Keeping your Data Close and your Caches Hotter
A presentation at In-memory Computing Summit EU 2019 in in London, UK by Viktor Gamov

Keep your Data Close and your Caches Hotter using Apache Kafka, Connect and KSQL @gamussa | @riferrei | #IMCSummit

2 @gamussa | @riferrei | #IMCSummit

Raffle, yeah 🚀

Raffle, yeah 🚀 Follow @gamussa 📸🖼👬 Tag @gamussa @riferrei @riferrei With #IMCSummit

4 Data is only useful if it is Fresh and Contextual @gamussa | @riferrei | #IMCSummit

@gamussa | @riferrei | #IMCSummit

What if the airbag deploys 30 seconds after the collision? @gamussa | @riferrei | #IMCSummit

@gamussa | @riferrei | #IMCSummit

December 6th, 2010: Commuter rail train hits elderly driver @gamussa | @riferrei | #IMCSummit

7 What if the information about the commuter rail train is outdated? @gamussa | @riferrei | #IMCSummit

8

8 March 29th, 2019: Wife said that she had put new toilet paper

9 Caches can be a Solution for Data that is Fresh @gamussa | @riferrei | #IMCSummit
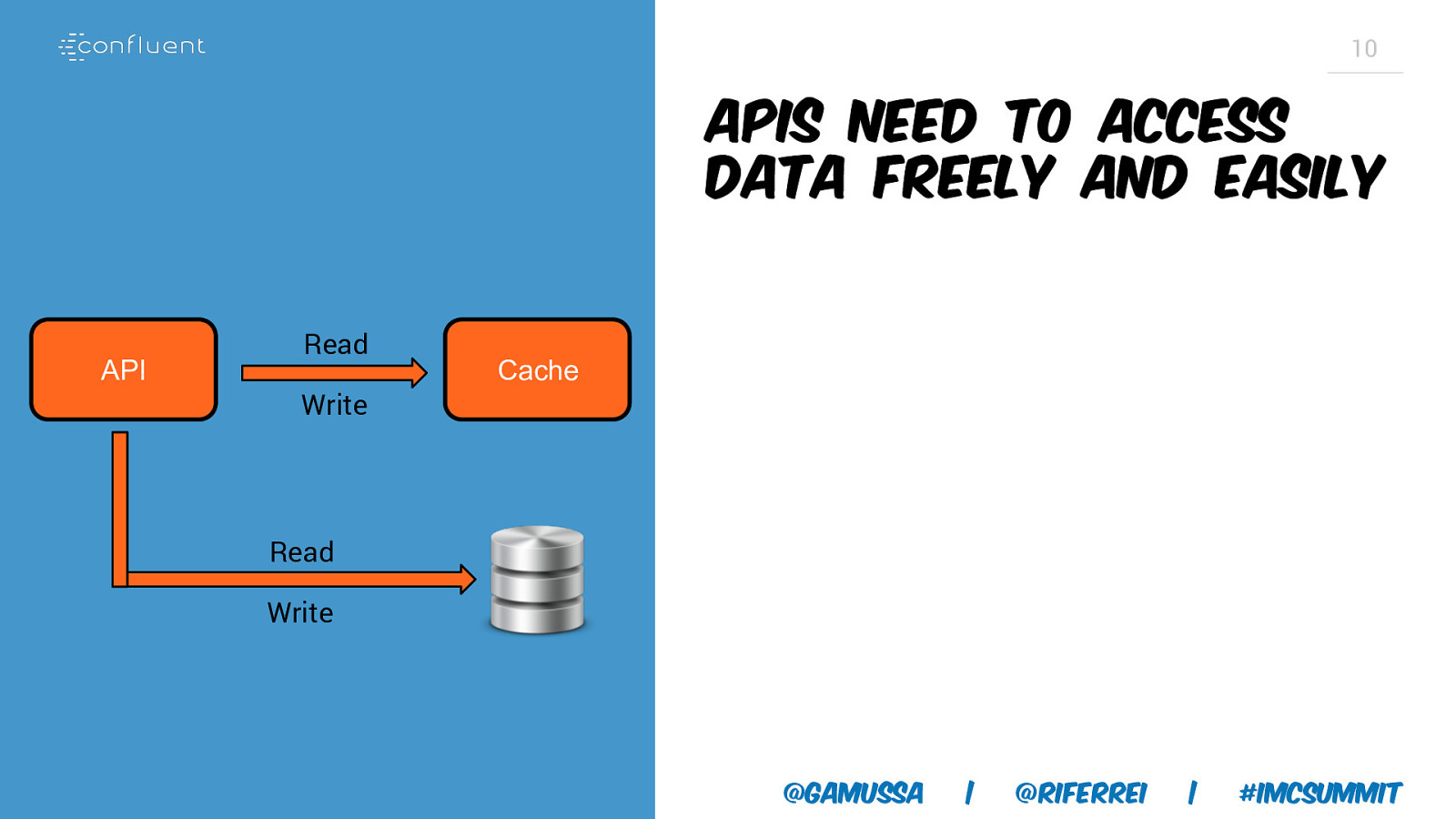
