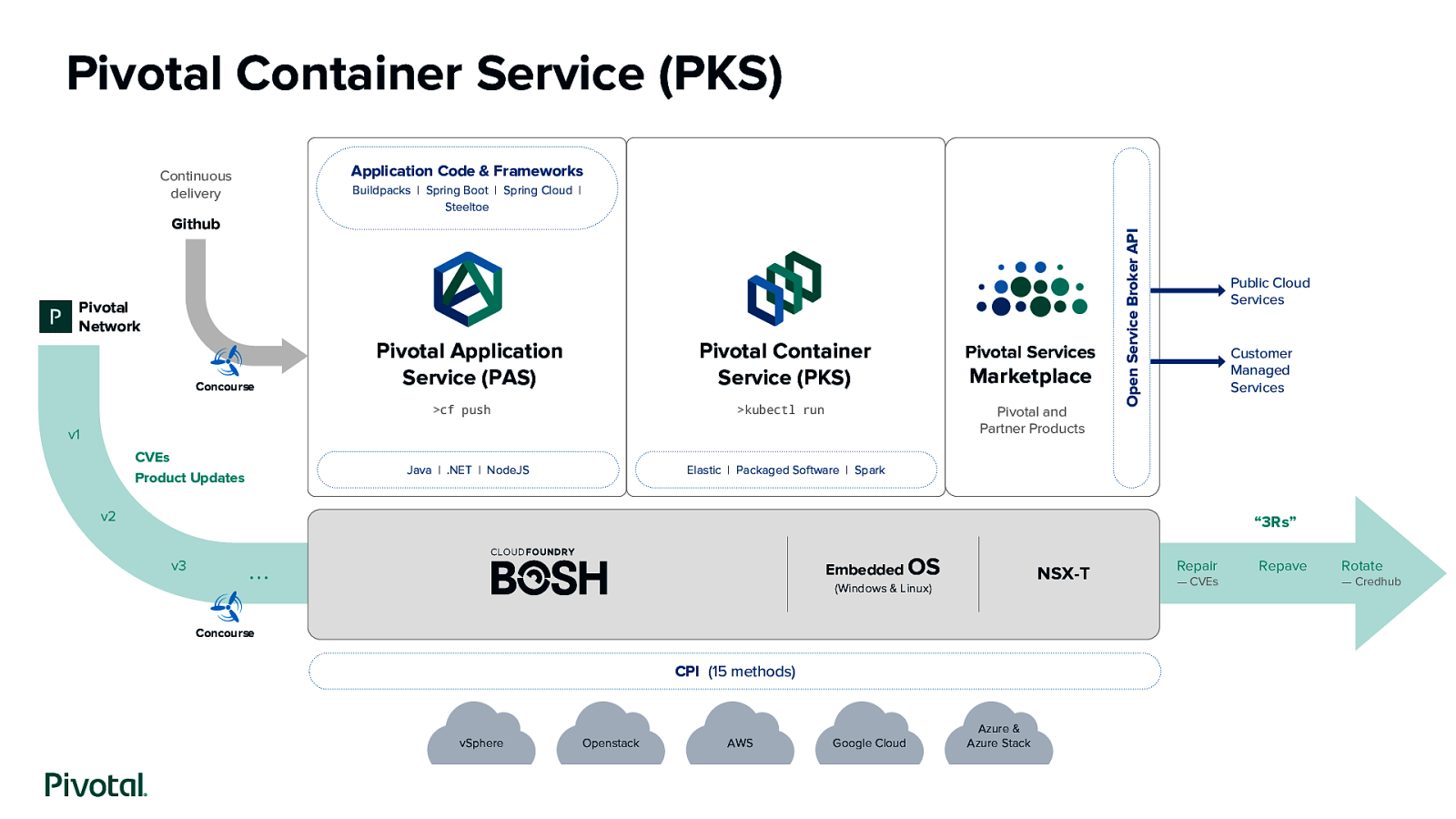
Pivotal Container Service (PKS) Application Code & Frameworks Continuous delivery Github Pivotal Network Concourse Pivotal Application Service (PAS) Pivotal Container Service (PKS)
cf push kubectl run Java | .NET | NodeJS Marketplace Pivotal and Partner Products v1 CVEs Product Updates Pivotal Services Open Service Broker API Buildpacks | Spring Boot | Spring Cloud | Steeltoe Public Cloud Services Customer Managed Services Elastic | Packaged Software | Spark v2 “3Rs” v3 Embedded OS ... NSX-T (Windows & Linux) Concourse CPI (15 methods) vSphere Openstack AWS Google Cloud Azure & Azure Stack Repair — CVEs Repave Rotate — Credhub
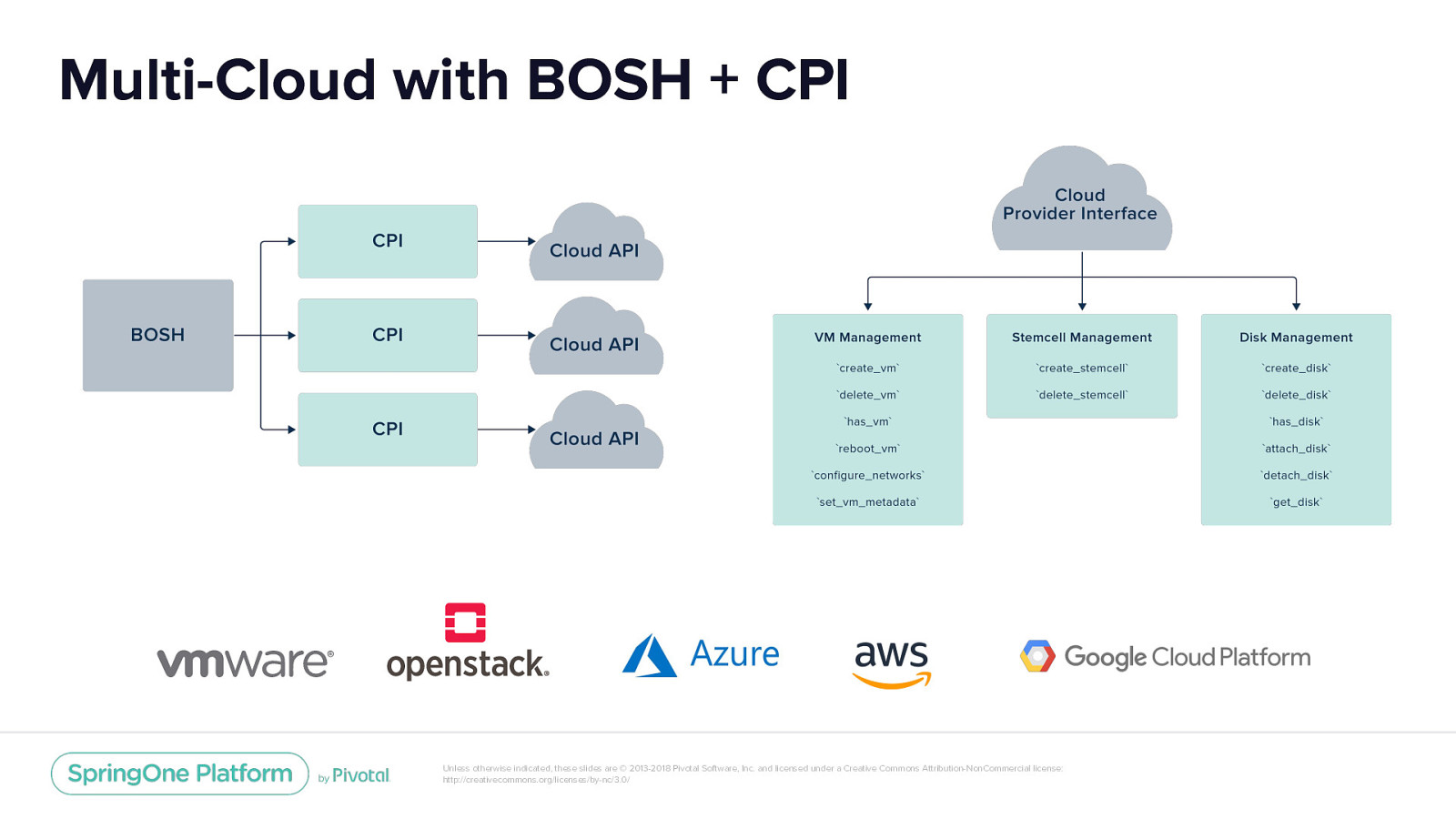
