Uncorking Real-Time Analytics with Pulsar, Pinot and Flink
A presentation at Data Streaming Summit in in San Francisco, CA, USA by Viktor Gamov

Uncorking Analytics with Apache Pulsar, Apache Flink, and Apache Pinot f Viktor Gamov, Con luent | @gamussa San Francisco, CA, October 2024

Before We Proceed… https://gamov.dev/uncorking-analytics @gamussa | @confluentinc | #DataStreamingSummit

A Taxonomy of Analytics @gamussa | @confluentinc | #DataStreamingSummit
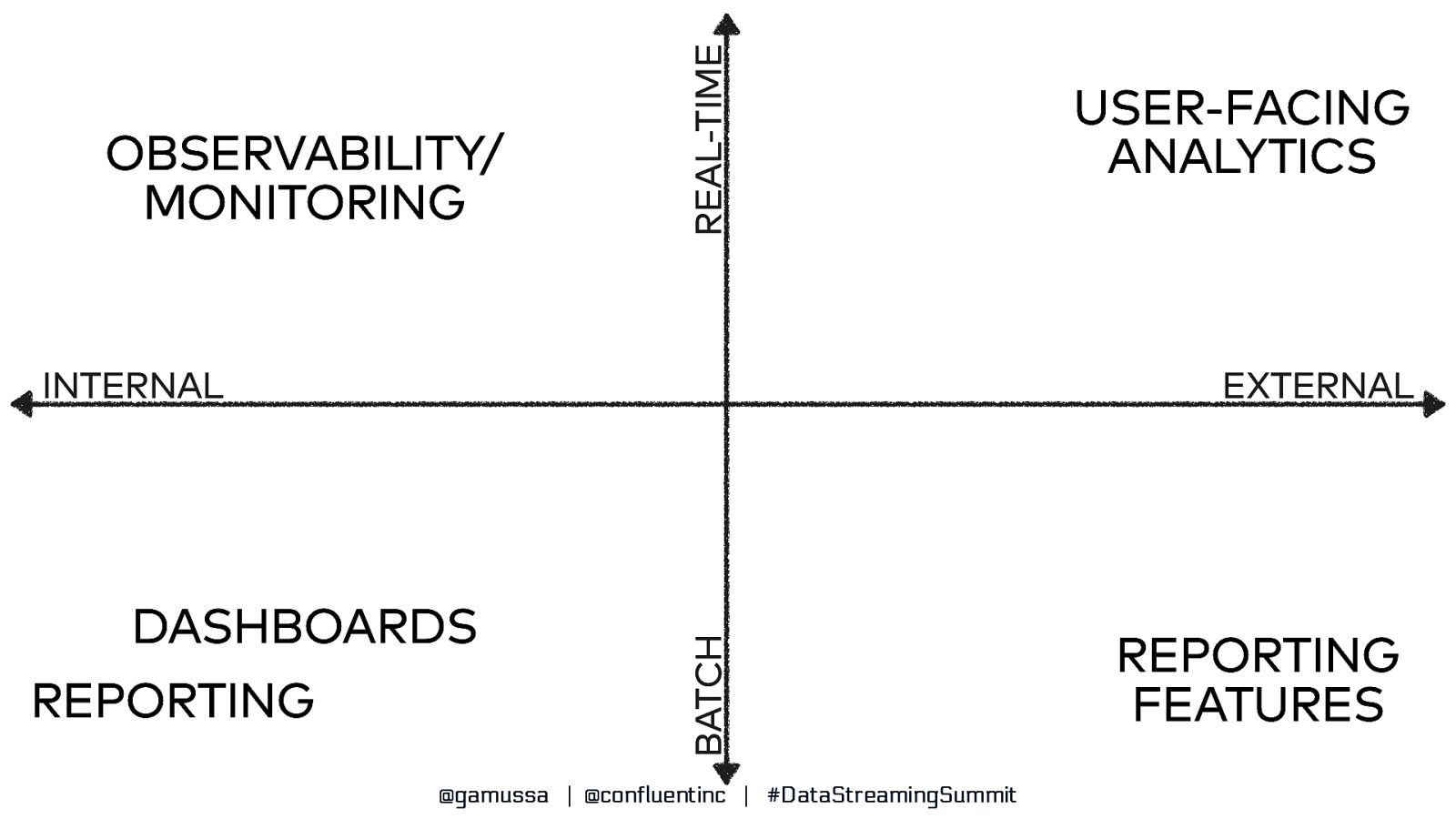
REAL-TIME OBSERVABILITY/ MONITORING EXTERNAL DASHBOARDS REPORTING BATCH INTERNAL USER-FACING ANALYTICS @gamussa | @confluentinc | #DataStreamingSummit REPORTING FEATURES
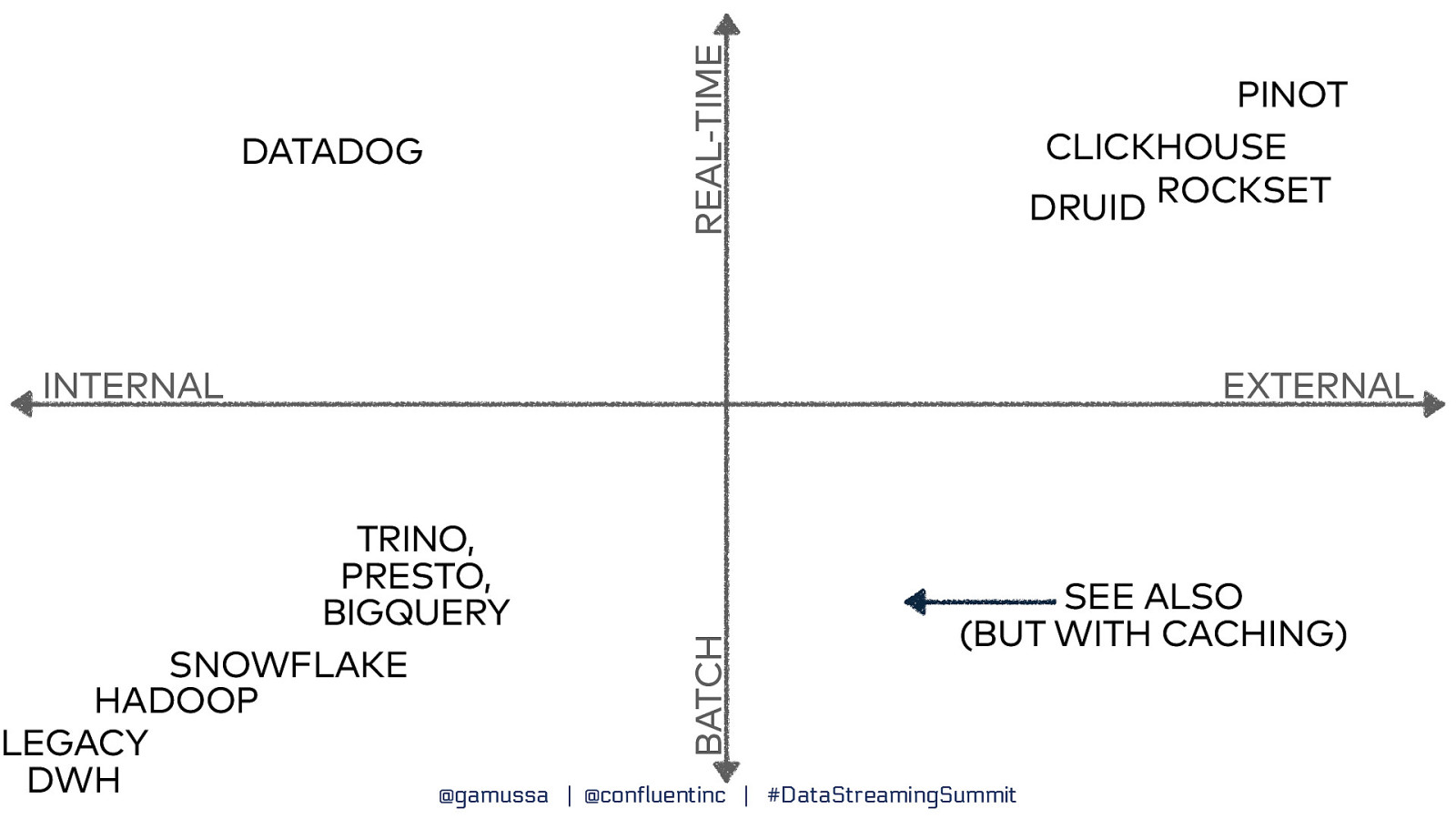
REAL-TIME DATADOG PINOT CLICKHOUSE ROCKSET DRUID TRINO, PRESTO, BIGQUERY SNOWFLAKE HADOOP LEGACY DWH @gamussa EXTERNAL BATCH INTERNAL SEE ALSO (BUT WITH CACHING) | @confluentinc | #DataStreamingSummit