10 APIs need to access data freely and easily API Read Write Cache Read Write @gamussa | @riferrei | #IMCSummit
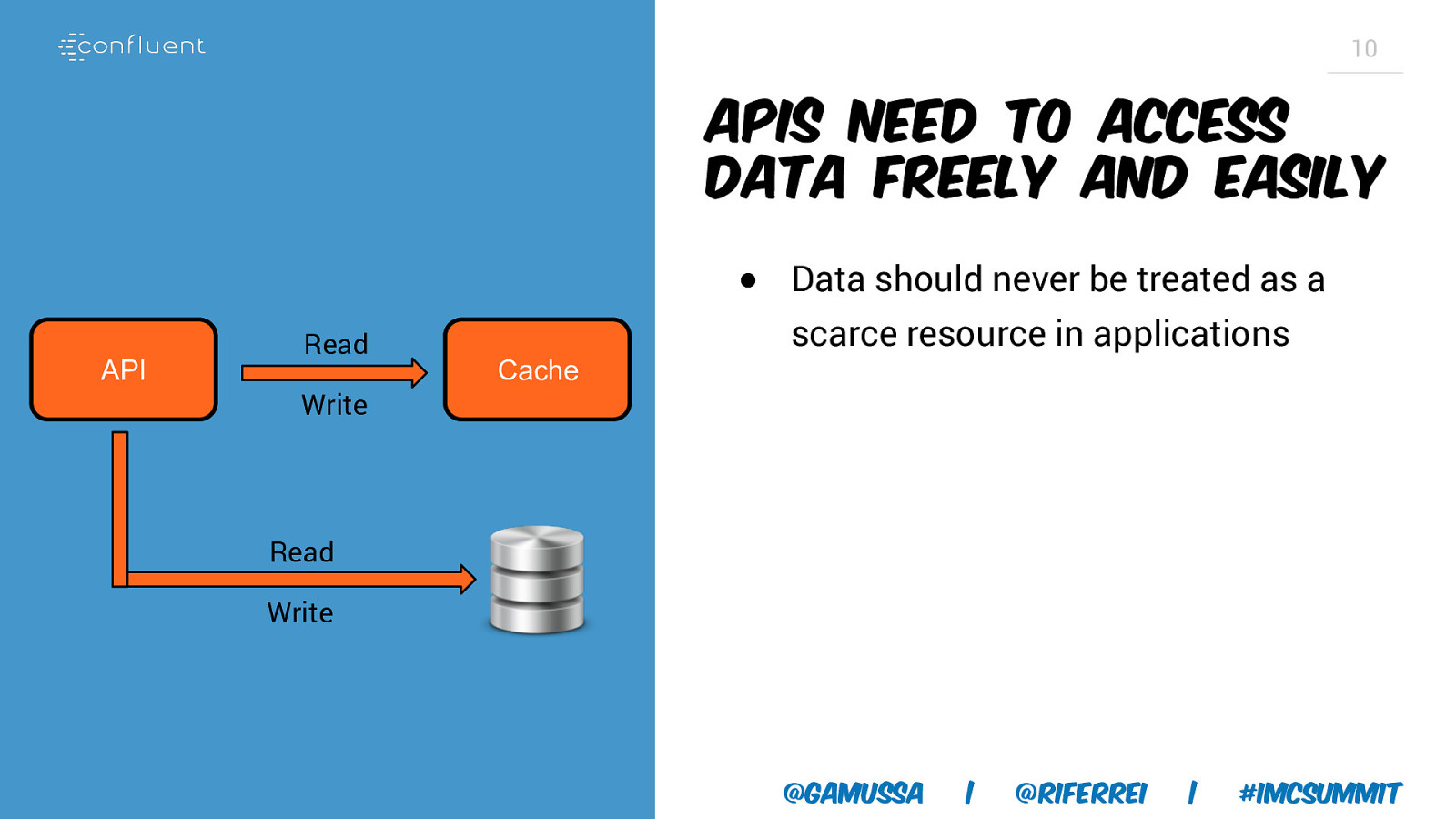
10 APIs need to access data freely and easily ● Data should never be treated as a API Read Write Cache scarce resource in applications Read Write @gamussa | @riferrei | #IMCSummit
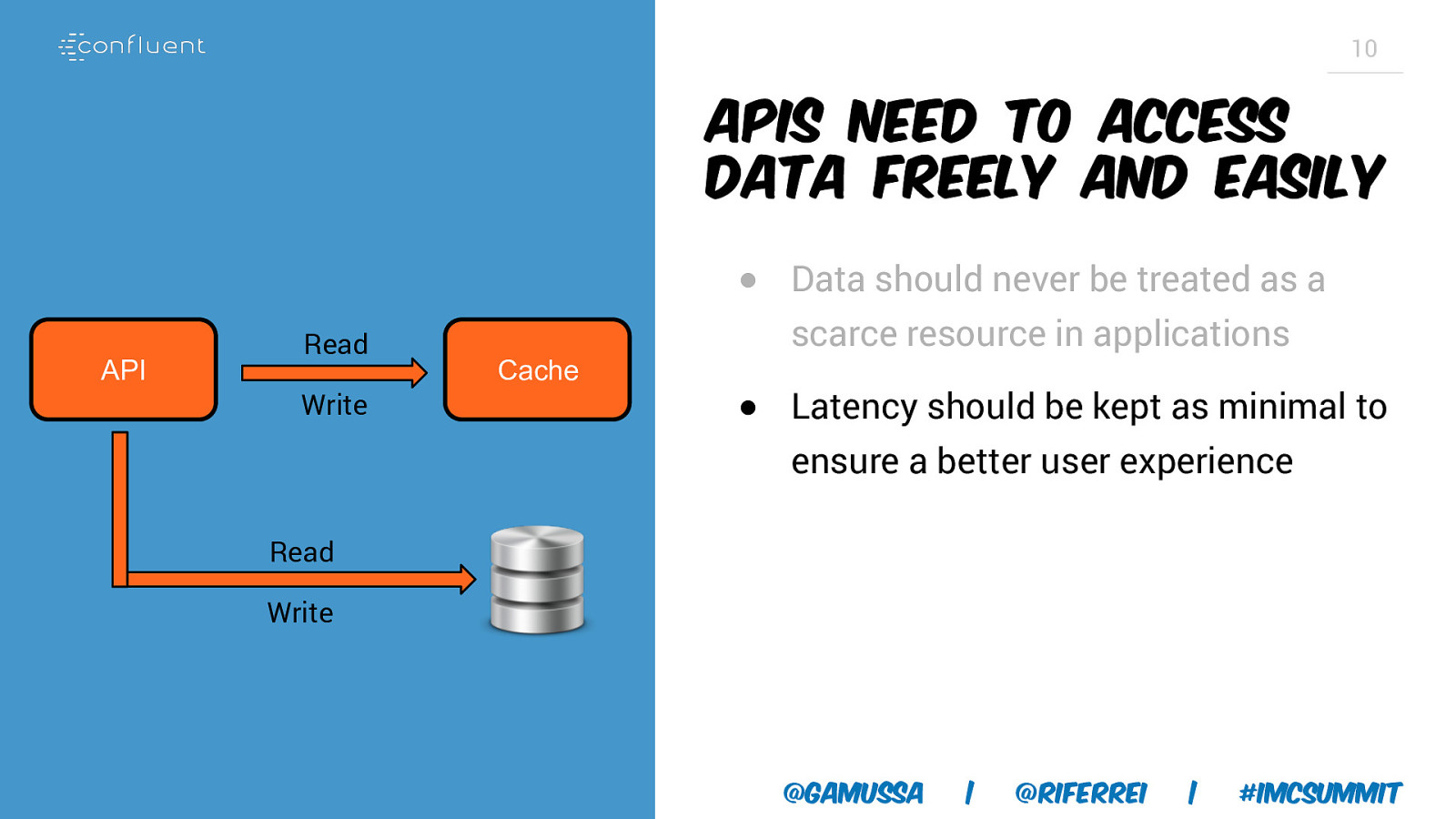
10 APIs need to access data freely and easily ● Data should never be treated as a API Read Write Cache scarce resource in applications ● Latency should be kept as minimal to ensure a better user experience Read Write @gamussa | @riferrei | #IMCSummit
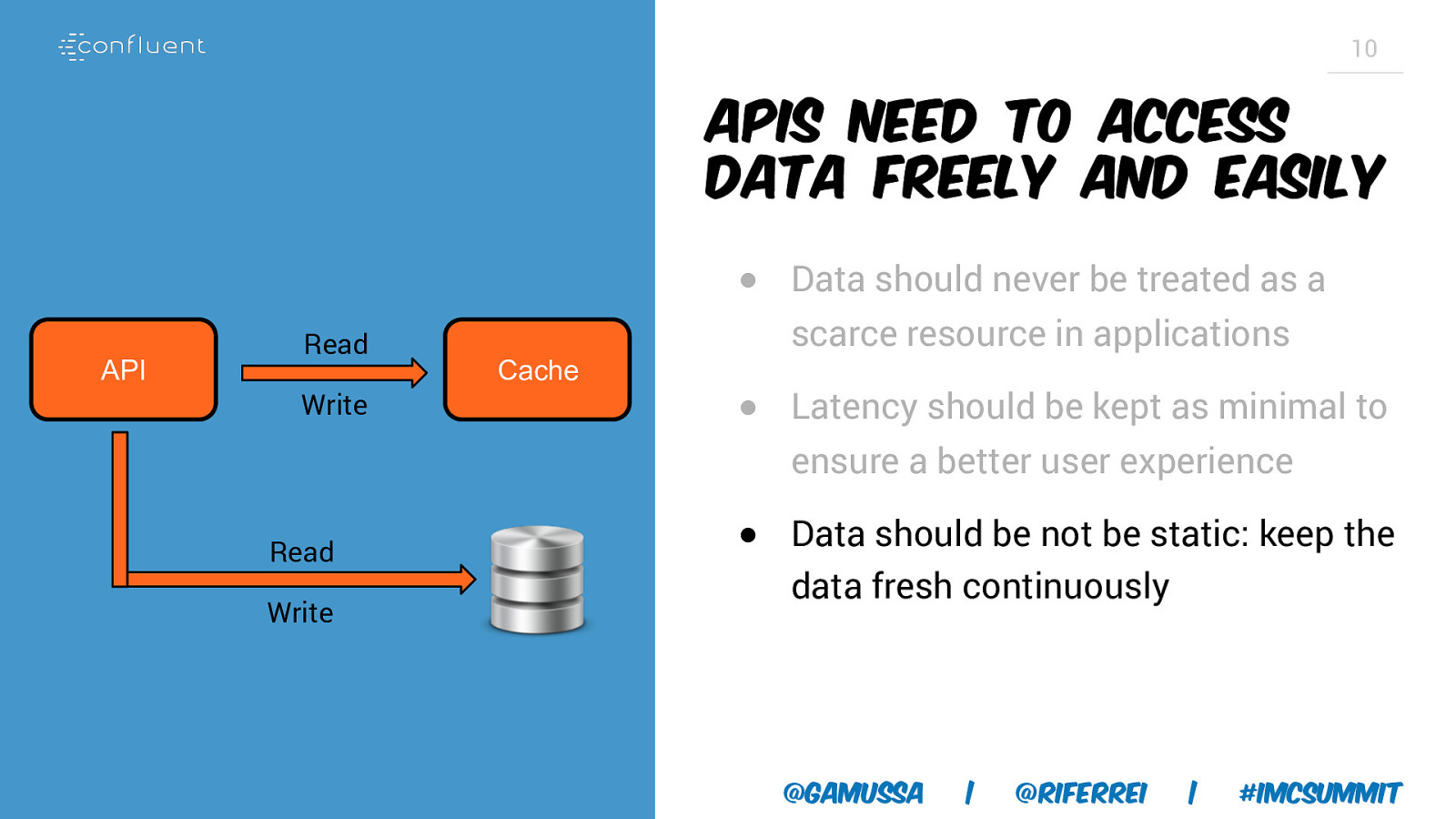
10 APIs need to access data freely and easily ● Data should never be treated as a API Read Write Cache scarce resource in applications ● Latency should be kept as minimal to ensure a better user experience Read Write ● Data should be not be static: keep the data fresh continuously @gamussa | @riferrei | #IMCSummit
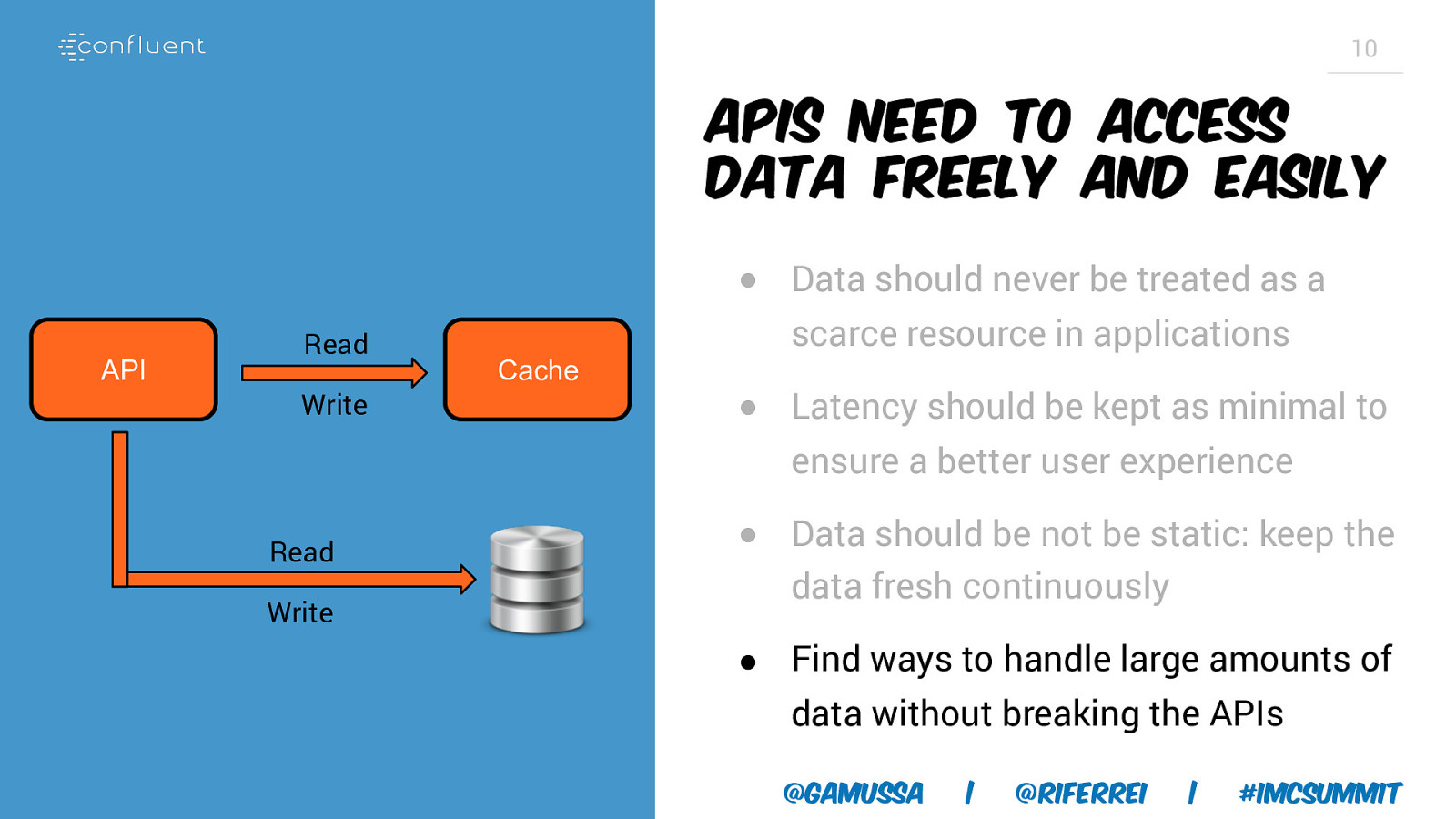