Multi-Cloud with BOSH + CPI Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Agenda • • • • • Why do you need a streaming platform Kafka on Kubernetes Pivotal ❤ Kafka Confluent Platform on PKS Demo Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 6 5 

Kafka Kubernetes journey: Step 1 https://cnfl.io/cp-helm Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Let’s see some yml! Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Agenda • • • • • Why do you need a streaming platform Kafka on Kubernetes Pivotal ❤ Kafka Confluent Platform on PKS Demo Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 6 8 

Step 2: Confluent Operator Deploy and Manage your production streaming platform with Confluent Operator. • Automated Provisioning • Platform Operations • Resiliency • Monitoring Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 6 9 
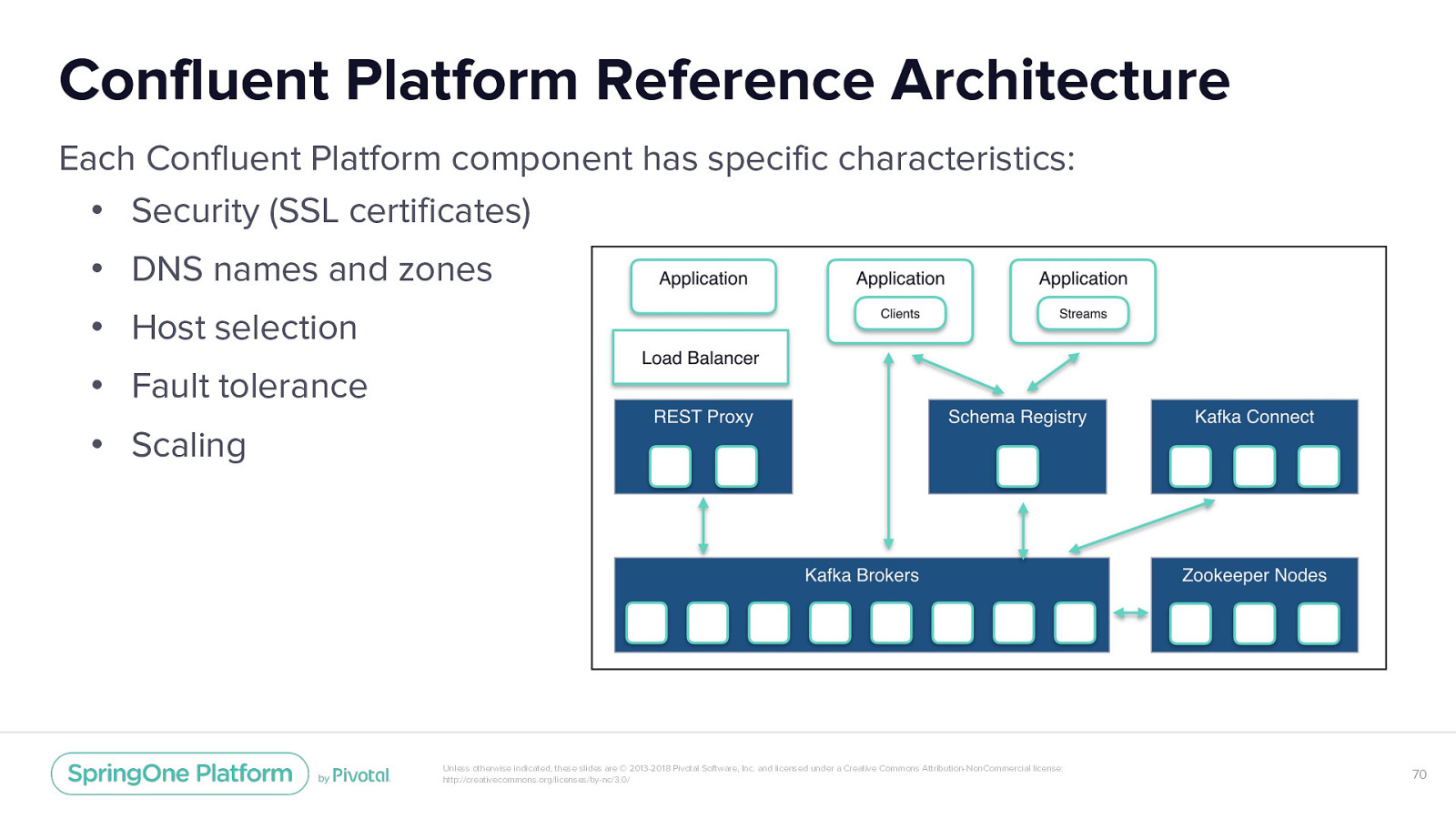
Confluent Platform Reference Architecture Each Confluent Platform component has specific characteristics: • Security (SSL certificates) • DNS names and zones • Host selection • Fault tolerance • Scaling Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 70
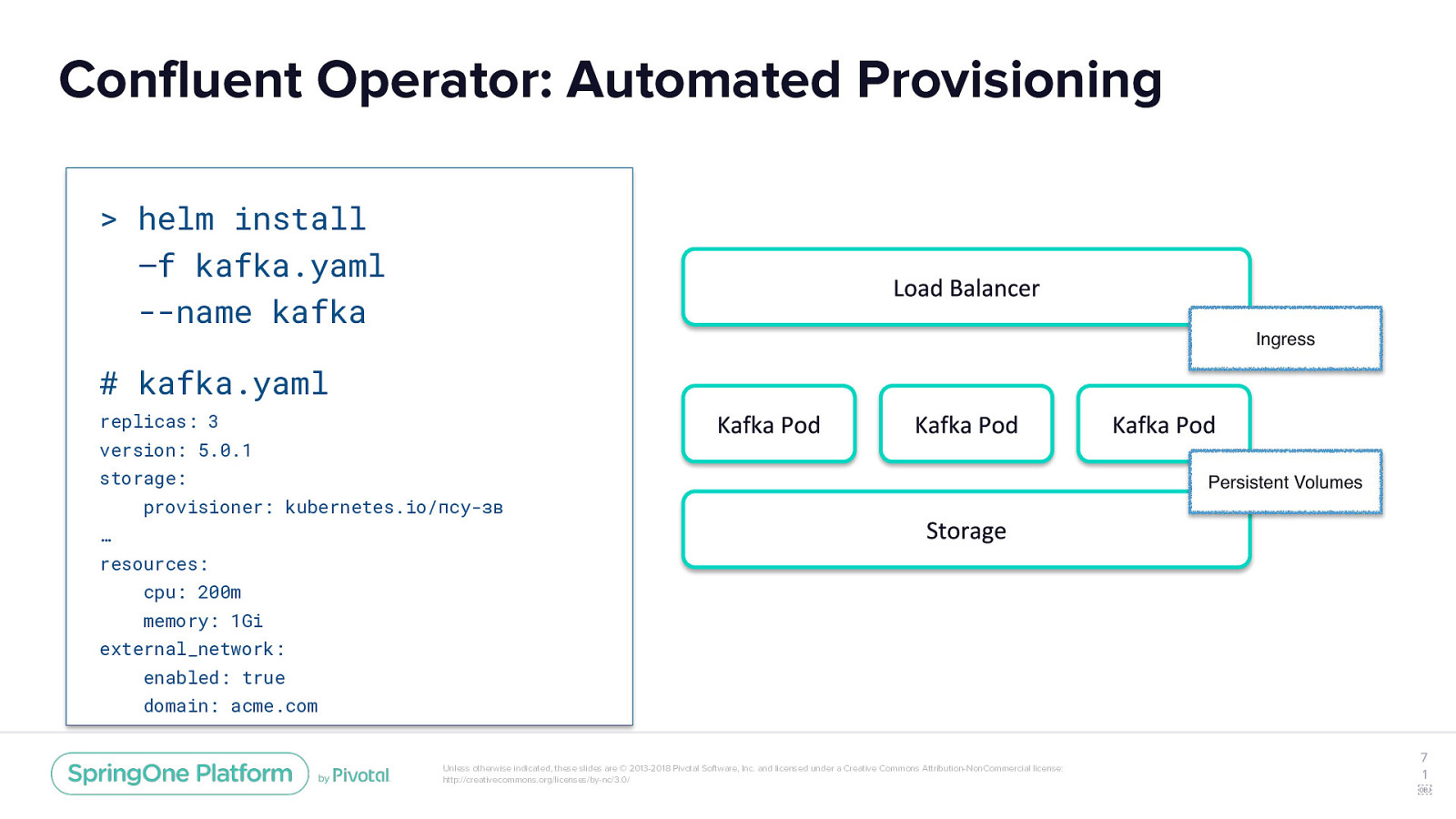
Confluent Operator: Automated Provisioning > helm install –f kafka.yaml --name kafka # kafka.yaml replicas: 3 version: 5.0.1 storage: provisioner: kubernetes.io/псу-зв … resources: cpu: 200m memory: 1Gi external_network: enabled: true domain: acme.com Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 7 1 
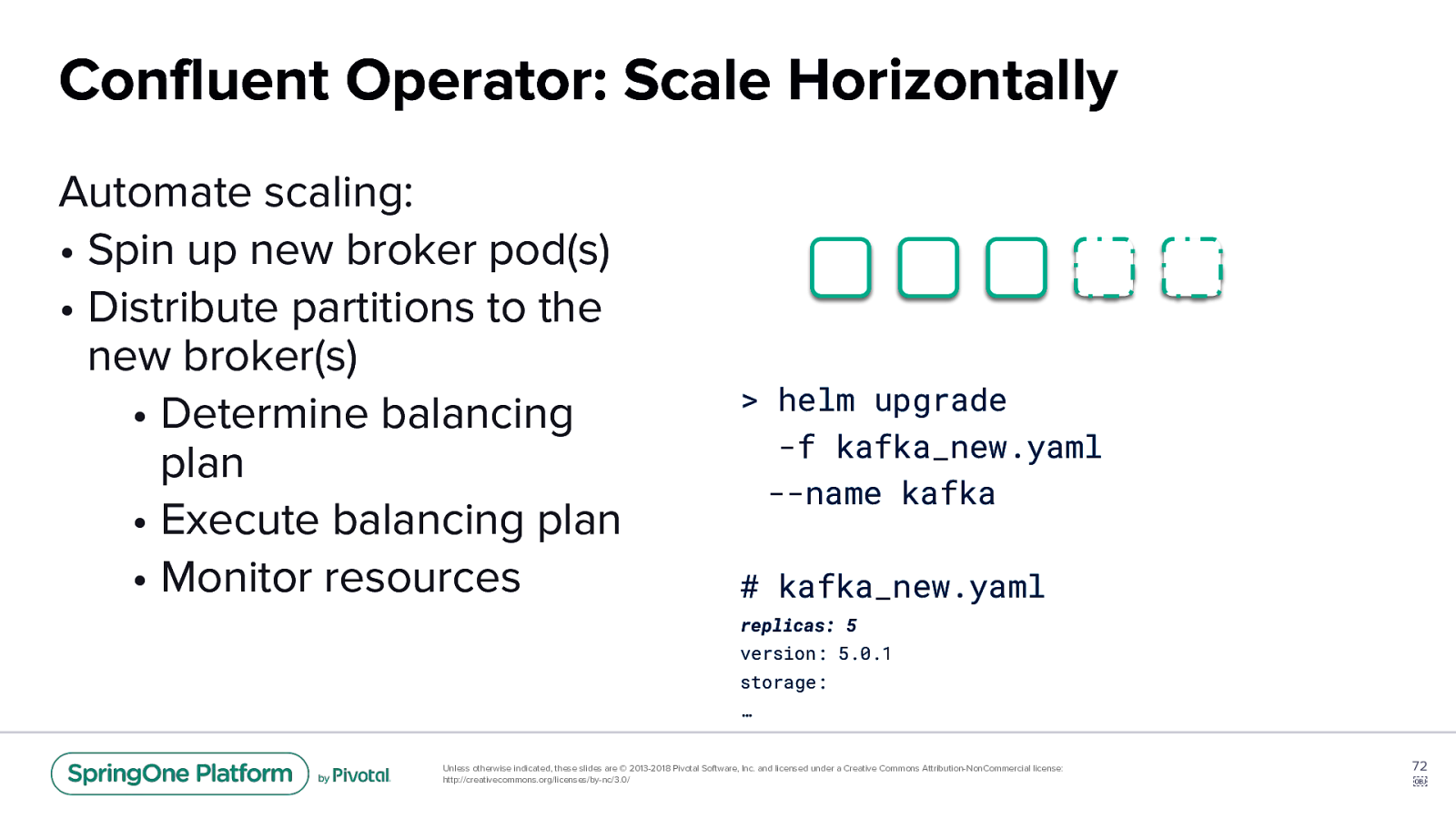