Who Does Real-Time Analytics? @gamussa | @confluentinc | #DataStreamingSummit
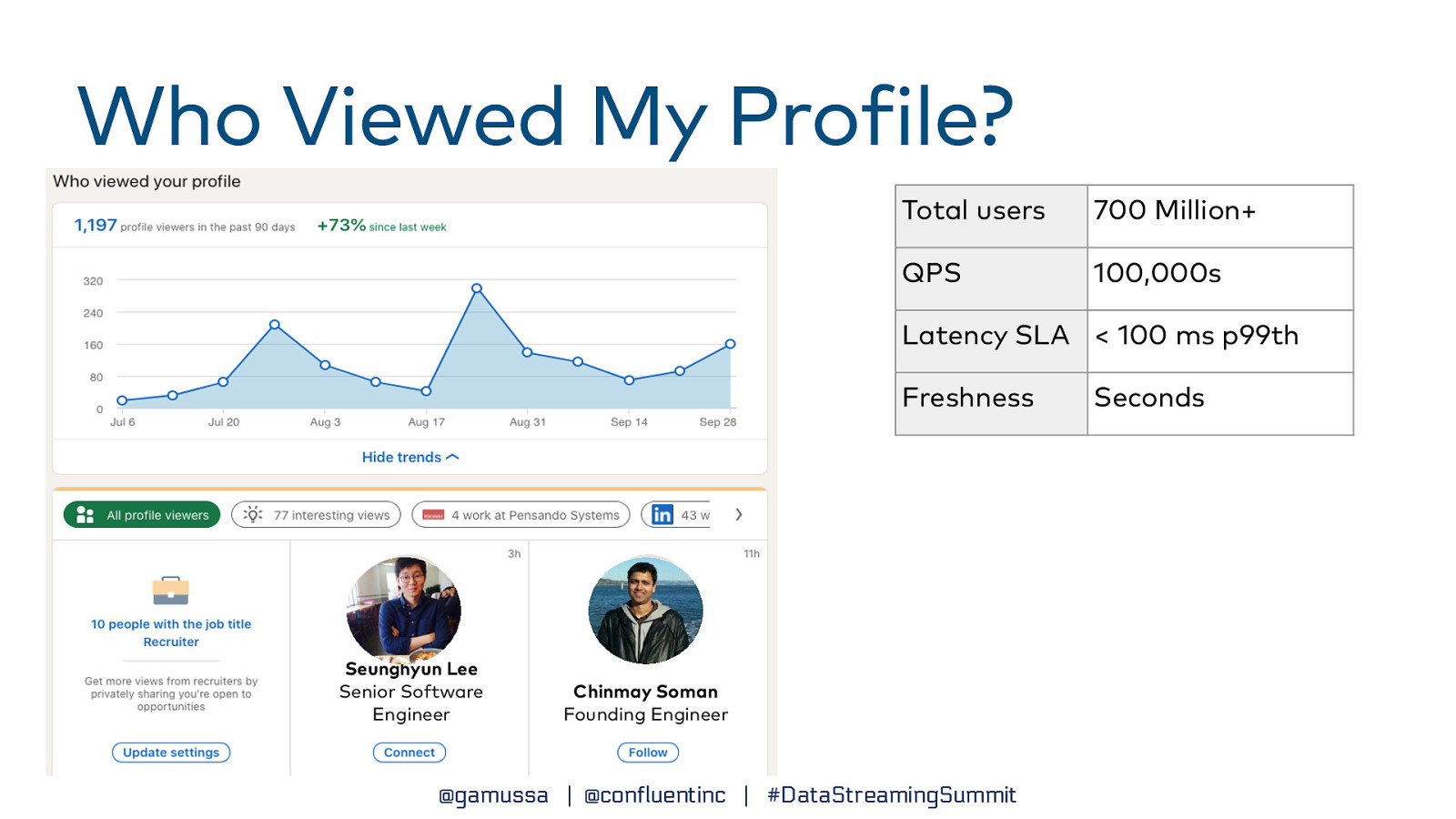
Who Viewed My Pro ile? Total users 700 Million+ QPS 100,000s Latency SLA < 100 ms p99th Freshness Seunghyun Lee Senior Software Engineer Chinmay Soman Founding Engineer f @gamussa | @confluentinc | #DataStreamingSummit Seconds

Viktor GAMOV Principal Developer Advocate | Con luent Java Champion O’Reilly and Manning Author Twitter X: @gamussa f f THE CLOUD CONNECTIVITY COMPANY Kong Con idential

@gamussa | @testcontainers | #DataStreamingSummit

What is Apache Pinot ? ™ @gamussa | @confluentinc | #DataStreamingSummit

“Apache Pinot is a real-time distributed OLAP database, designed to serve OLAP workloads on streaming data with extreme low latency and high concurrency.” @gamussa | @confluentinc | #DataStreamingSummit
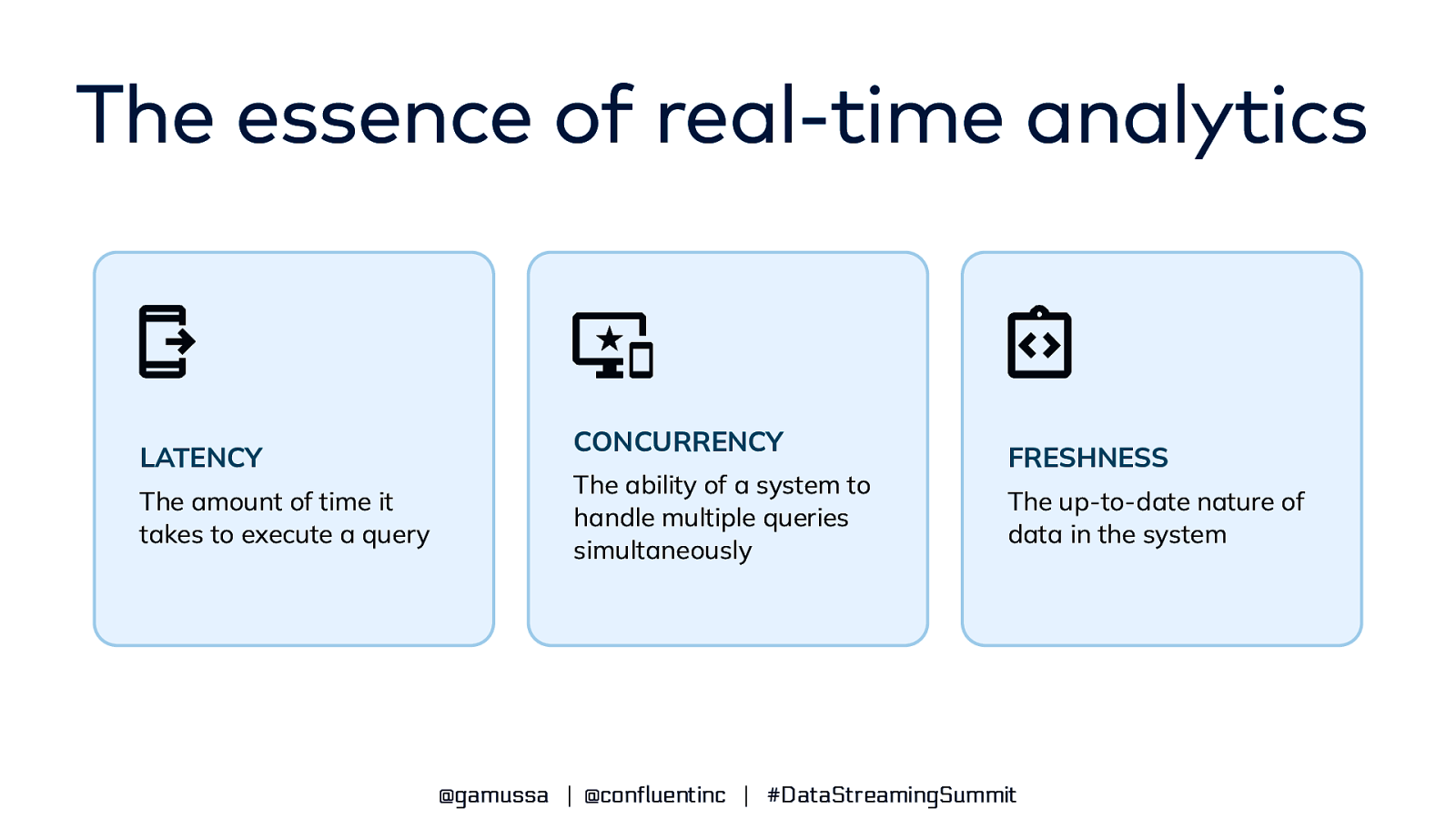
The essence of real-time analytics LATENCY The amount of time it takes to execute a query CONCURRENCY The ability of a system to handle multiple queries simultaneously FRESHNESS The up-to-date nature of data in the system @gamussa | @confluentinc | #DataStreamingSummit
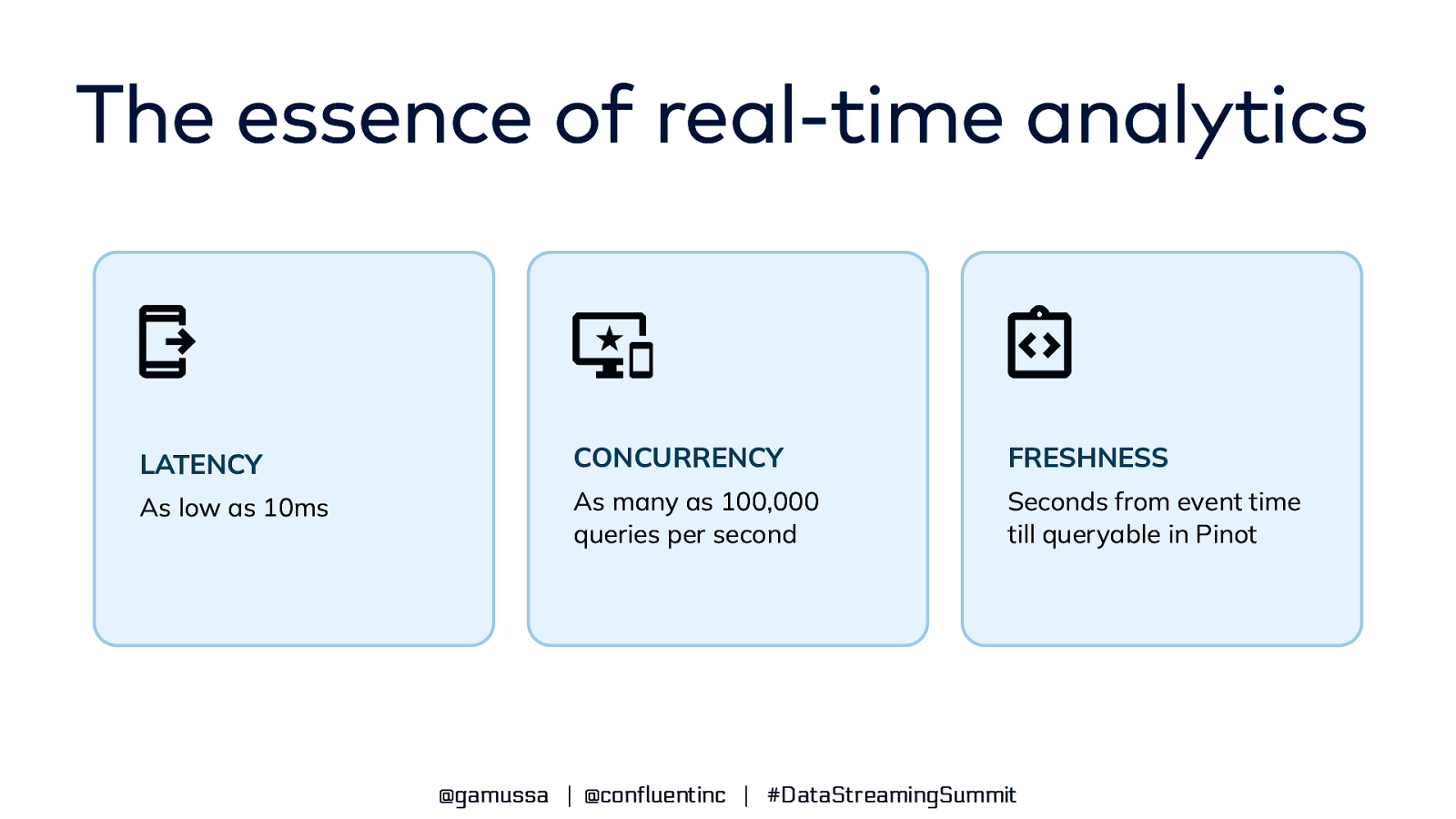
The essence of real-time analytics LATENCY CONCURRENCY FRESHNESS As low as 10ms As many as 100,000 queries per second Seconds from event time till queryable in Pinot @gamussa | @confluentinc | #DataStreamingSummit
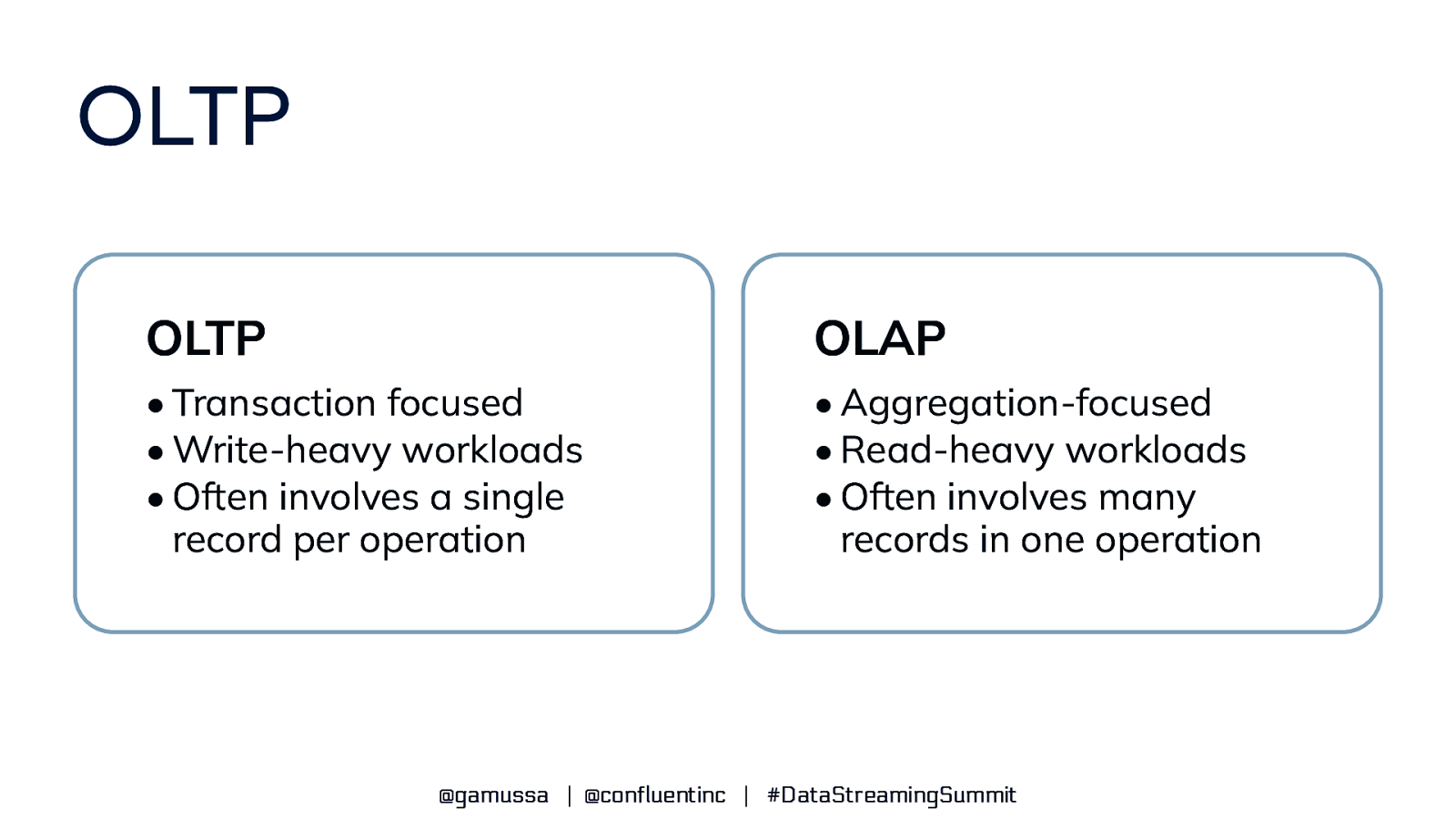
OLTP OLTP OLAP • Transaction focused • Write-heavy workloads • Often involves a single record per operation • Aggregation-focused • Read-heavy workloads • Often involves many records in one operation @gamussa | @confluentinc | #DataStreamingSummit