10 APIs need to access data freely and easily ● Data should never be treated as a API Read Write Cache scarce resource in applications ● Latency should be kept as minimal to ensure a better user experience Read Write ● Data should be not be static: keep the data fresh continuously ● Find ways to handle large amounts of data without breaking the APIs @gamussa | @riferrei | #IMCSummit
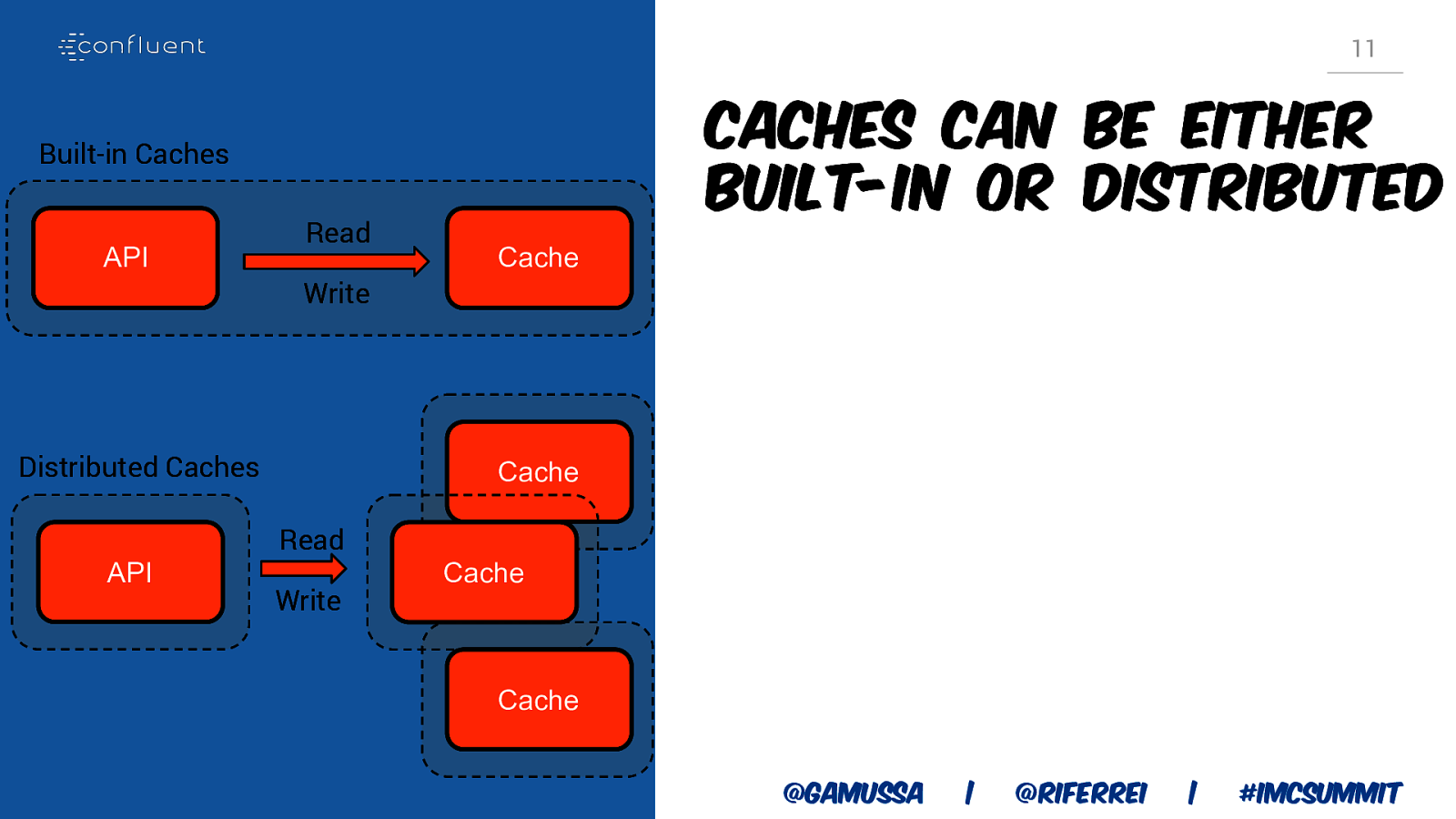
11 Caches can be either built-in or distributed Built-in Caches API Read Cache Write Distributed Caches API Cache Read Write Cache Cache @gamussa | @riferrei | #IMCSummit
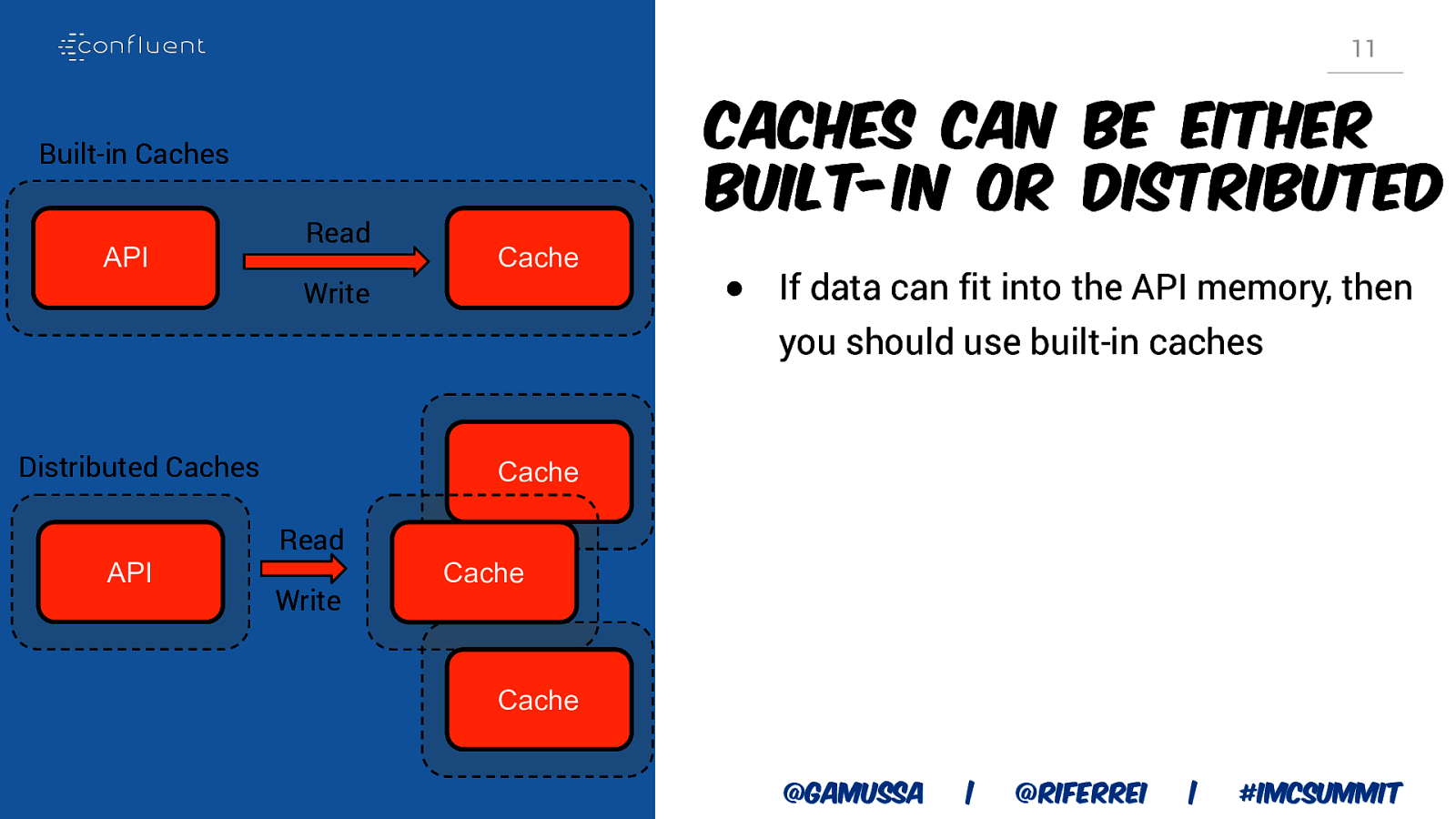
11 Caches can be either built-in or distributed Built-in Caches API Read Cache Write ● If data can fit into the API memory, then you should use built-in caches Distributed Caches API Cache Read Write Cache Cache @gamussa | @riferrei | #IMCSummit
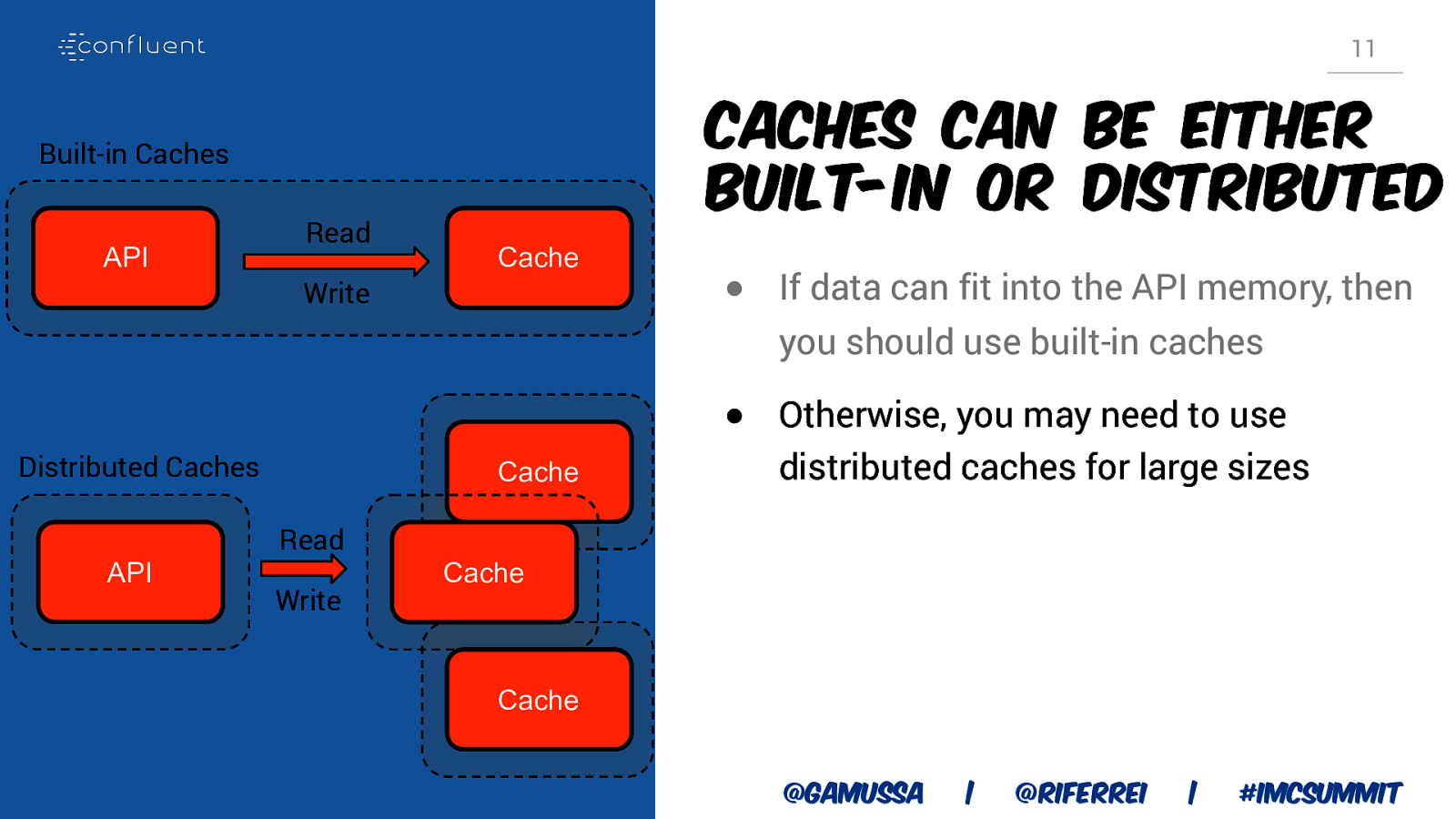
11 Caches can be either built-in or distributed Built-in Caches API Read Cache Write ● If data can fit into the API memory, then you should use built-in caches Distributed Caches API Cache Read Write ● Otherwise, you may need to use distributed caches for large sizes Cache Cache @gamussa | @riferrei | #IMCSummit
