Kafka on Kubernetes: Does it really have to be “The Hard Way”?
A presentation at Cloud Native Day in in Montreal, QC, Canada by Viktor Gamov

Kafka on Kubernetes: Does it really have to be «The Hard Way»? June, 2019 / Montreal, CA, 2019 @gamussa @gamussa || #ImCloudNative #ImCloudNative || @ConfluentINc @ConfluentINc

2 @gamussa | #ImCloudNative | @ConfluentINc

3 I build highly scalable Hello World apps @gamussa | #ImCloudNative | @ConfluentINc

Raffle, yeah 🚀 Follow @gamussa @confluentinc 📸🖼👬 Tag @gamussa With #ImCloudNative

5 A company is build on DATA FLOWS but All we have is DATA STORES @gamussa | #ImCloudNative | @ConfluentINc
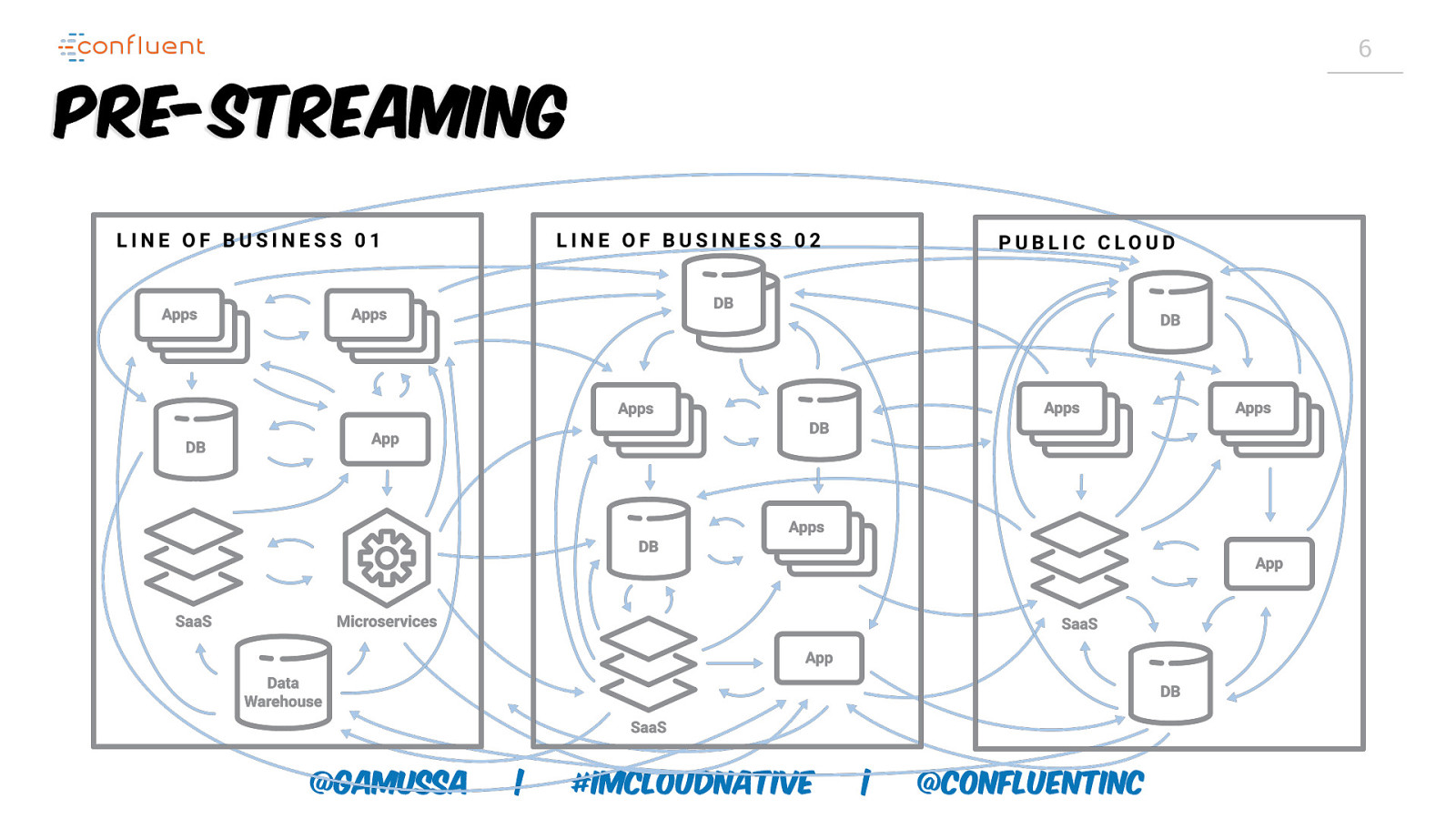
6 Pre-Streaming @gamussa | #ImCloudNative | @ConfluentINc
7 @gamussa | #ImCloudNative | @ConfluentINc
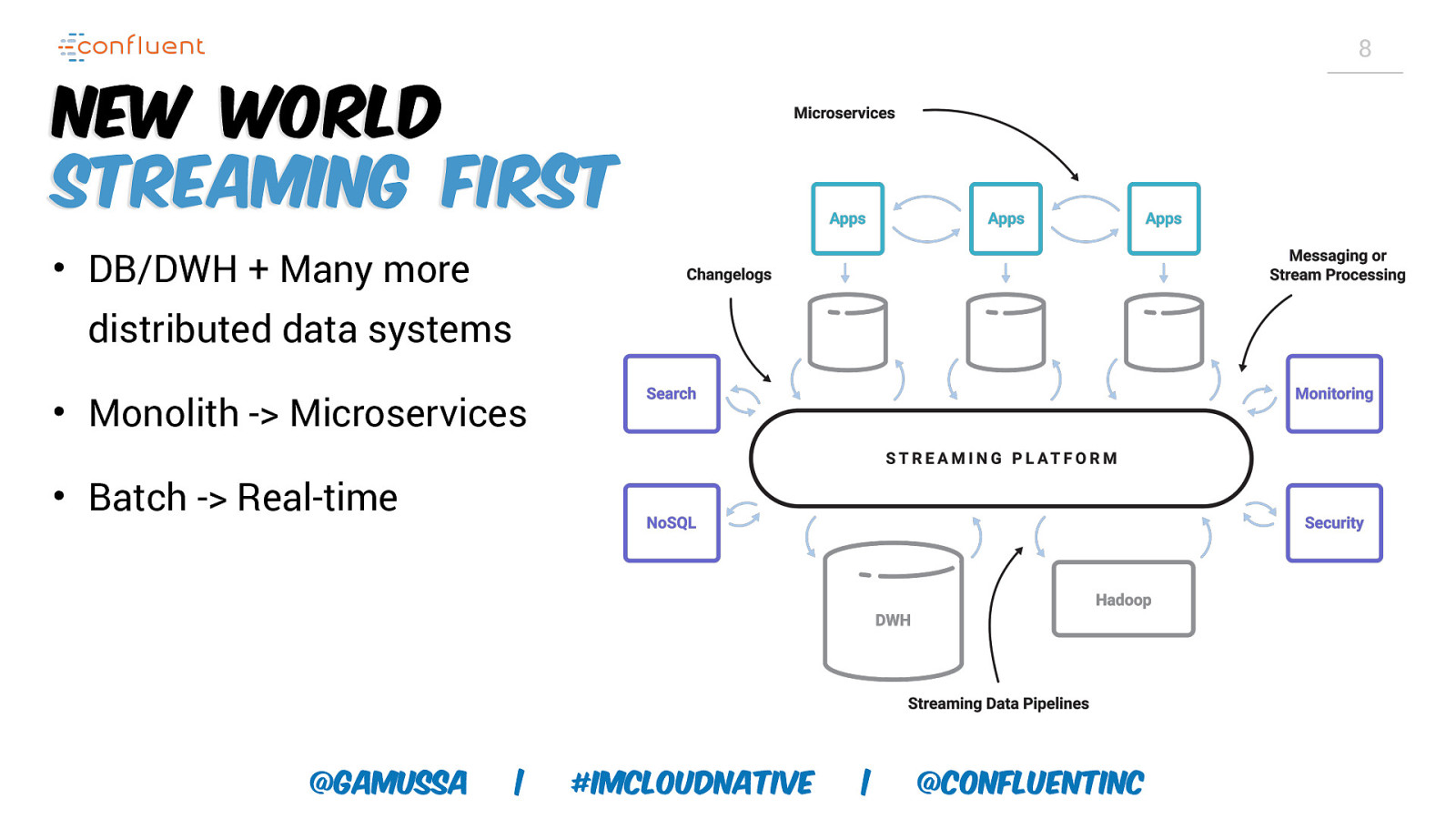
8 New World Streaming first • DB/DWH + Many more distributed data systems • Monolith -> Microservices • Batch -> Real-time @gamussa | #ImCloudNative | @ConfluentINc