Data Model ● Pinot uses the completely familiar tabular data model ● Table creation and schema definition expressed in JSON ● Queries expressed in SQL

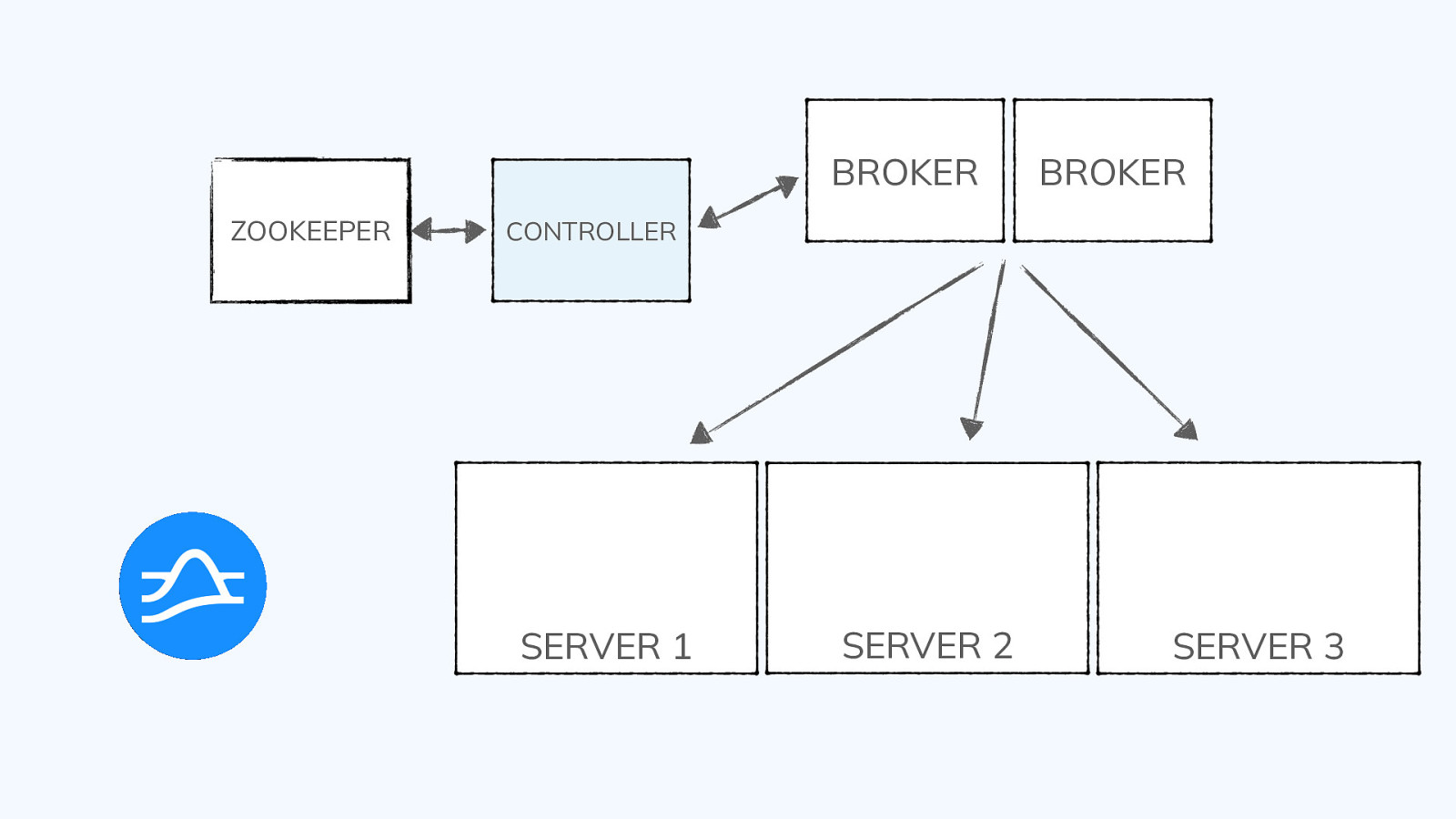
Architecture: Tables and Segments @gamussa | @confluentinc | #DataStreamingSummit

Tables ● ● ● ● ● ● The basic unit of data storage in Pinot Composed of rows and columns Expected to scale to arbitrarily large row counts Defined using a schema and tableConfig JSON file Three varieties: offline, real-time, and hybrid Every column is either a metric, dimension, or date/time @gamussa | @confluentinc | #DataStreamingSummit