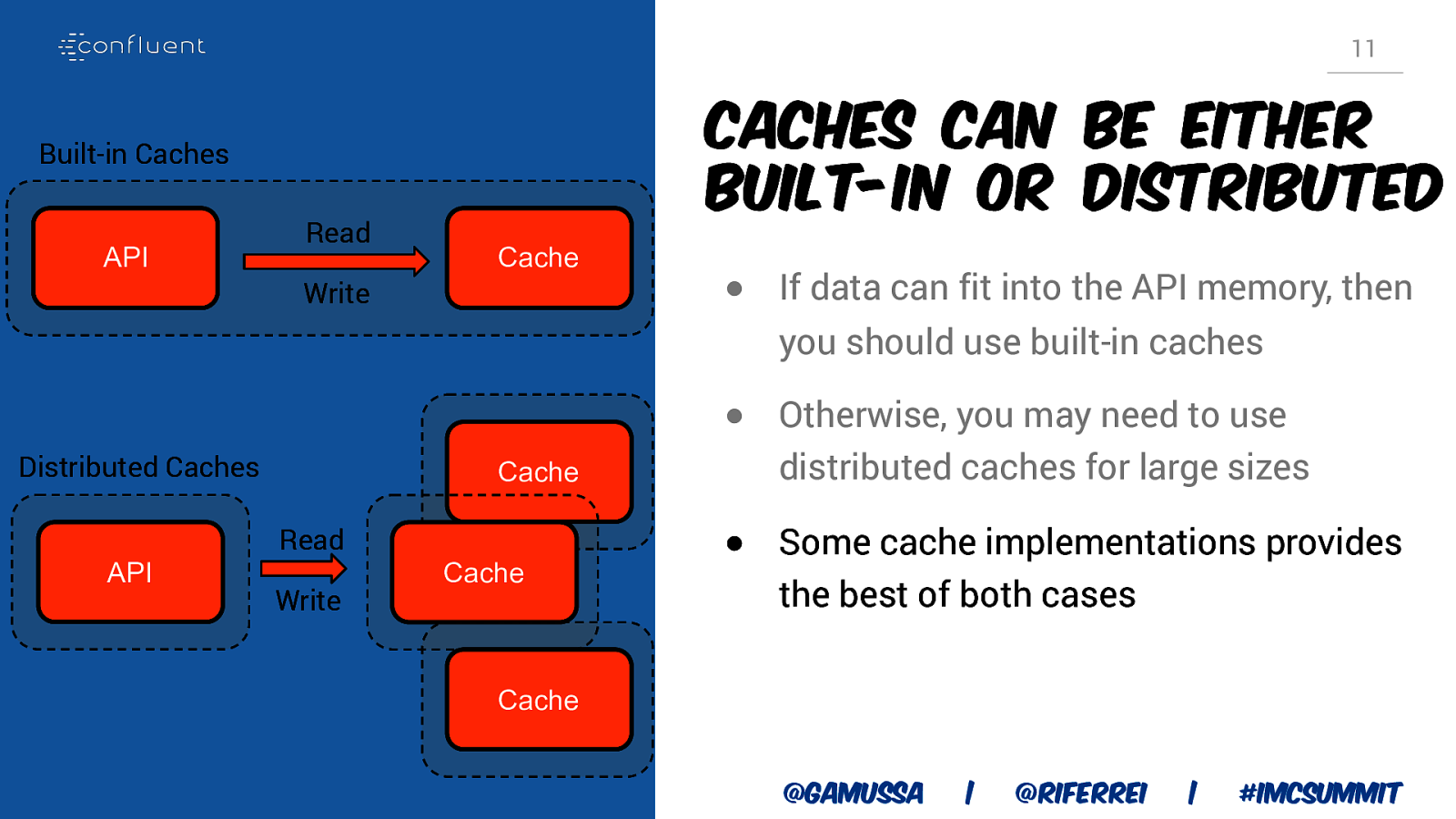
11 Caches can be either built-in or distributed Built-in Caches API Read Cache Write ● If data can fit into the API memory, then you should use built-in caches Distributed Caches API Cache Read Write Cache ● Otherwise, you may need to use distributed caches for large sizes ● Some cache implementations provides the best of both cases Cache @gamussa | @riferrei | #IMCSummit
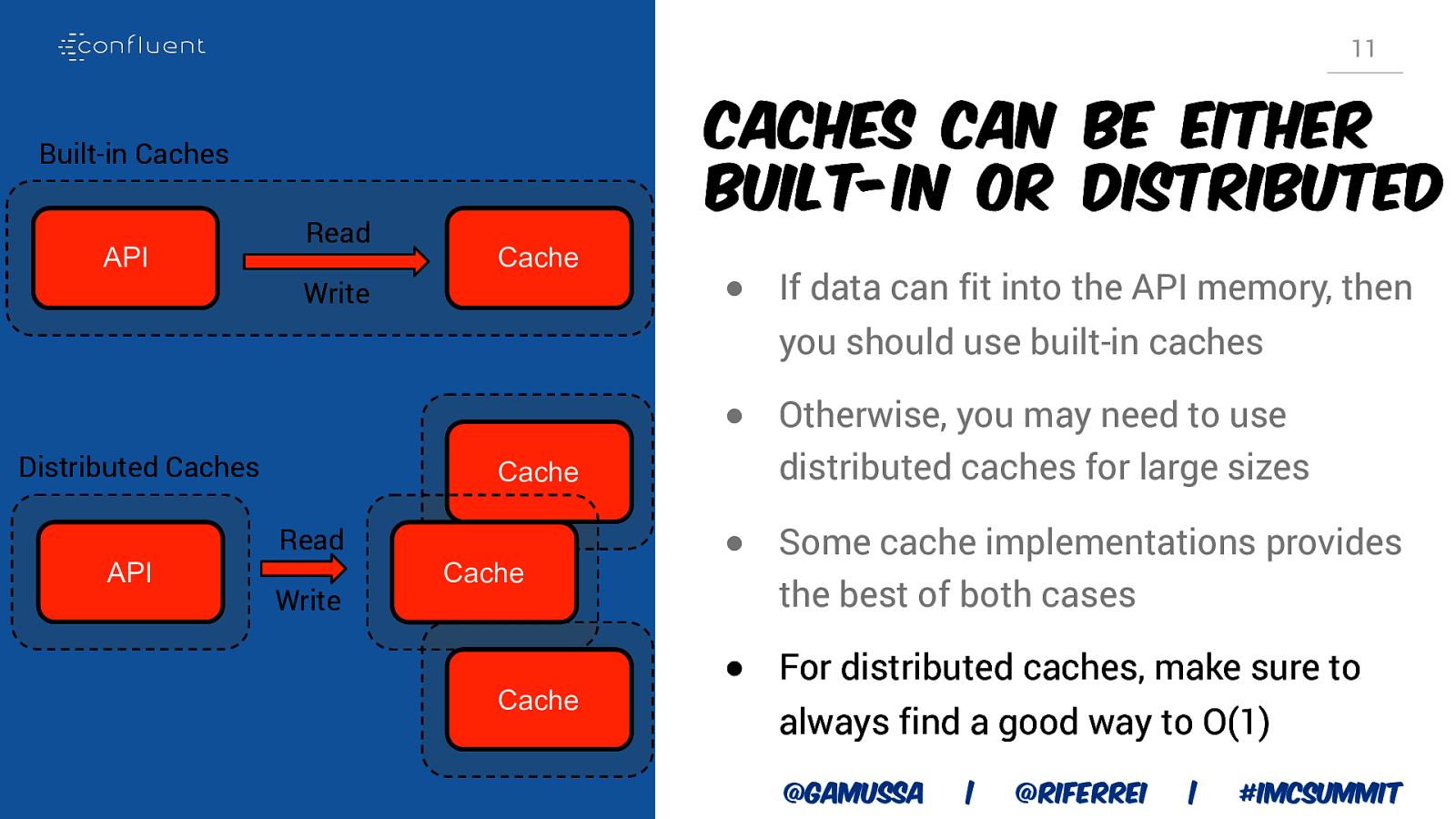
11 Caches can be either built-in or distributed Built-in Caches API Read Cache Write ● If data can fit into the API memory, then you should use built-in caches Distributed Caches API Cache Read Write Cache Cache ● Otherwise, you may need to use distributed caches for large sizes ● Some cache implementations provides the best of both cases ● For distributed caches, make sure to always find a good way to O(1) @gamussa | @riferrei | #IMCSummit