9 Evolution of #devkafkaops ansible/chef Docker Kubernetes Shell scripts @gamussa | #ImCloudNative | @ConfluentINc
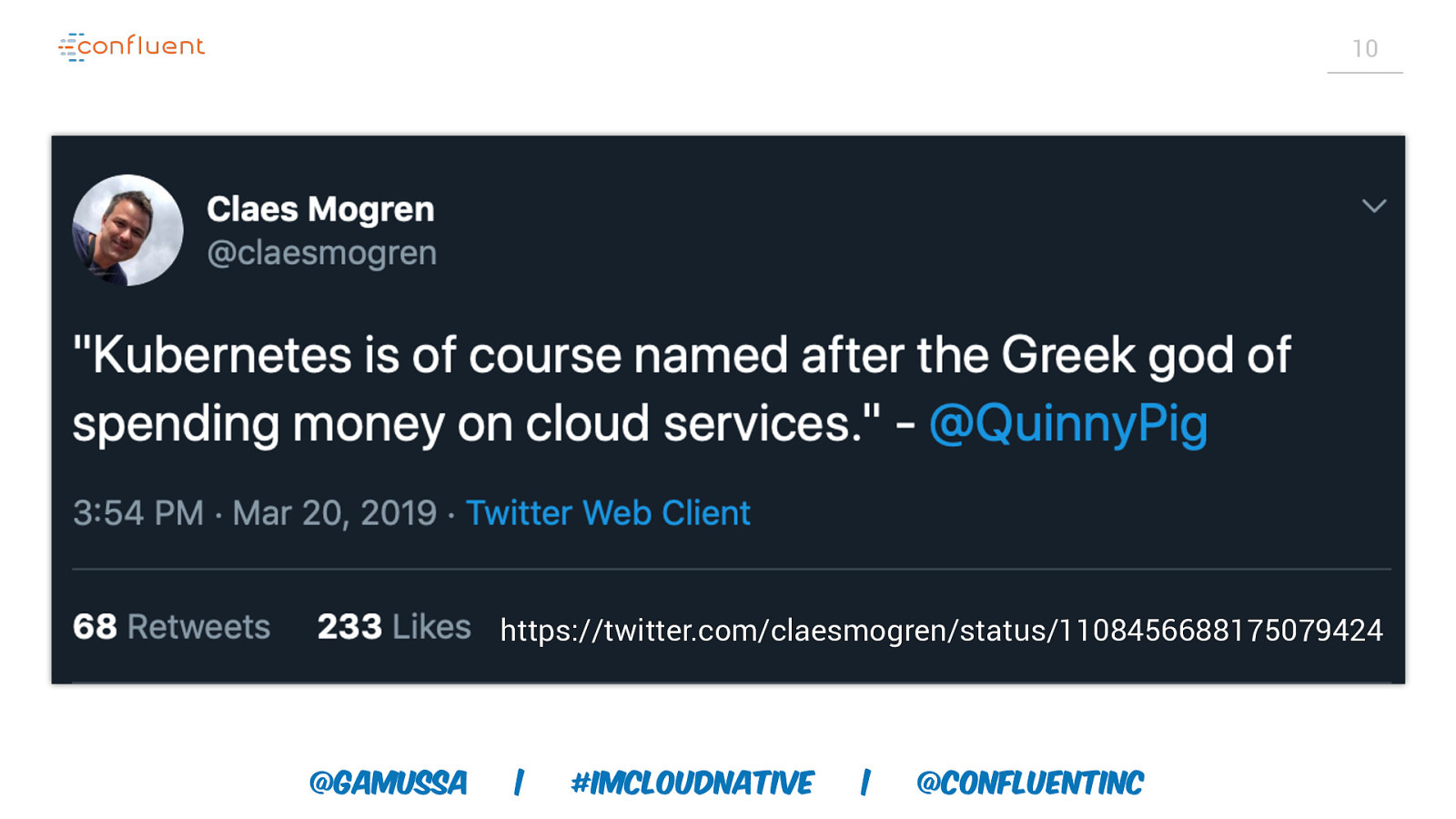
10 https://twitter.com/claesmogren/status/1108456688175079424 @gamussa | #ImCloudNative | @ConfluentINc