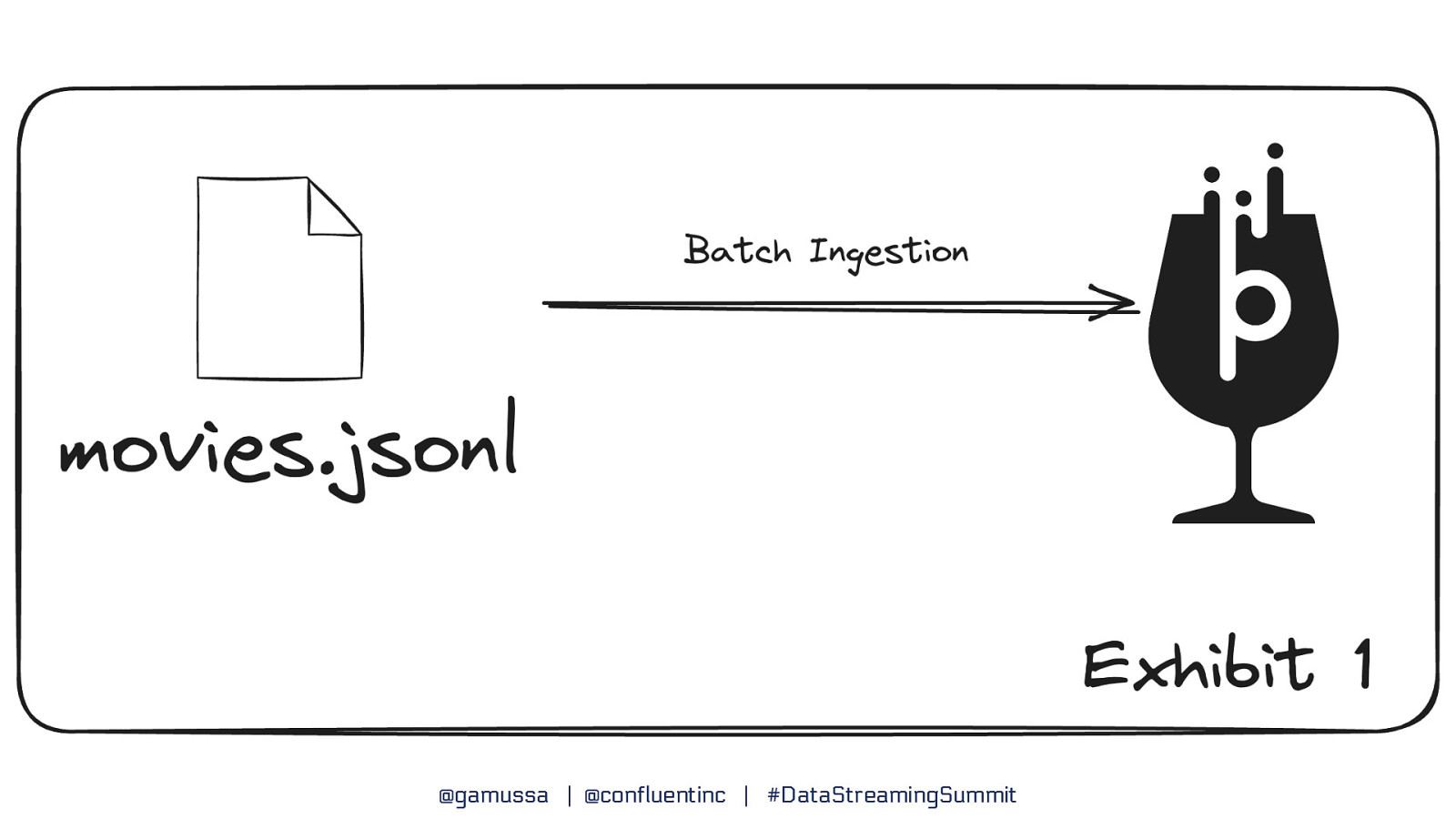
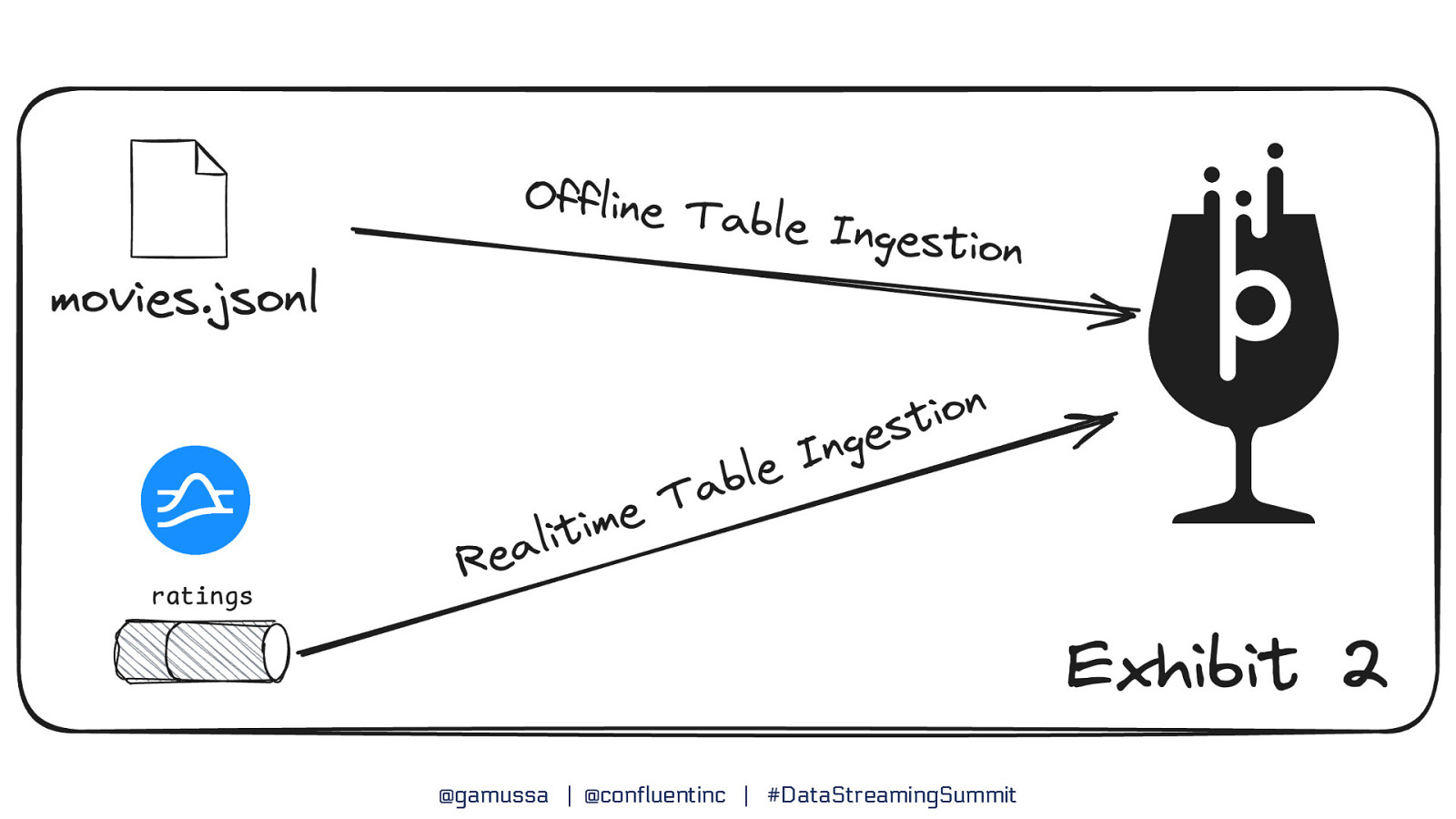
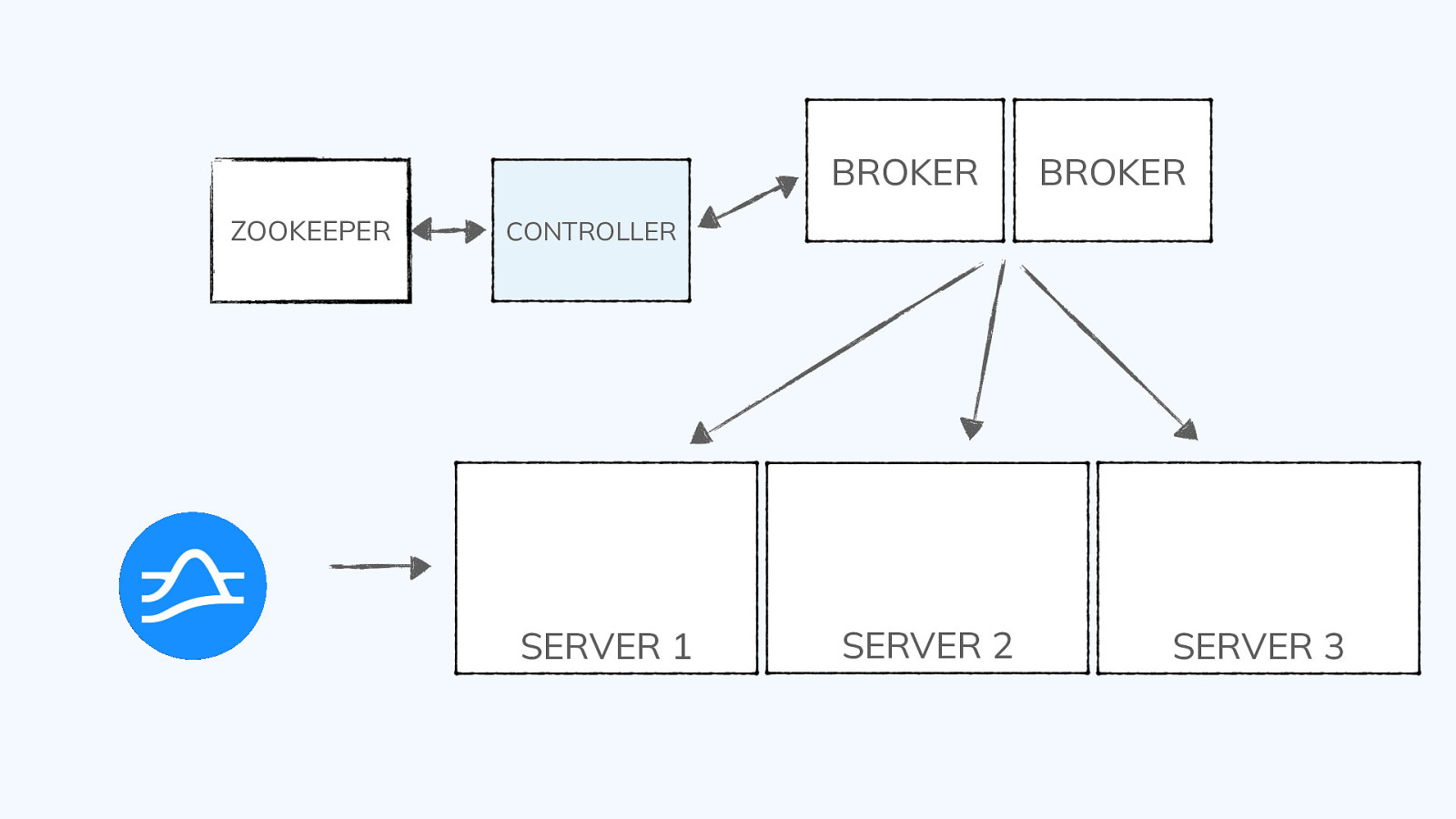
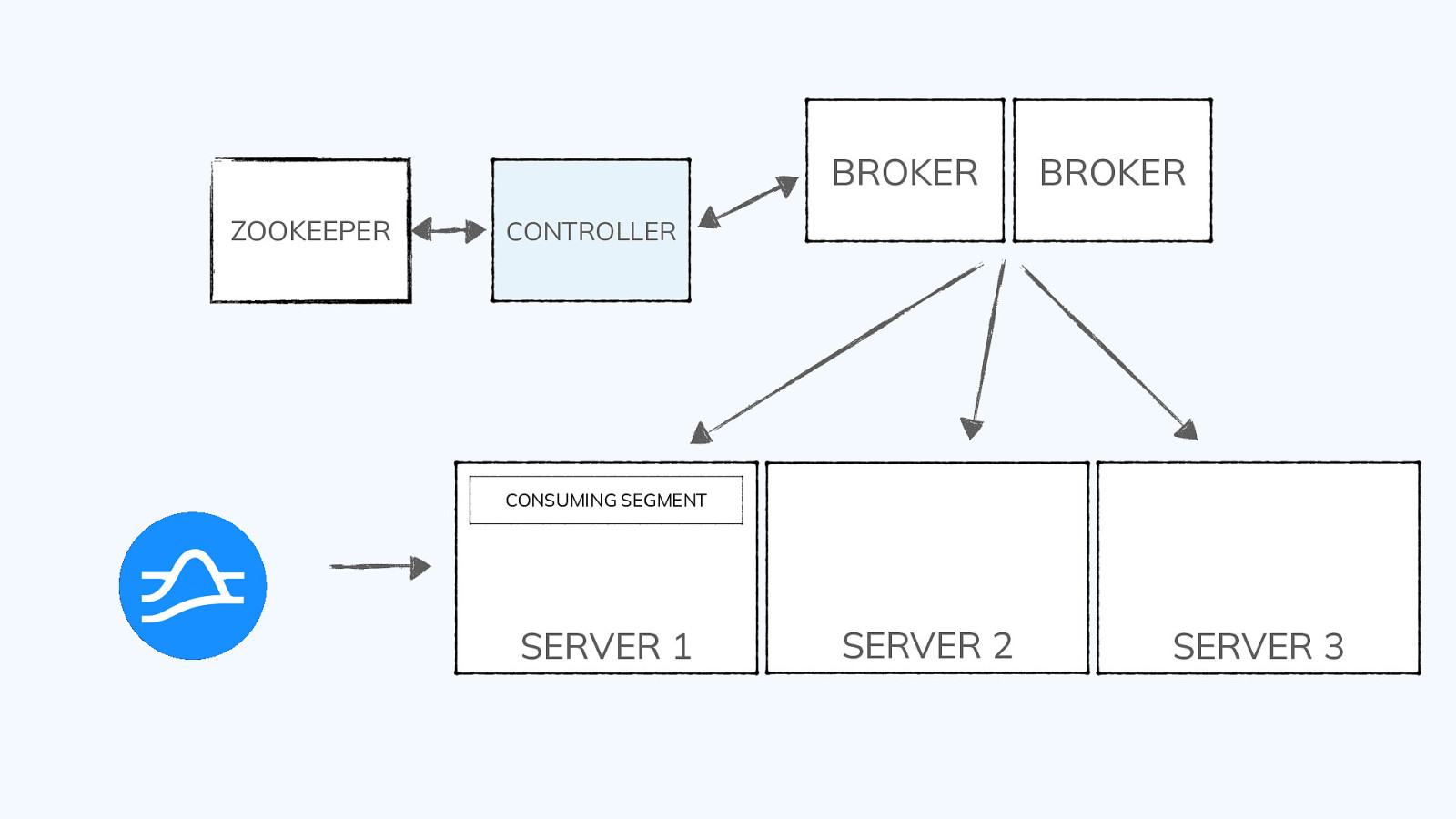
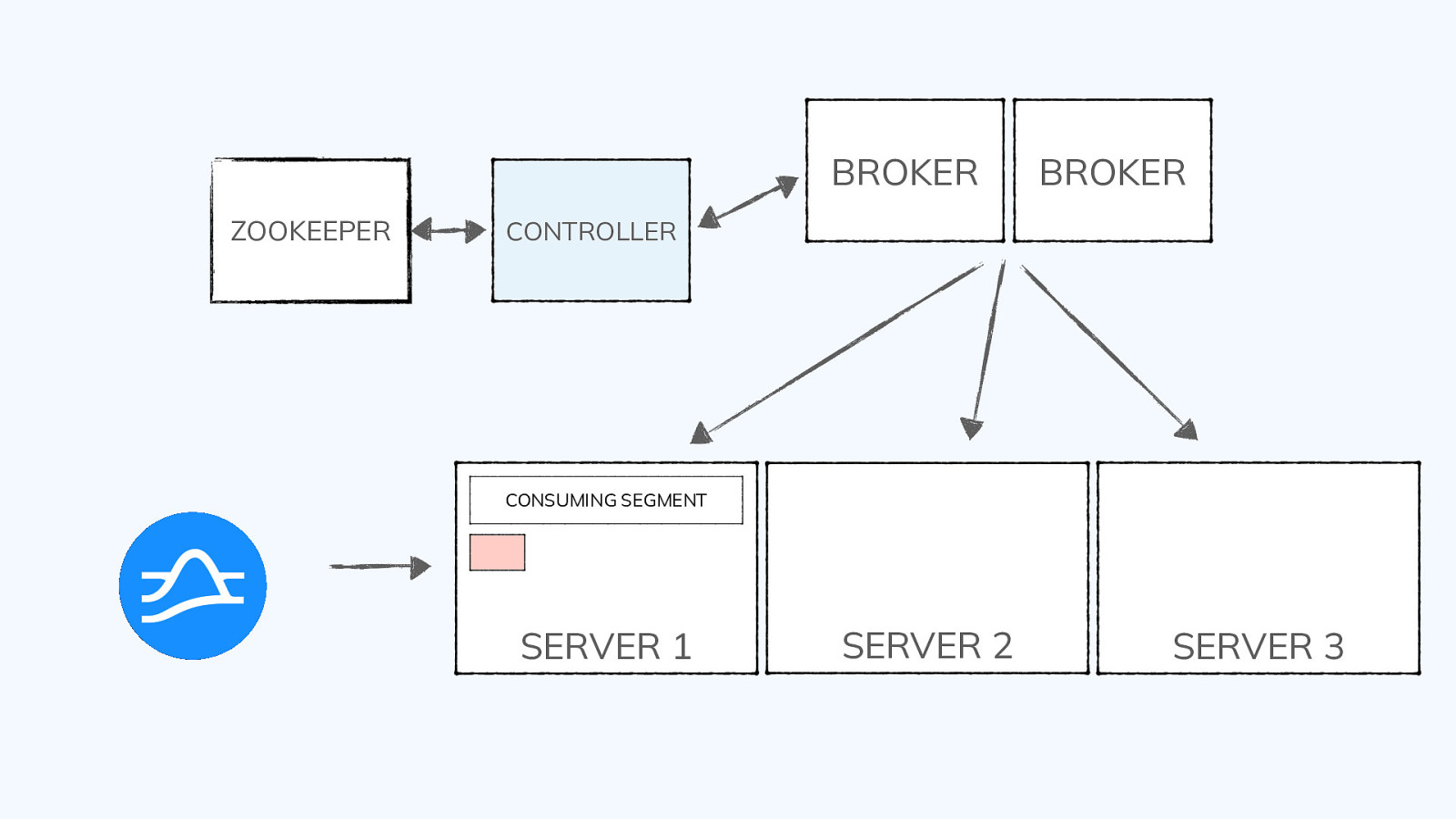
Segments ● Tables are split into units of storage called segments ● Similar to shards or partitions but transparent to you, the user ● For offline tables, segments are created outside of Pinot and pushed into the cluster using a REST API ● For