Confluent Operator: Scale Horizontally Automate scaling: • Spin up new broker pod(s) • Distribute partitions to the new broker(s) • Determine balancing plan • Execute balancing plan • Monitor resources
helm upgrade -f kafka_new.yaml --name kafka # kafka_new.yaml replicas: 5 version: 5.0.1 storage: … Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 72 

Confluent Operator: Rolling Upgrade Automated rolling upgrade with no downtime for Kafka. • Stop broker • Wait for leader election to complete • Start broker with new version • Wait for zero under-replicated-partitions • Repeat
helm upgrade -f kafka_new.yaml --name kafka # kafka_new.yaml replicas: 5 version: 5.1.0 Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ 73 

Will it fly? Let’s see Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/

Automate Deployment and Management of Apache Kafka on Pivotal Container Service (PKS) Confluent Operator enables you to: confluent.io/kubernetes Unless otherwise indicated, these slides are © 2013-2018 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ ®

Stay Connected. https://cnfl.io/cp-helm https://cnfl.io/k8s https://pivotal.io/pks @gamussa @prasad_0101 @s1p #springone

When it comes time to choose a distributed streaming platform of choice for real-time data pipelines, everyone knows the answer: Apache Kafka. And when it comes to deploying real-time stream processing applications at scale without having to integrate some different pieces of infrastructure yourself? The answer is Kubernetes. In this talk, Viktor Gamov, Solutions Architect at Confluent and Prasad Radhakrishnan, Head of Platform Architecture for Data at Pivotal discuss the best practices on running Apache Kafka and other components of a streaming platform such as Kafka Connect, Schema Registry as well as stream processing apps on PKS (Pivotal Container Service). In this talk, the presenters will cover the challenges and lessons learned from development of Confluent Operator for Kubernetes as well as various custom deployments on PKS.
Resources
The following resources were mentioned during the presentation or are useful additional information.
Buzz and feedback
Here’s what was said about this presentation on social media.