11 🙋 @gamussa | #ImCloudNative | @ConfluentINc

12 Who run stateless workloads in Kubernetes? 🙋 Who thinks it’s a good idea? Who run stateful workloads in Kubernetes? Who thinks it’s a good idea? @gamussa | #ImCloudNative | @ConfluentINc

13 kafkaesque world of Kafka on Kubernetes @gamussa | #ImCloudNative | @ConfluentINc

14 #devkafkaops Well, it’s tricky © Translating an existing architecture to Kubernetes External access to brokers and other components Persistent Storage options on prem and clouds Security Configuration and Upgrades @gamussa | #ImCloudNative | @ConfluentINc

15 But I just want to deploy kafka @gamussa | #ImCloudNative | @ConfluentINc

16 Workloads Deployment @gamussa | #ImCloudNative | @ConfluentINc
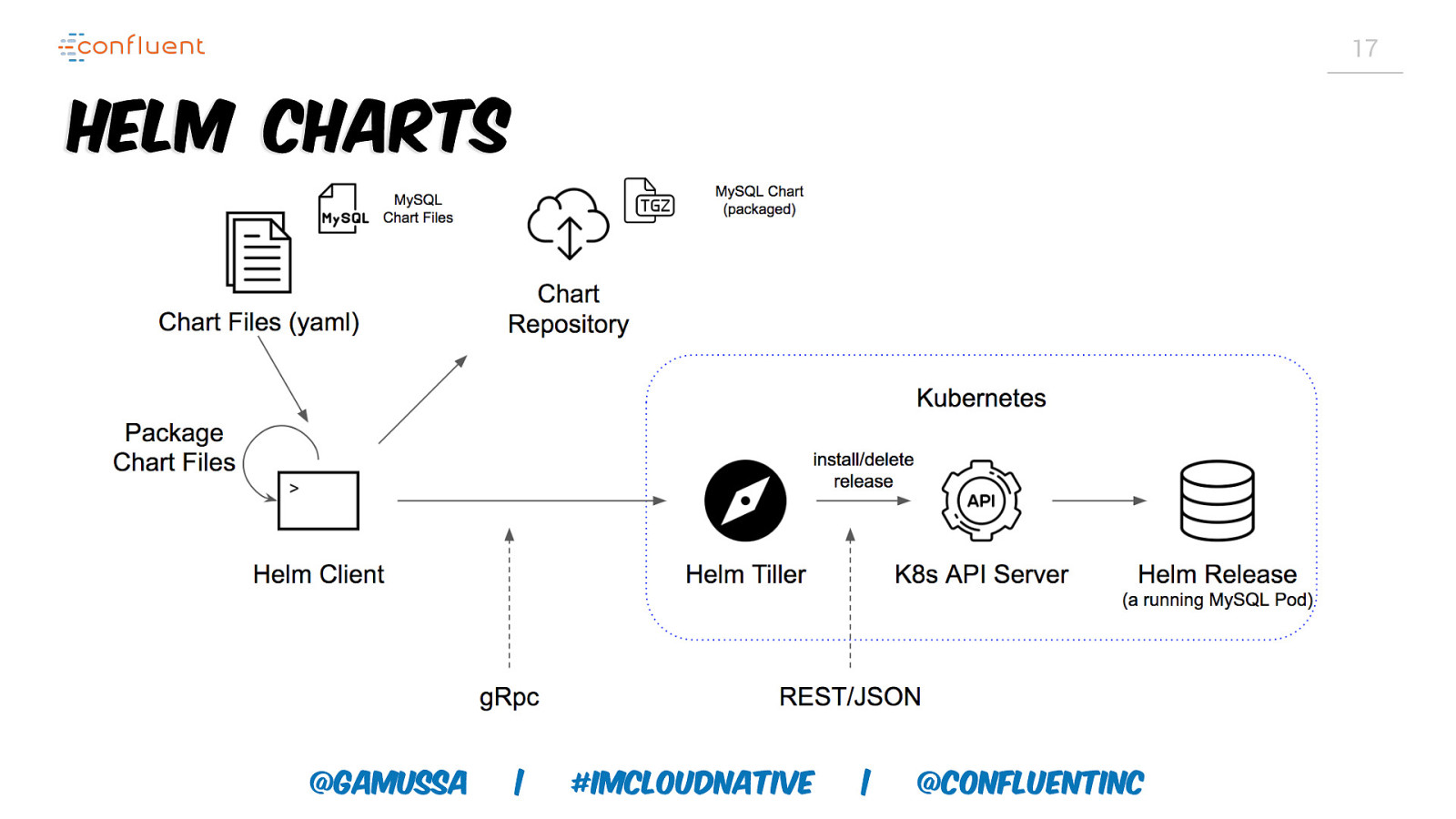
17 Helm Charts @gamussa | #ImCloudNative | @ConfluentINc
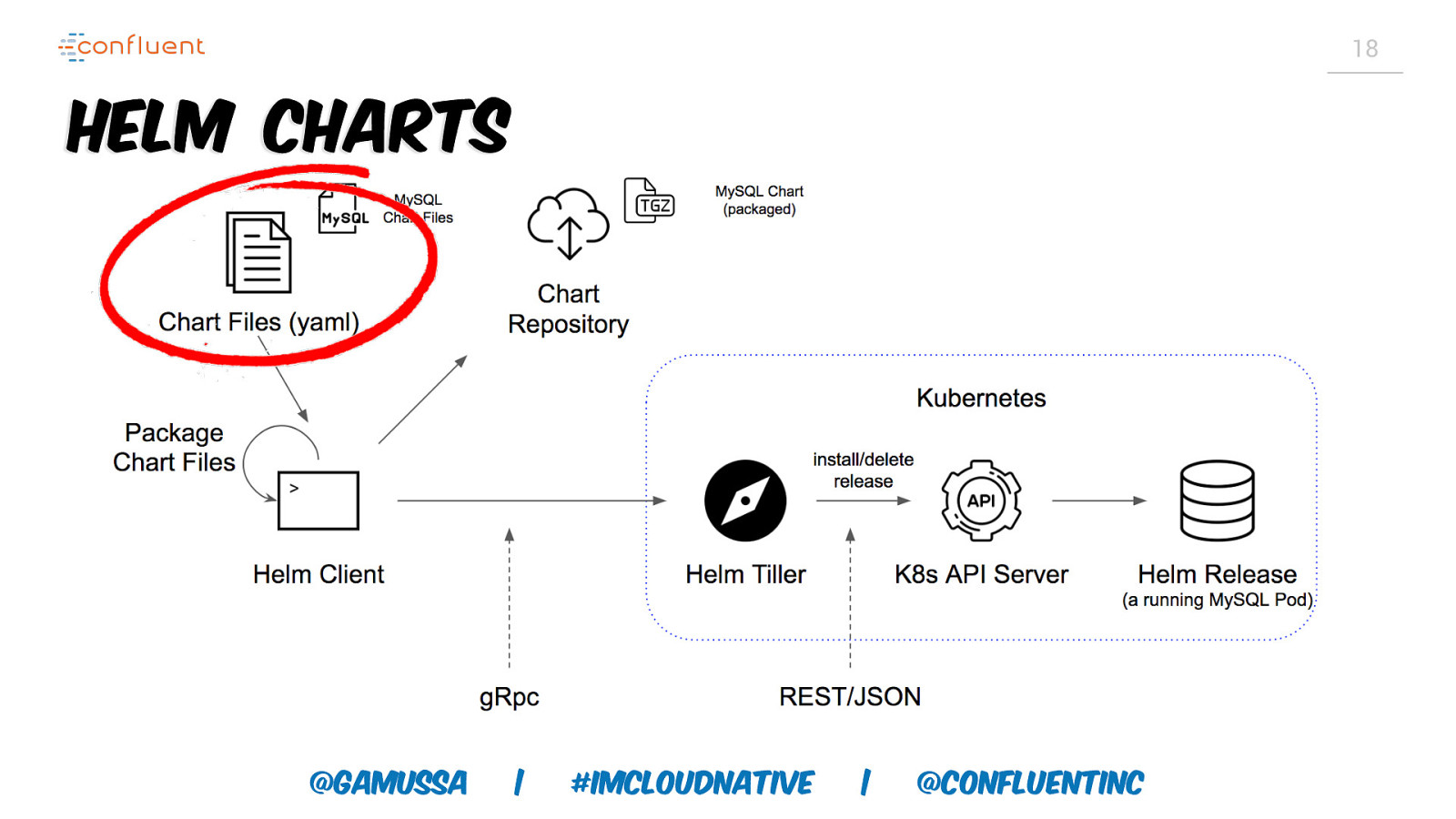
18 Helm Charts @gamussa | #ImCloudNative | @ConfluentINc
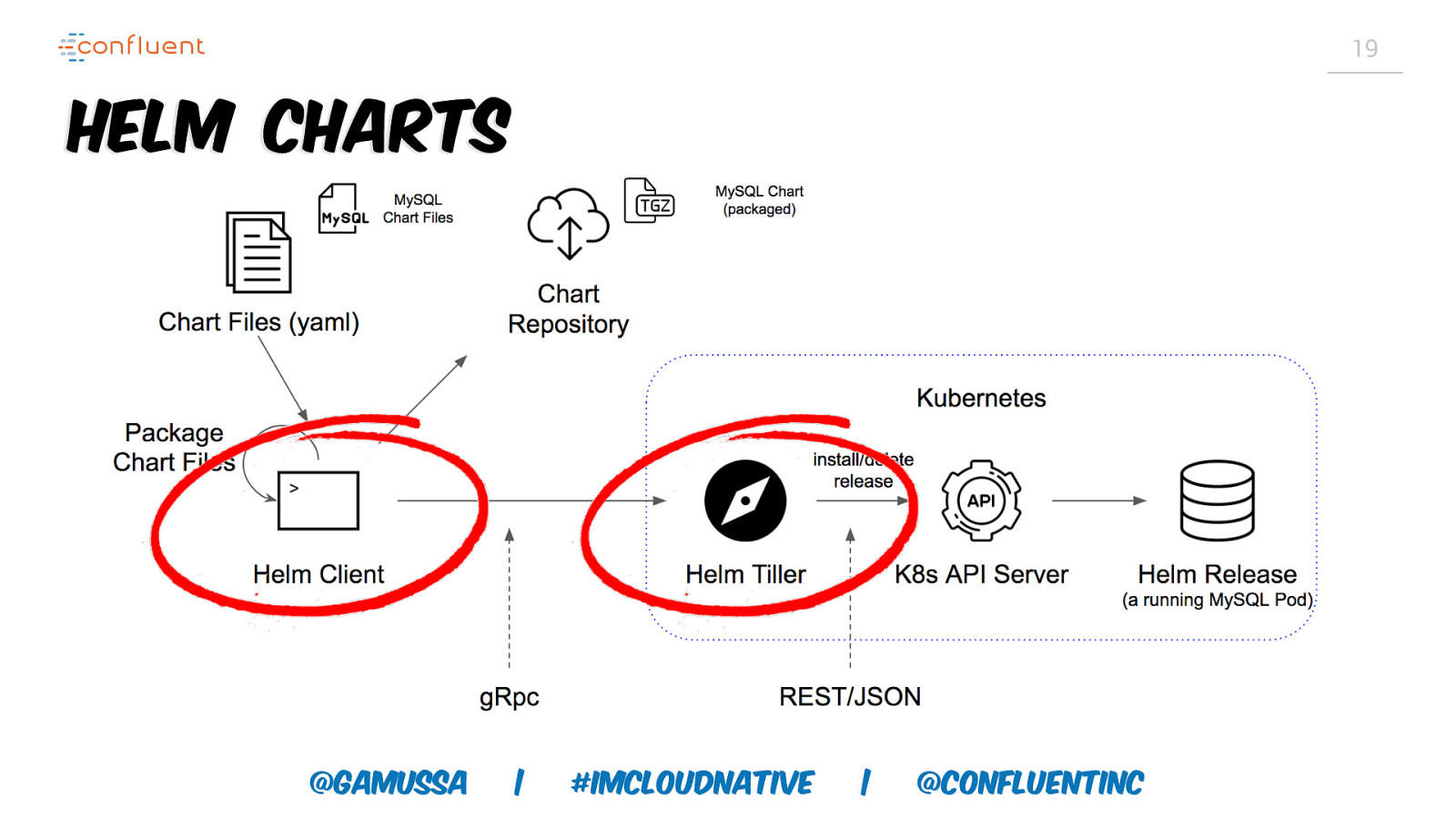
19 Helm Charts @gamussa | #ImCloudNative | @ConfluentINc