real-time tables, segments are created automatically from events sourced by the event streaming system (e.g., Pulsar, Kafka) ● Standard utilities support batch ingest from standard file types (AVRO, JSON, CSV) ● APIs are available to create segments from Spark, Flink, and Hadoop @gamussa | @confluentinc | #DataStreamingSummit
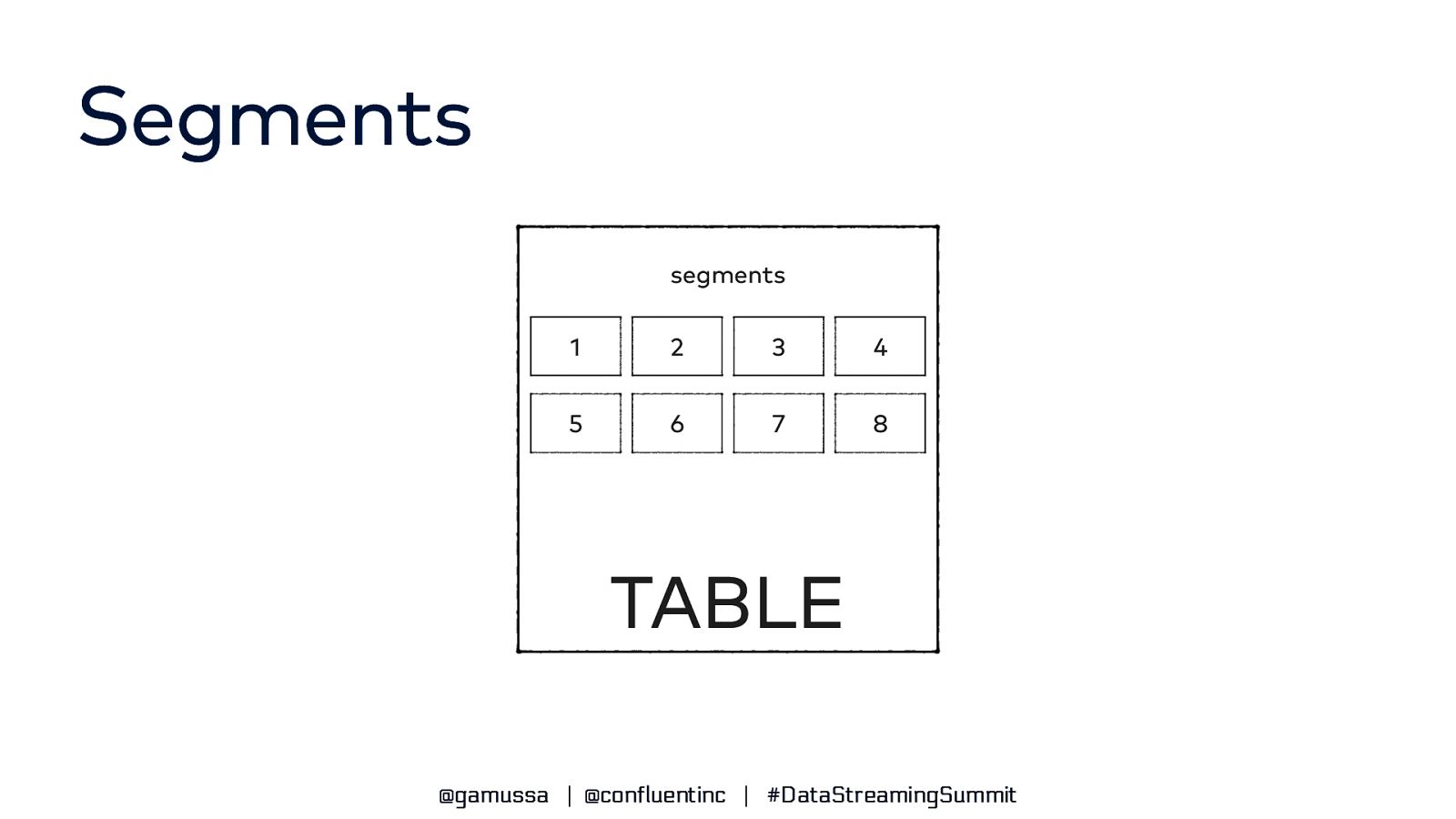
Segments segments 1 2 3 4 5 6 7 8 TABLE @gamussa | @confluentinc | #DataStreamingSummit