12 DEMO @gamussa | @riferrei | #IMCSummit
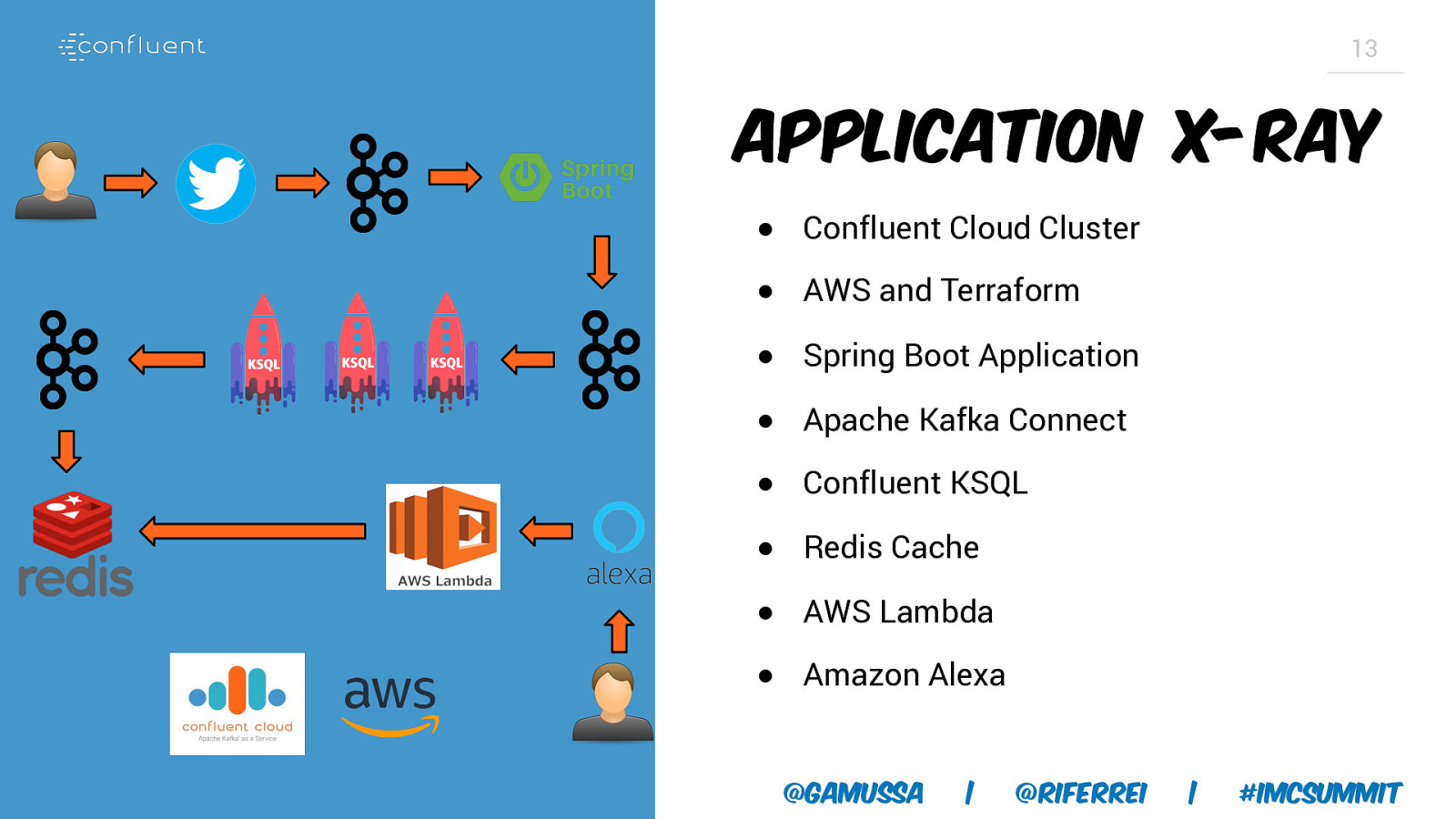
13 Application x-ray ● Confluent Cloud Cluster ● AWS and Terraform ● Spring Boot Application ● Apache Kafka Connect ● Confluent KSQL ● Redis Cache ● AWS Lambda ● Amazon Alexa @gamussa | @riferrei | #IMCSummit