Segment Structure ● Pinot is a columnar database ● All of a segment’s values for a single column are stored contiguously ● Dimension columns are typically dictionary-encoded ● Indexes are stored as a part of the segment ● Segments are immutable once written ● Segments have a configurable retention period @gamussa | @confluentinc | #DataStreamingSummit
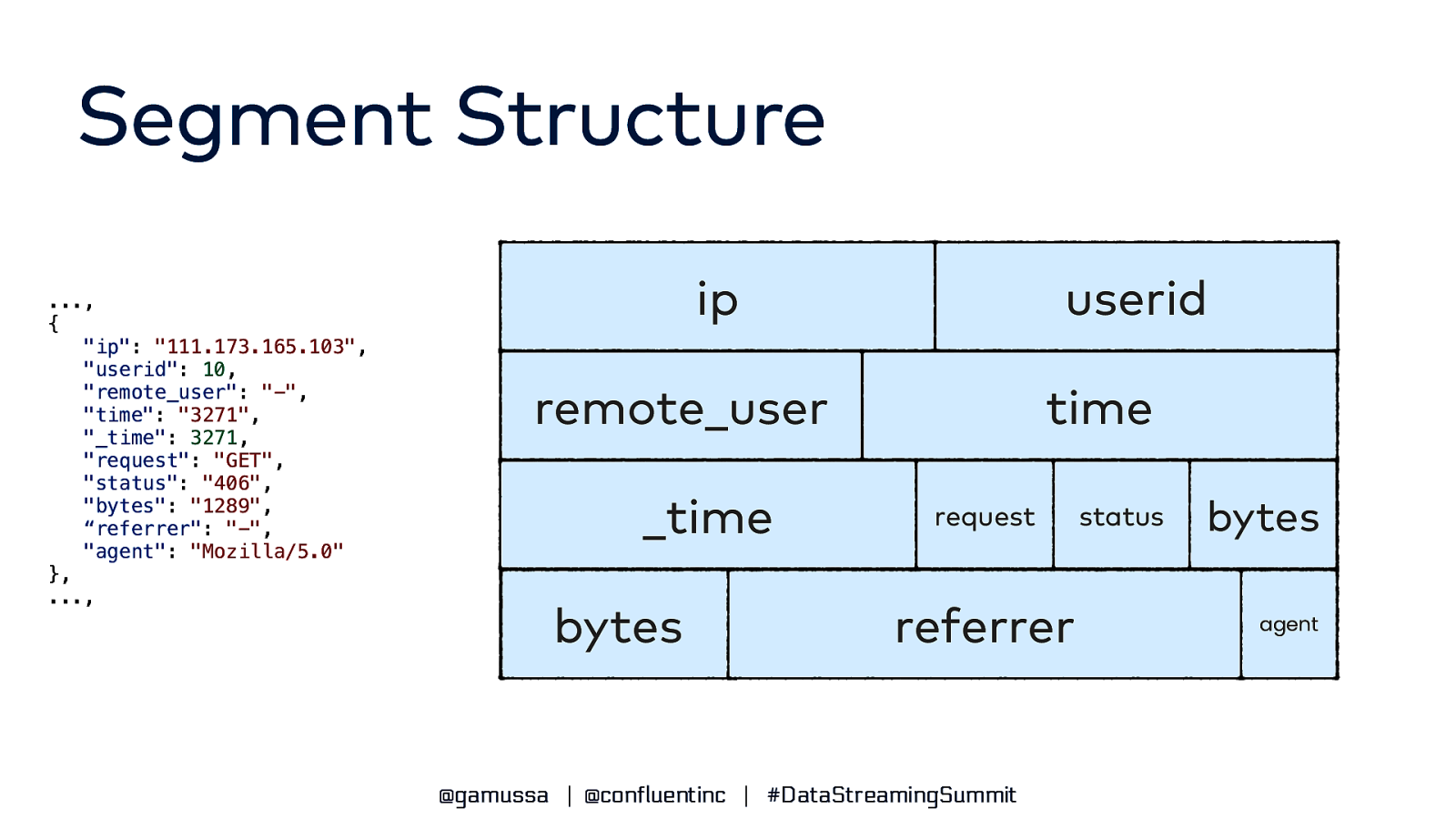
Segment Structure …, { “ip”: “111.173.165.103”, “userid”: 10, “remote_user”: “-“, “time”: “3271”, “_time”: 3271, “request”: “GET”, “status”: “406”, “bytes”: “1289”, “referrer”: “-“, “agent”: “Mozilla/5.0” }, …, ip userid remote_user _time bytes time request referrer @gamussa | @confluentinc | #DataStreamingSummit status bytes agent
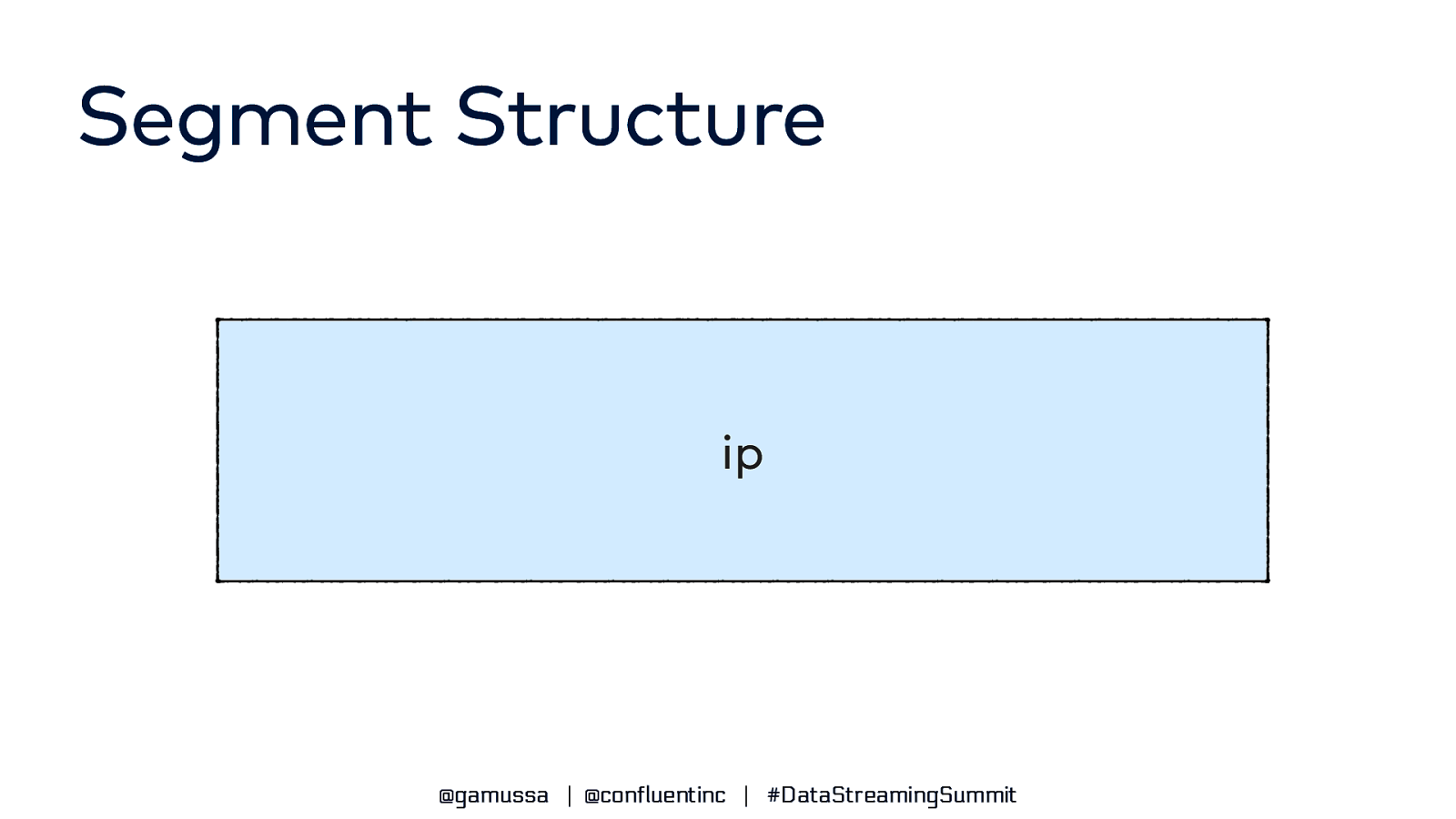
Segment Structure ip @gamussa | @confluentinc | #DataStreamingSummit
Segment Structure @gamussa | @confluentinc | #DataStreamingSummit