14 sourcecode of this application @gamussa | @riferrei | #IMCSummit

15 Caching Patterns @gamussa | @riferrei | #IMCSummit
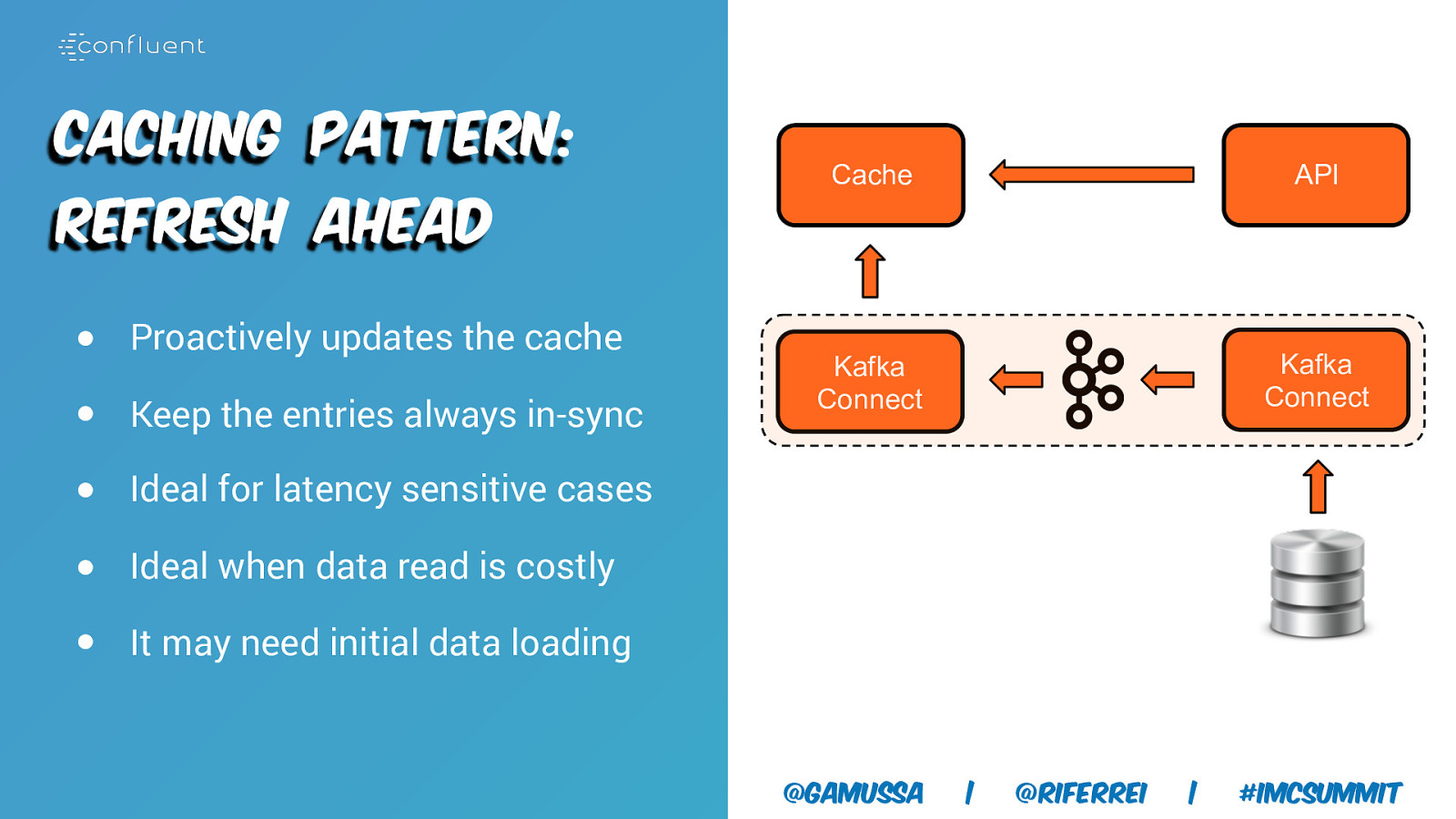
Caching Pattern: Cache API Kafka Connect Kafka Connect Refresh Ahead ● Proactively updates the cache ● Keep the entries always in-sync ● Ideal for latency sensitive cases ● Ideal when data read is costly ● It may need initial data loading @gamussa | @riferrei | #IMCSummit
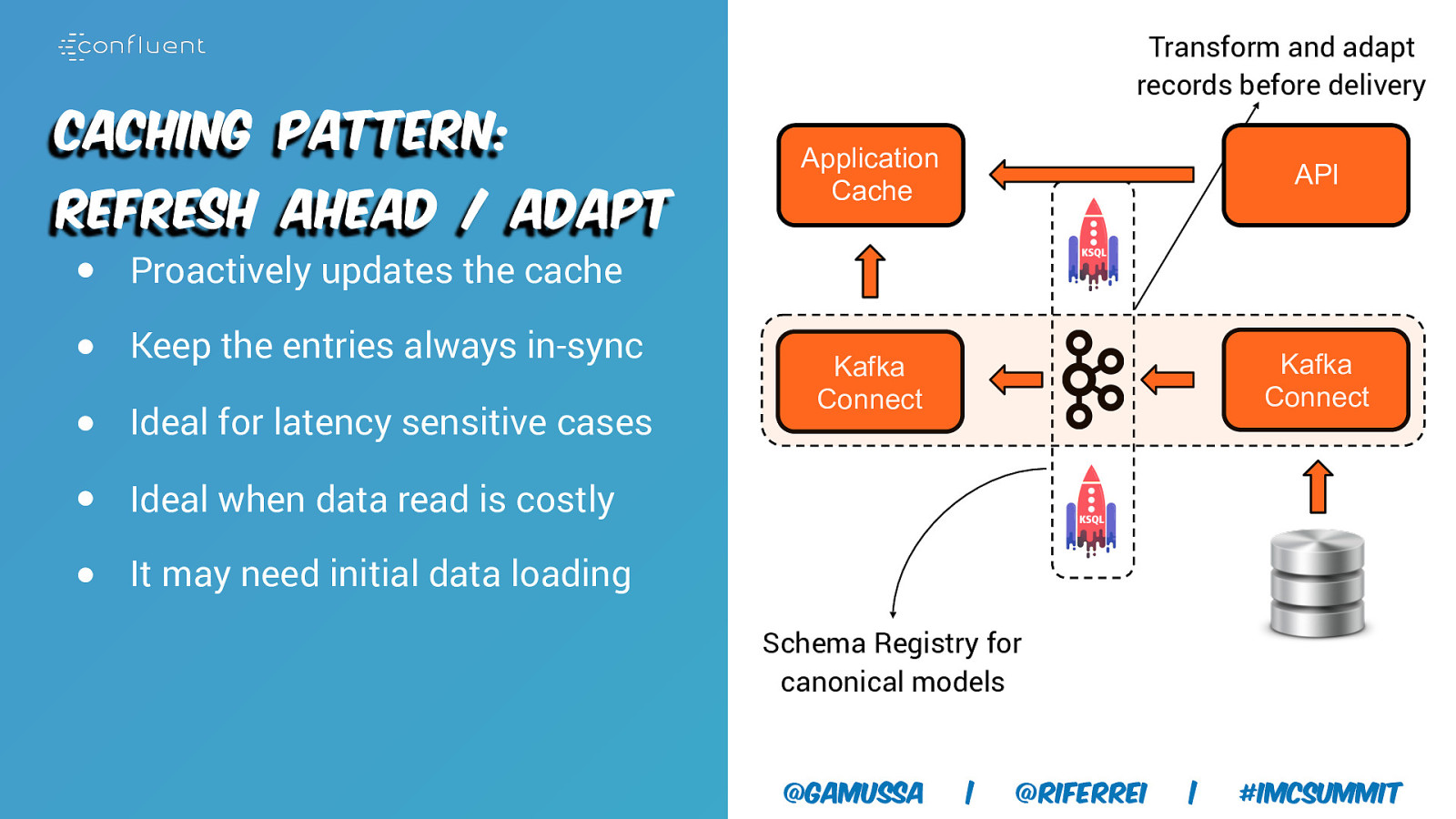
Transform and adapt records before delivery Caching Pattern: Refresh Ahead / Adapt Application Cache API Kafka Connect Kafka Connect ● Proactively updates the cache ● Keep the entries always in-sync ● Ideal for latency sensitive cases ● Ideal when data read is costly ● It may need initial data loading Schema Registry for canonical models @gamussa | @riferrei | #IMCSummit
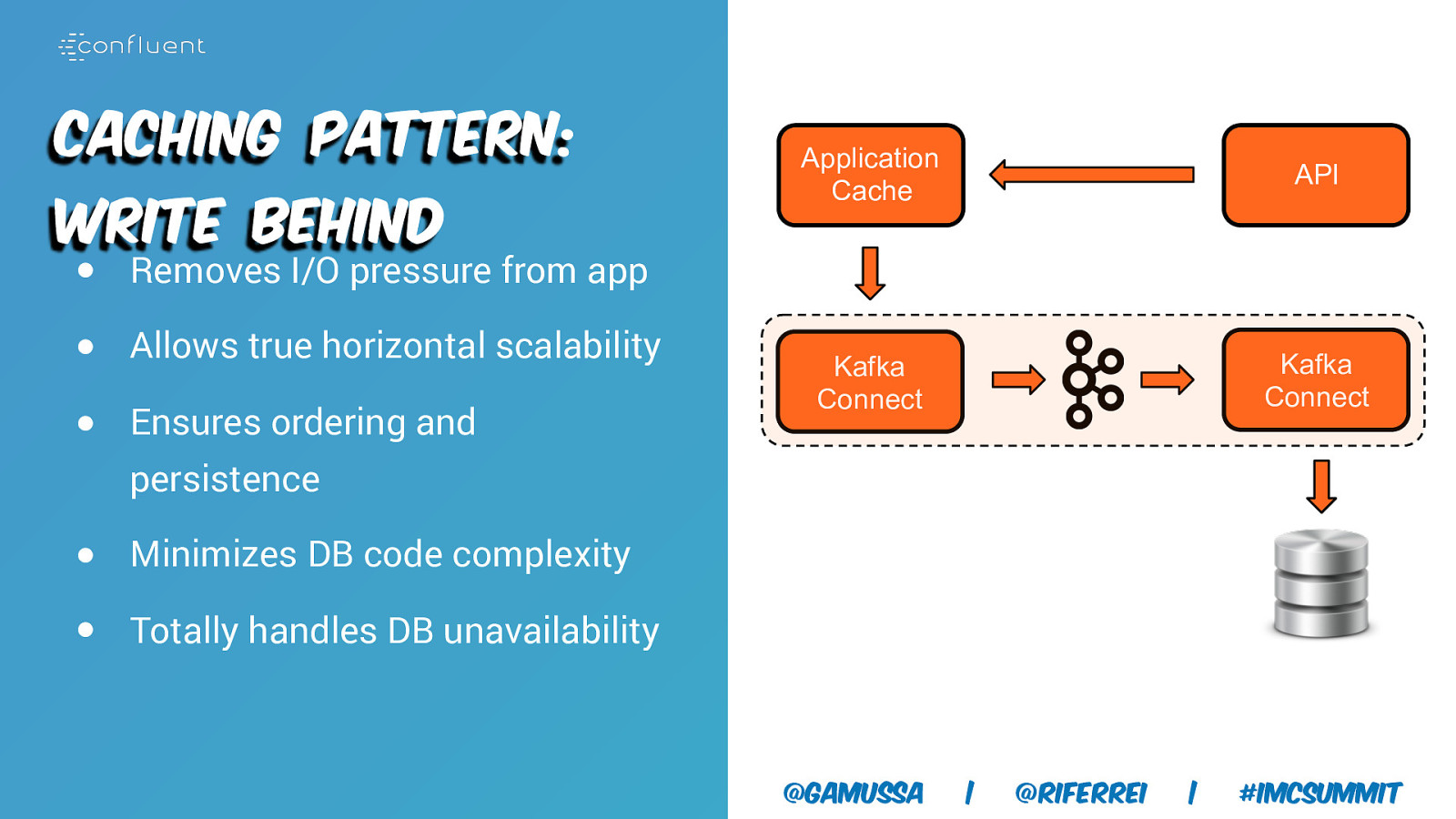
Caching Pattern: Write Behind Application Cache API Kafka Connect Kafka Connect ● Removes I/O pressure from app ● Allows true horizontal scalability ● Ensures ordering and persistence ● Minimizes DB code complexity ● Totally handles DB unavailability @gamussa | @riferrei | #IMCSummit
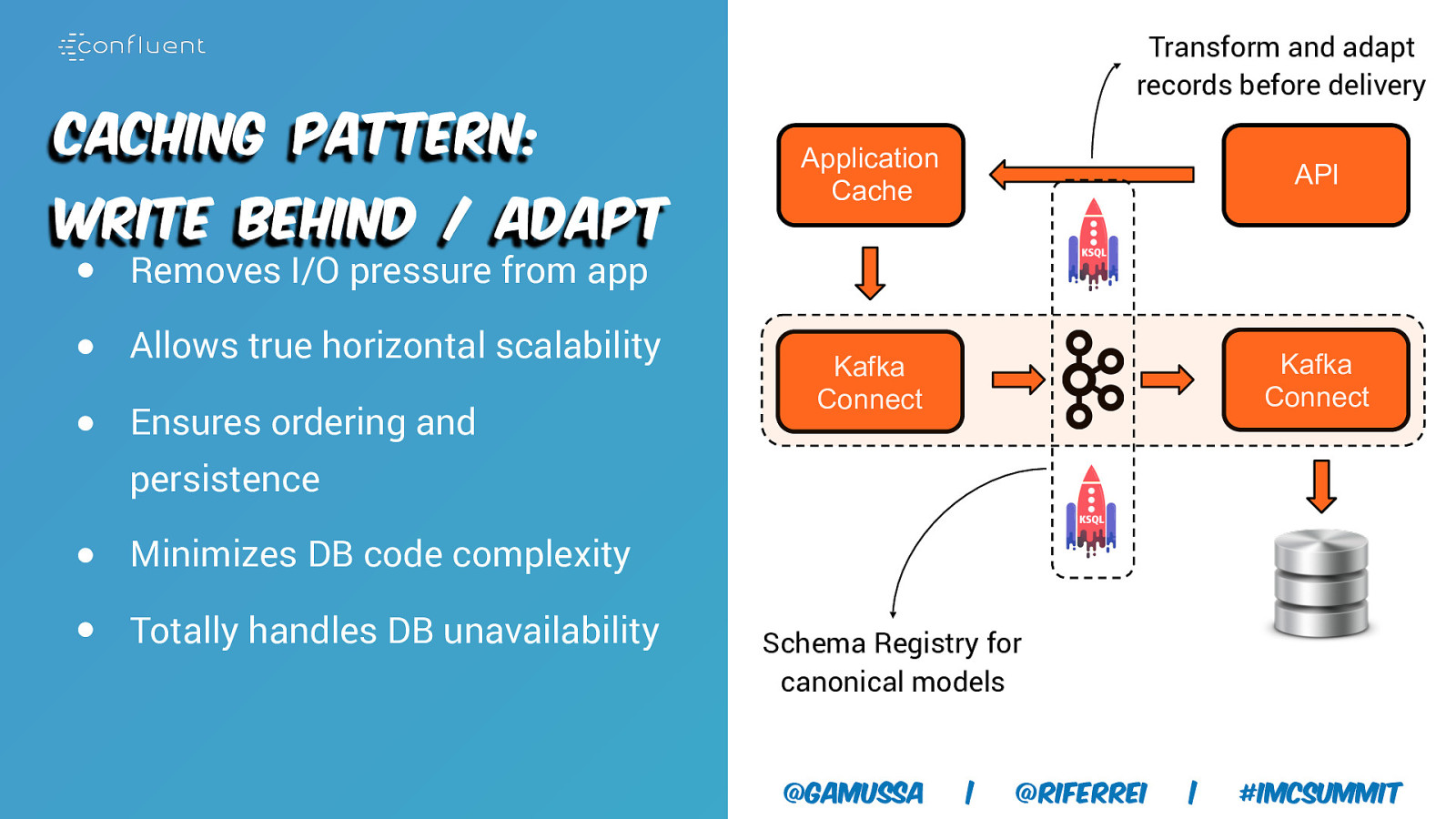
Transform and adapt records before delivery Caching Pattern: Write Behind / Adapt Application Cache API Kafka Connect Kafka Connect ● Removes I/O pressure from app ● Allows true horizontal scalability ● Ensures ordering and persistence ● Minimizes DB code complexity ● Totally handles DB unavailability Schema Registry for canonical models @gamussa | @riferrei | #IMCSummit
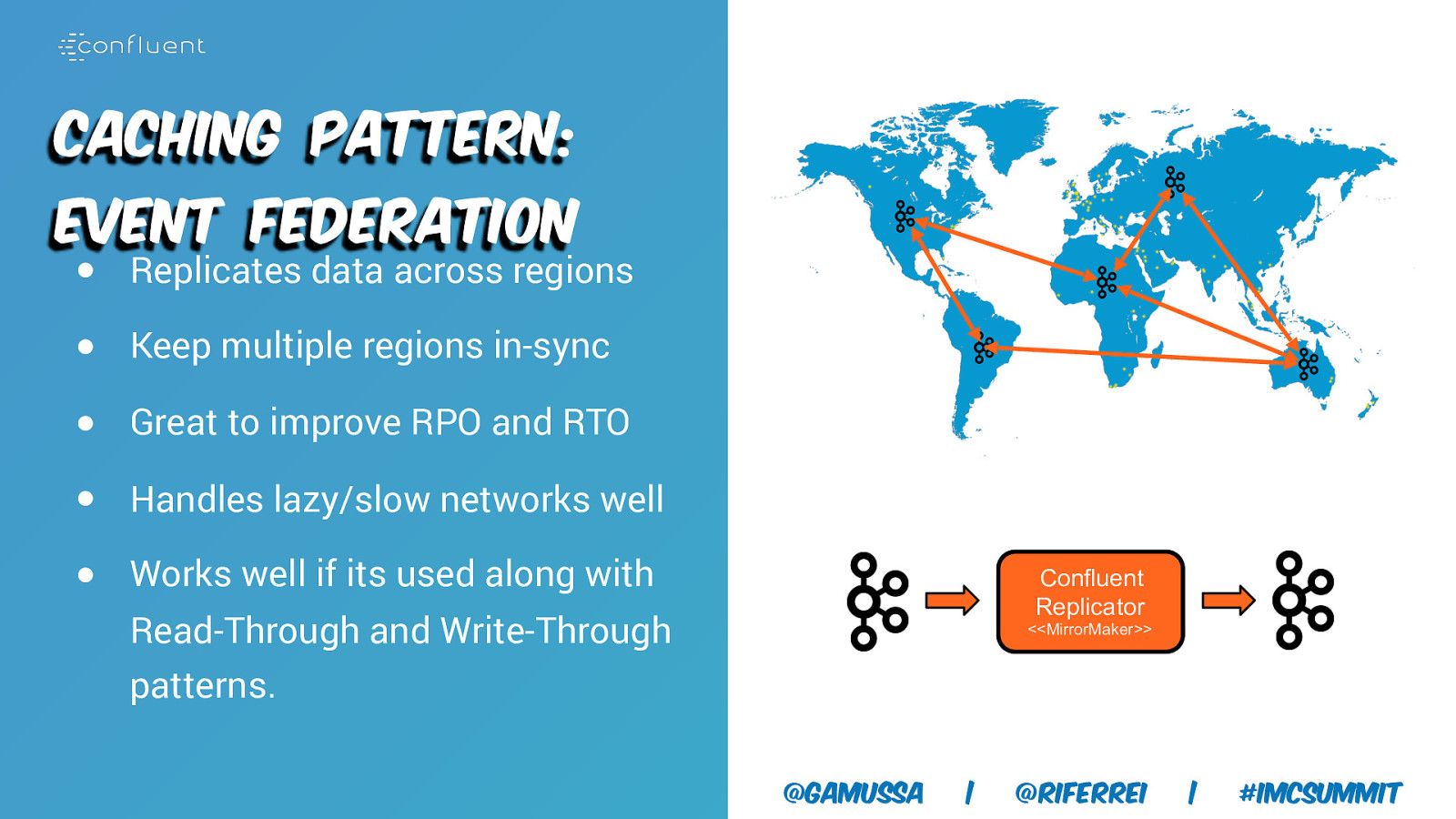
Caching Pattern: Event Federation ● Replicates data across regions ● Keep multiple regions in-sync ● Great to improve RPO and RTO ● Handles lazy/slow networks well ● Works well if its used along with Confluent Replicator Read-Through and Write-Through patterns. <<MirrorMaker>> @gamussa | @riferrei | #IMCSummit

21 Kafka Connect Implementation Strategies @gamussa | @riferrei | #IMCSummit
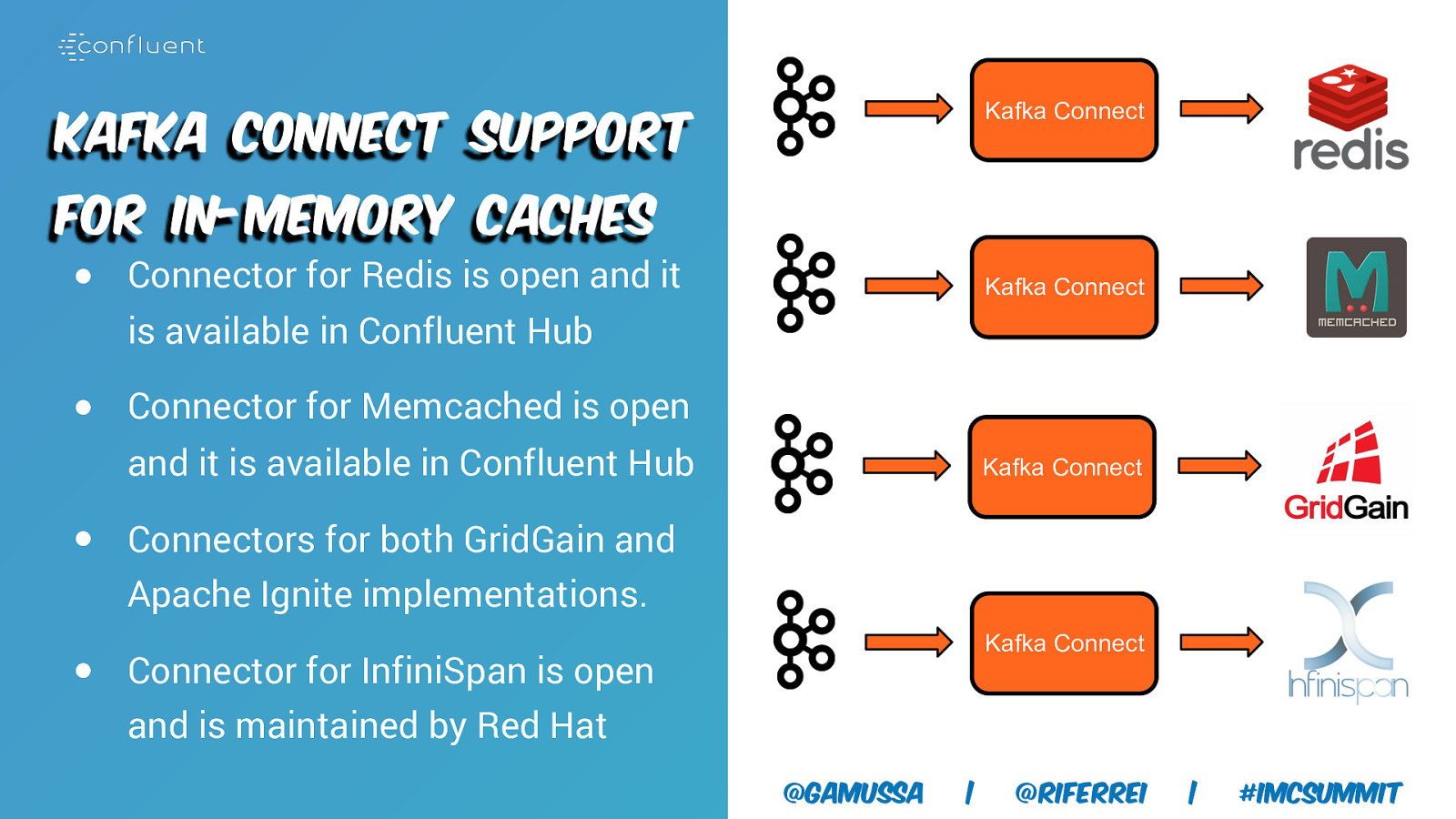
Kafka Connect Kafka Connect support for In-Memory Caches ● Connector for Redis is open and it Kafka Connect is available in Confluent Hub ● Connector for Memcached is open and it is available in Confluent Hub Kafka Connect ● Connectors for both GridGain and Apache Ignite implementations. Kafka Connect ● Connector for InfiniSpan is open and is maintained by Red Hat @gamussa | @riferrei | #IMCSummit
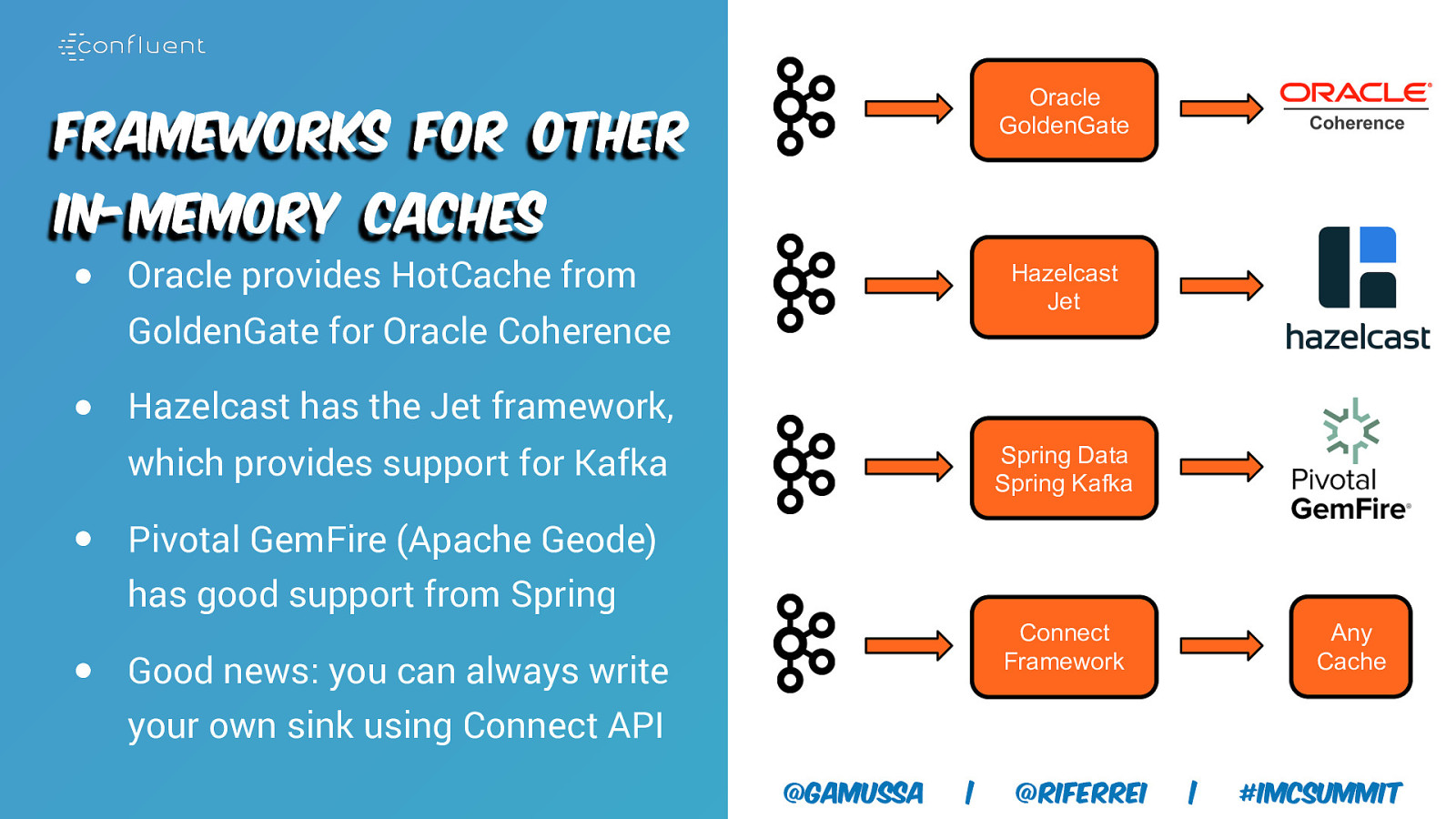
Oracle GoldenGate Frameworks for other In-Memory Caches ● Oracle provides HotCache from Hazelcast Jet GoldenGate for Oracle Coherence ● Hazelcast has the Jet framework, which provides support for Kafka Spring Data Spring Kafka ● Pivotal GemFire (Apache Geode) has good support from Spring Connect Framework ● Good news: you can always write your own sink using Connect API @gamussa | @riferrei Any Cache | #IMCSummit