@gamussa | @confluentinc | #DataStreamingSummit 132.116.134.205 239.36.131.30 199.191.187.233 13.213.178.183 182.45.66.204 211.235.25.163 165.193.151.176 250.192.178.235 202.43.225.122 166.27.69.94 Segment Structure

Part 1 Batch Ingestion in Pinot @gamussa | @confluentinc | #DataStreamingSummit
@gamussa | @confluentinc | #DataStreamingSummit

Part 2 Streaming Ingestion with Ka ka f @gamussa | @confluentinc | #DataStreamingSummit
@gamussa | @confluentinc | #DataStreamingSummit
BROKER ZOOKEEPER BROKER CONTROLLER SERVER 1 SERVER 2 SERVER 3
BROKER ZOOKEEPER BROKER CONTROLLER SERVER 1 SERVER 2 SERVER 3
BROKER ZOOKEEPER BROKER CONTROLLER CONSUMING SEGMENT SERVER 1 SERVER 2 SERVER 3
BROKER ZOOKEEPER BROKER CONTROLLER CONSUMING SEGMENT SERVER 1 SERVER 2 SERVER 3
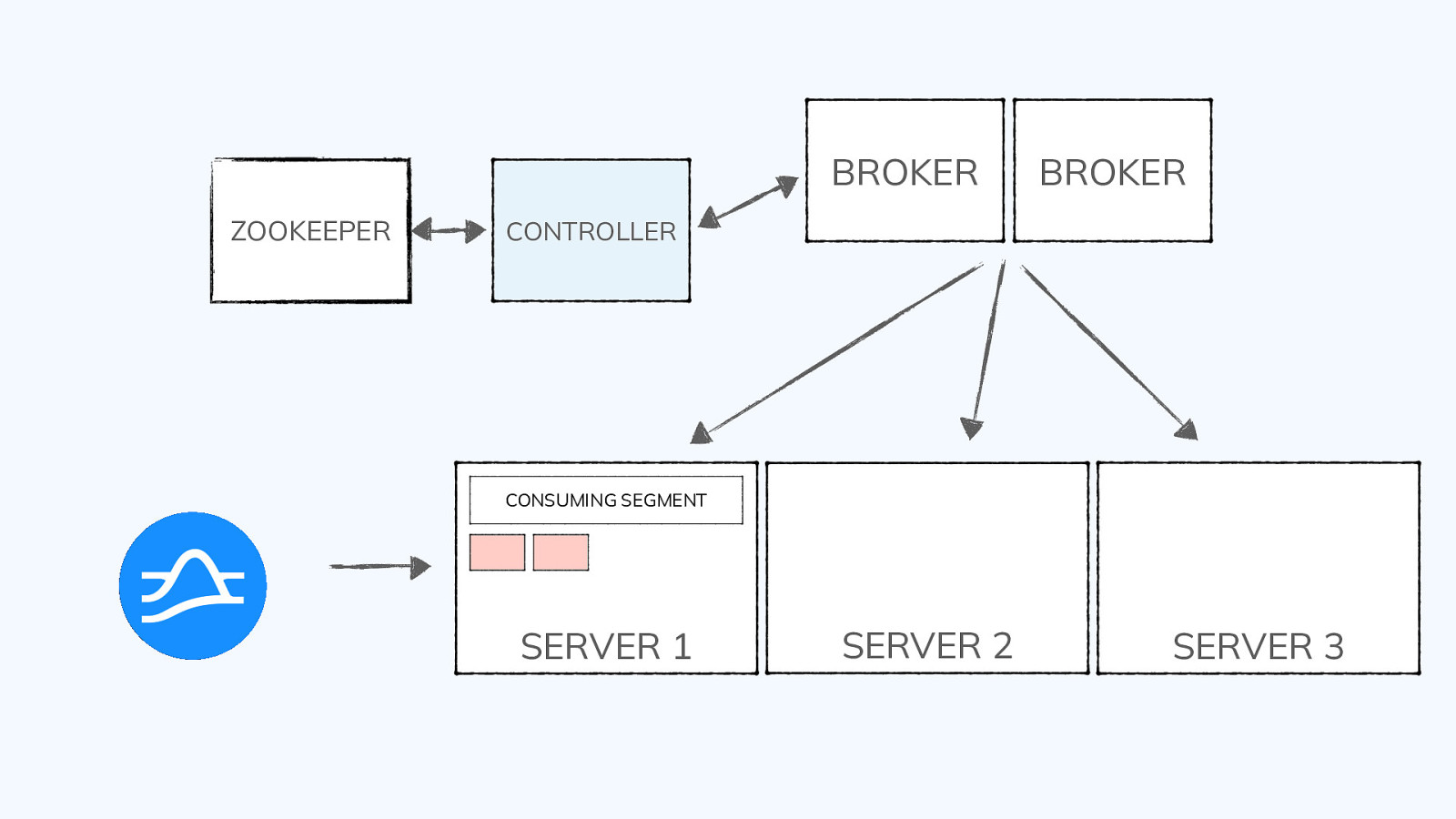
BROKER ZOOKEEPER BROKER CONTROLLER CONSUMING SEGMENT SERVER 1 SERVER 2 SERVER 3
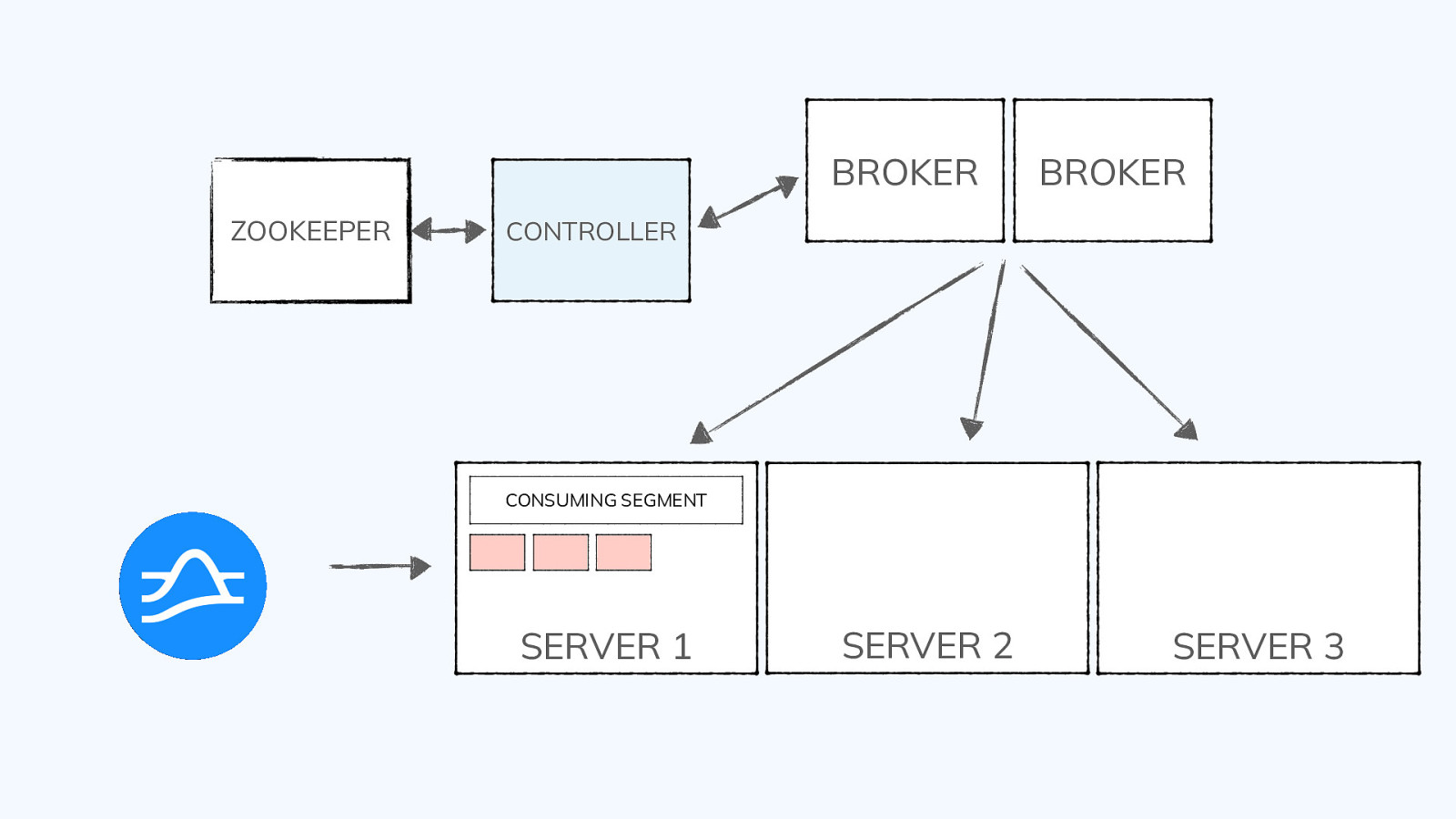
BROKER ZOOKEEPER BROKER CONTROLLER CONSUMING SEGMENT SERVER 1 SERVER 2 SERVER 3

Part 3 Stream Join in Flink @gamussa | @confluentinc | #DataStreamingSummit

Flink 101 @gamussa | @confluentinc | #DataStreamingSummit

«Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.» @gamussa | @confluentinc | #DataStreamingSummit
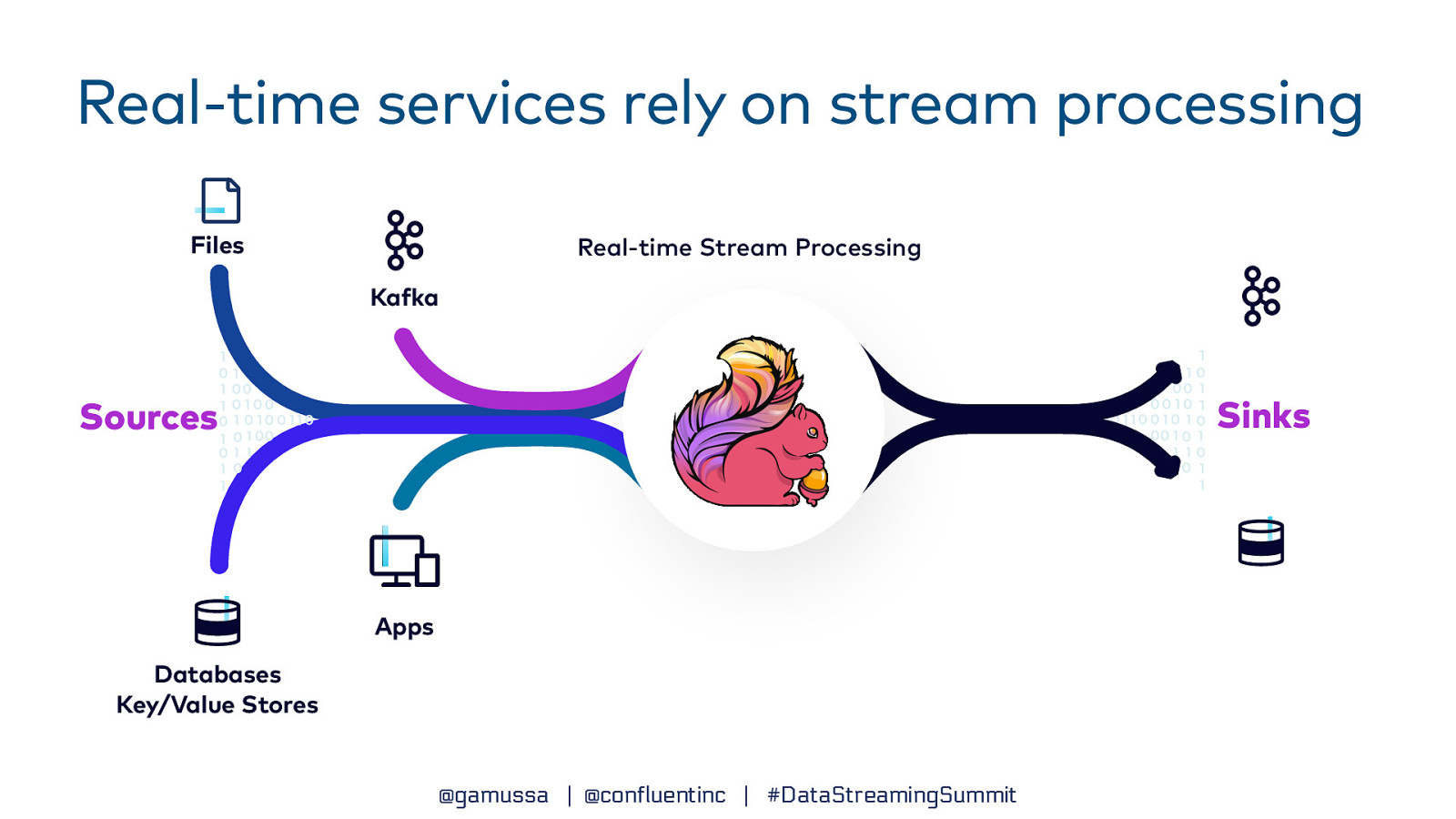
Real-time services rely on stream processing Files Real-time Stream Processing Ka ka Sinks Sources Apps Databases Key/Value Stores f @gamussa | @confluentinc | #DataStreamingSummit