Interested on DB CDC? Then meet Debezium! ● Amazing CDC technology to pull data out from databases to Kafka ● Works in a log level, which means true CDC implementation for your projects instead of record polling ● Open-source maintained by Red Hat. Have broad support for many popular databases. ● It is built on top of Kafka Connect @gamussa | @riferrei | #IMCSummit
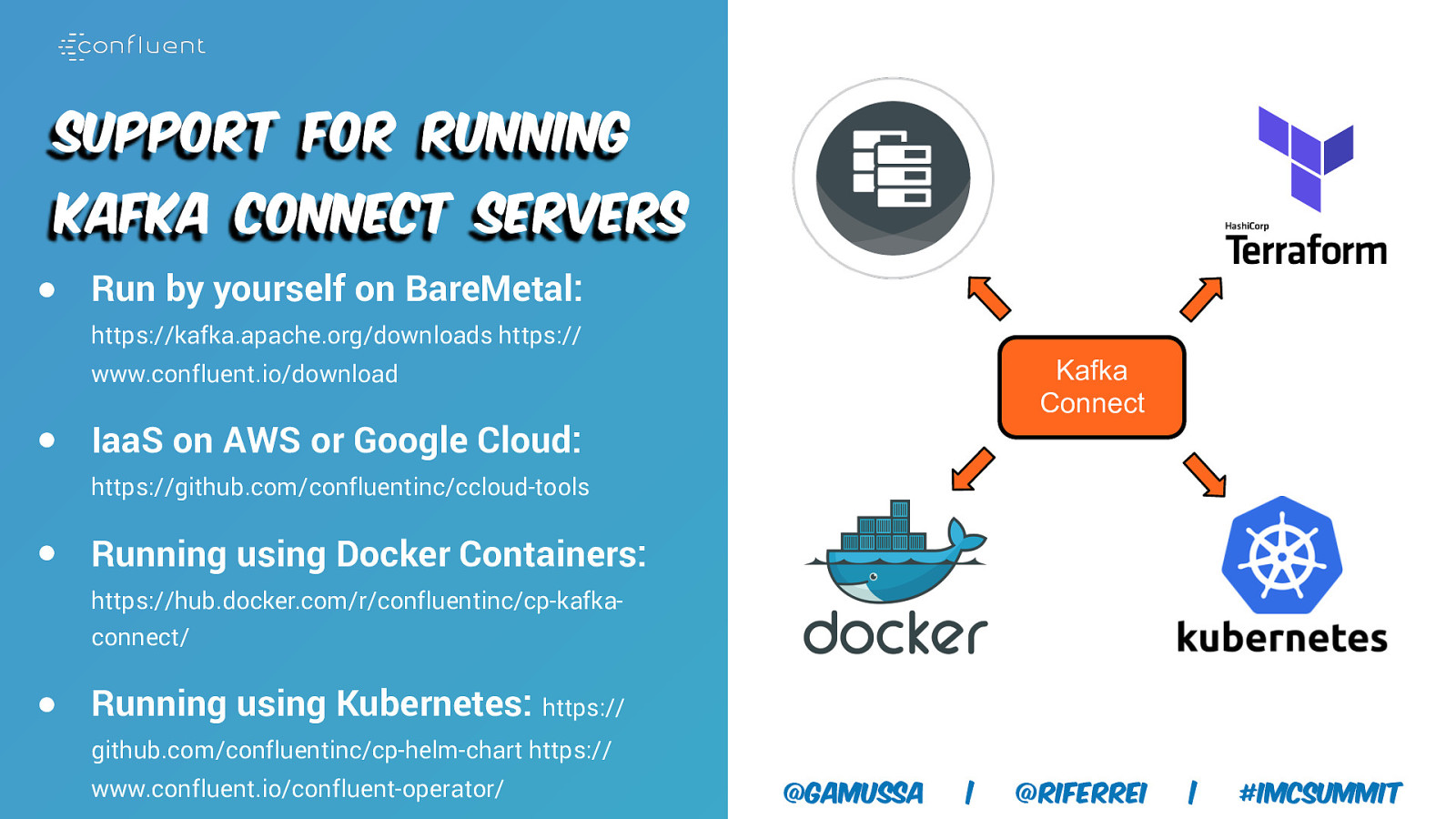
Support for Running Kafka Connect Servers ● Run by yourself on BareMetal: https://kafka.apache.org/downloads https:// Kafka Connect www.confluent.io/download ● IaaS on AWS or Google Cloud: https://github.com/confluentinc/ccloud-tools ● Running using Docker Containers: https://hub.docker.com/r/confluentinc/cp-kafkaconnect/ ● Running using Kubernetes: https:// github.com/confluentinc/cp-helm-chart https:// www.confluent.io/confluent-operator/ @gamussa | @riferrei | #IMCSummit
26 Stay in touch cnfl.io/blog cnfl.io/slack cnfl.io/meetups

Thanks! @riferrei ricardo@confluent.io @gamussa viktor@confluent.io https://slackpass.io/confluentcommunity #connect #ksql @gamussa | @riferrei @ | #IMCSummit

28

Presented by: Ricardo Ferreira Viktor Gamov, Confluent
The distributed cache is becoming a popular technique to improve performance and simplify the data access layer when dealing with databases. Bringing the data as close as possible to the CPU allows unparalleled execution speed as well as horizontal scalability. This approach is often successful when used in a microservices design in which the cache is accessed only by a single API. However, it becomes more challenging if multiple applications are involved and changes are made to the database directly by other applications. The data held in the cache eventually becomes stale and no longer consistent with its underlying database. When consistency problems arise, the Engineering team must address that through additional coding — which directly jeopardizes the team’s ability to be agile between releases. This talk presents a set of patterns for cache-based architectures that aim to keep the caches always hot; by using Apache Kafka and its connectors to accomplish that goal. It will be shown how to set up these patterns across different IMDGs such as Hazelcast, Apache Ignite or Coherence. These patterns can be used in conjunction with different cache topologies such as cache-aside, read-through, write-behind, and refresh-ahead, making it reusable enough to be used as a framework to achieve data consistency in any architecture that relies on distributed caches.