What is Flink SQL @gamussa | @confluentinc | #DataStreamingSummit

A standards-compliant SQL engine for processing both batch and streaming data with the scalability, performance, and consistency of Apache Flink @gamussa | @confluentinc | #DataStreamingSummit

Is Flink SQL a database? No. Bring your own data. CREATE TABLE MovieRatings ( movieId INT, rating DOUBLE, ratingTimeMillis BIGINT, ratingTime AS TO_TIMESTAMP_LTZ(ratingTimeMillis, 3) ) WITH ( ‘connector’ = ‘pulsar’, ‘topics’ = ‘persistent://public/default/ratings’, ‘service-url’ = ‘pulsar://pulsar:6650’, ‘value.format’ = ‘json’, ‘source.subscription-name’ = ‘flink-ratingssubscription’, ‘source.subscription-type’ = ‘Shared’ );

How does Flink work with Pulsar? @gamussa | @confluentinc | #DataStreamingSummit
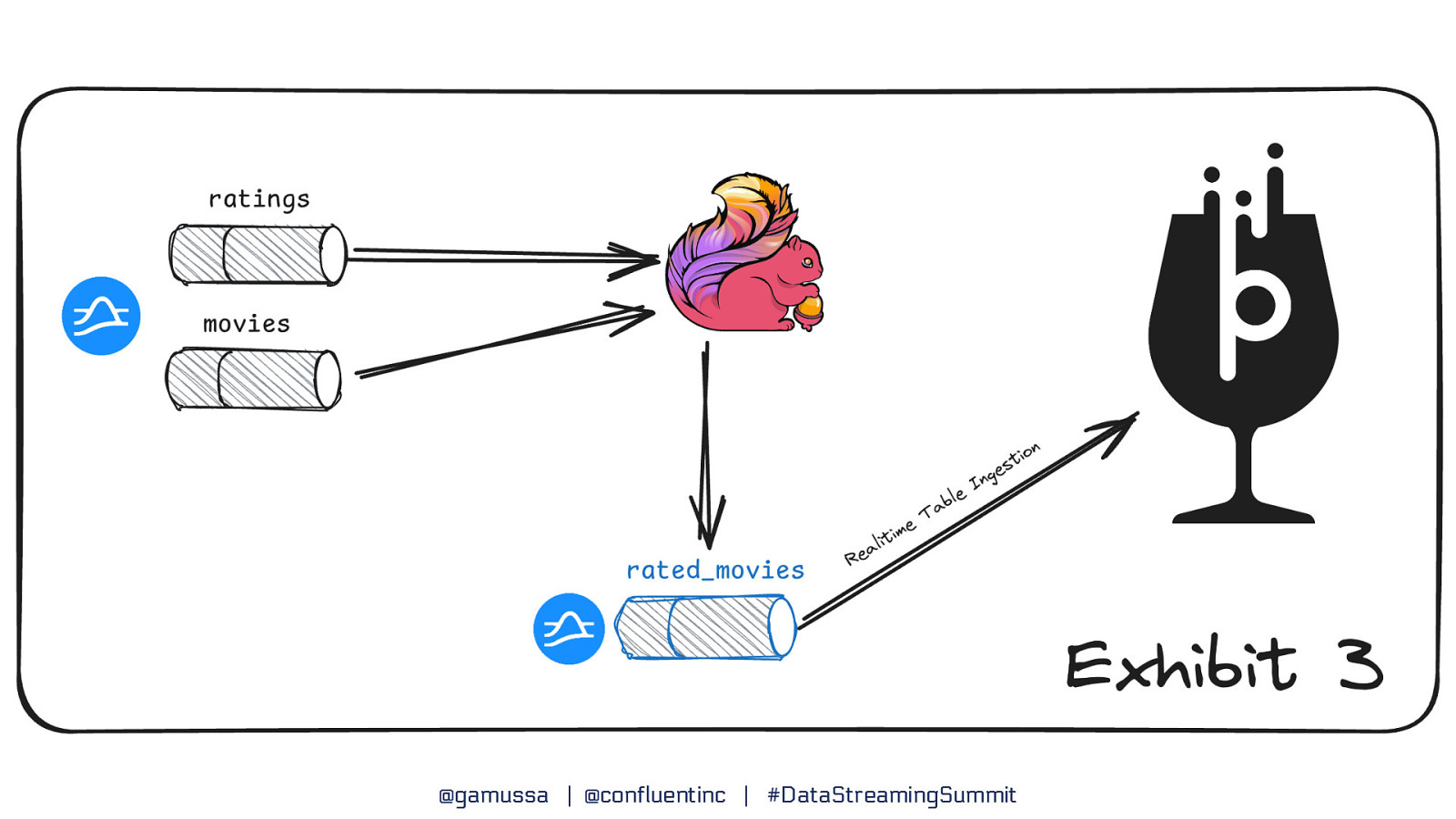
@gamussa | @confluentinc | #DataStreamingSummit
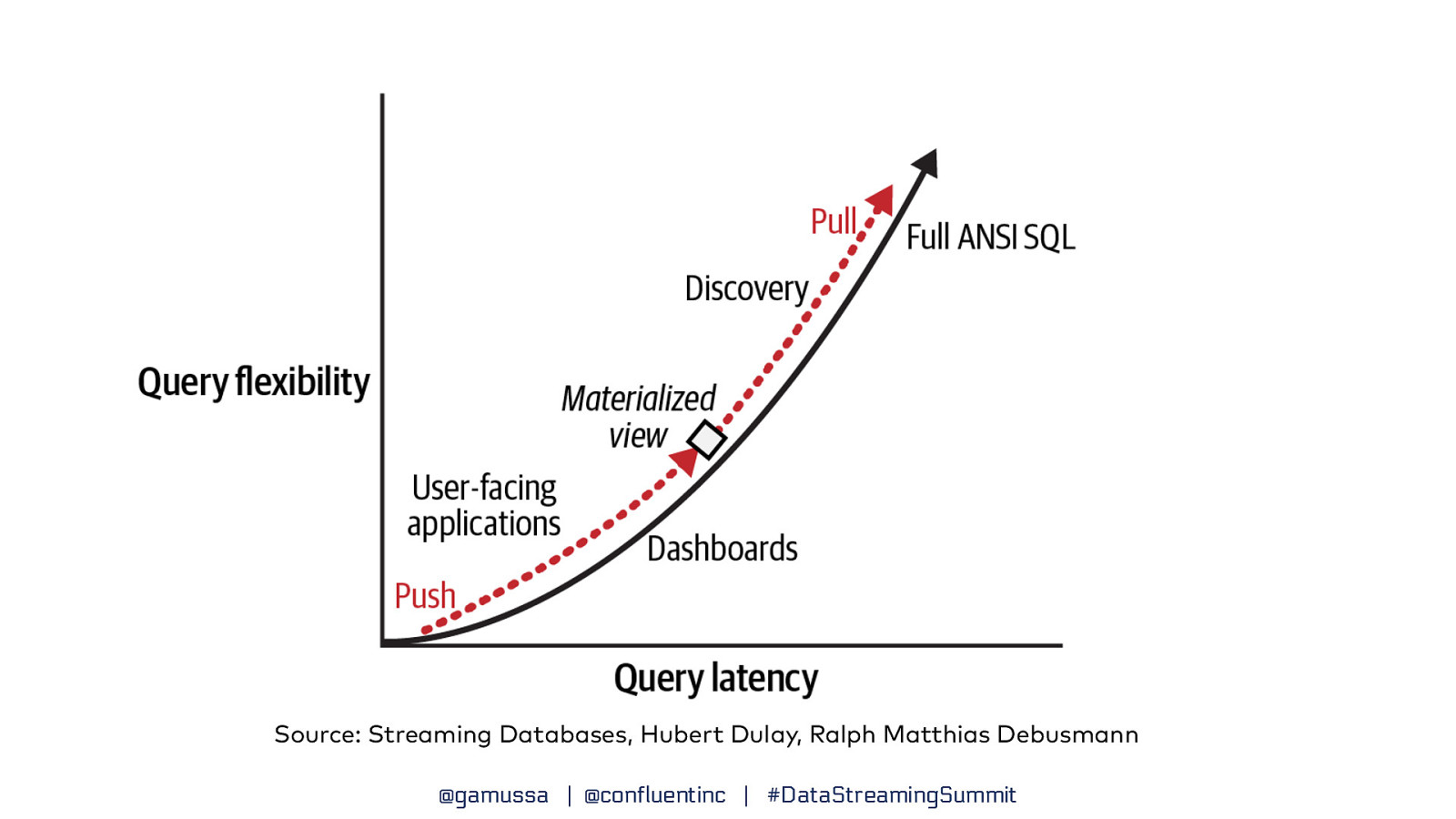
Source: Streaming Databases, Hubert Dulay, Ralph Matthias Debusmann @gamussa | @confluentinc | #DataStreamingSummit

Find the code of the demo 👉 https://gamov.dev/uncorking-analytics @gamussa | @confluentinc | #DataStreamingSummit

Imagine a world where analytics is not just for the boardroom but for everyone, everywhere, every moment. Pinot is not your average OLAP database; it’s a turbocharged engine designed to power features that users interact with, delivering insights faster than you can say “real-time.” We’re talking about lightning-fast queries, sky-high concurrency, and data fresher than your morning coffee. In this talk, we’ll integrate Apache Pulsar, Flink, and Pinot for real-time analytics. You’ll get the inside scoop on how Pinot is built, how to feed it with data from Pulsar or Kafka, and how to use Flink for pre-processing. We’ll showcase how Pinot changes the game, making analytics available at everyone’s fingertips. Get ready to explore the exciting world of real-time analytics with Apache Pulsar, Flink, and Pinot!