20 https://cnfl.io/helm_video @gamussa | #ImCloudNative | @ConfluentINc

21 Helm Charts is just a GO Templates. How Charts help with rolling update? @gamussa | #ImCloudNative | @ConfluentINc

Rolling Upgrade Kafka Broker Upgrades: 1. Stop the broker, upgrade Kafka 2. Wait for Partition Leader reassignment 3. Start the upgraded broker 4. Wait for zero underreplicated partitions 5. Upgrade the next broker @gamussa | #ImCloudNative | @ConfluentINc 22

23 We will use StatefulSets with OrderedReady @gamussa | #ImCloudNative | @ConfluentINc

24 We need SRE / Operator knowledge to manage the platform. You need Operator! @gamussa | #ImCloudNative | @ConfluentINc

25 @gamussa | #ImCloudNative | @ConfluentINc

26 Show me your Operator @gamussa | #ImCloudNative | @ConfluentINc
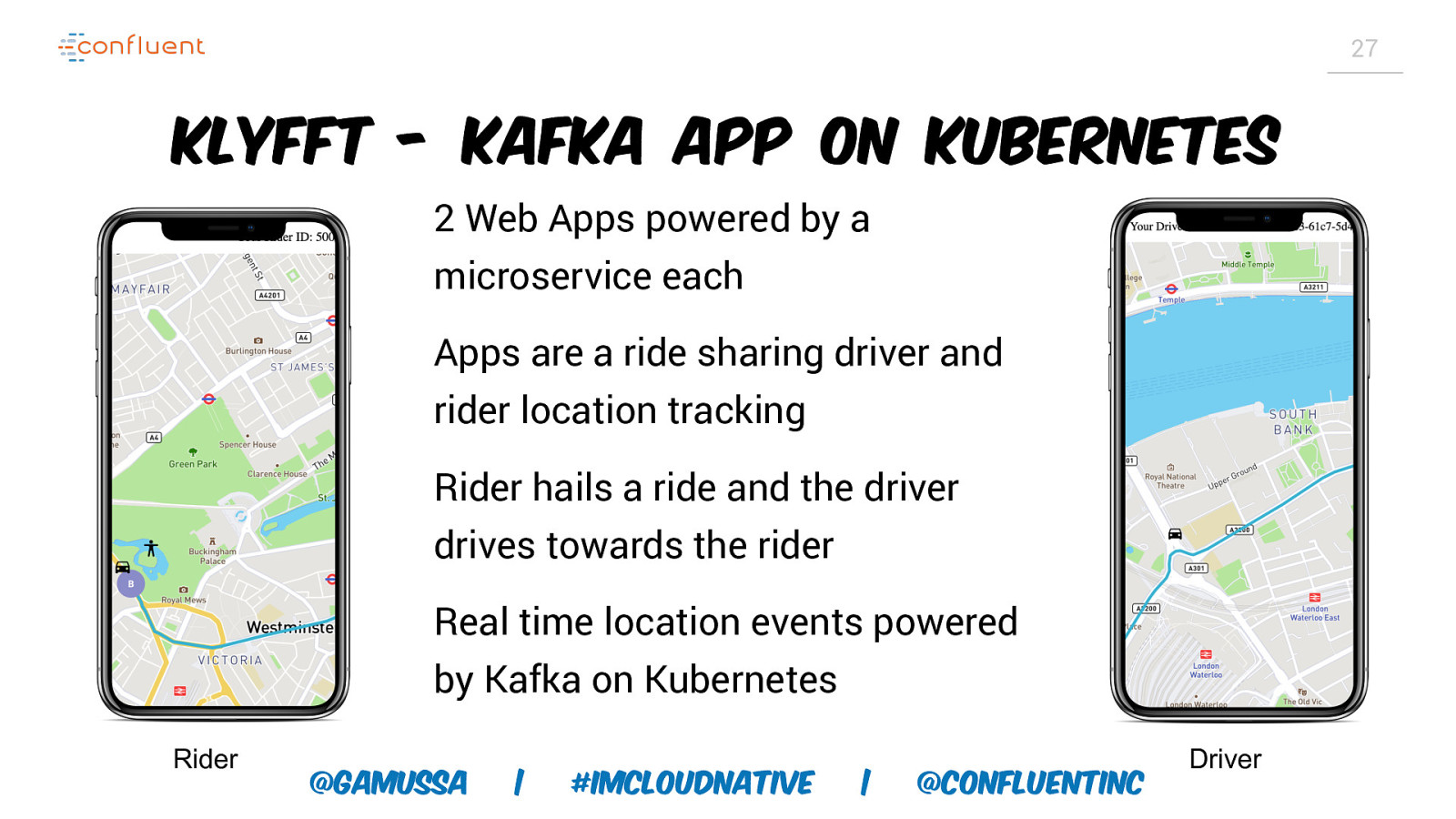
27 KLyfft - Kafka app on Kubernetes 2 Web Apps powered by a microservice each Apps are a ride sharing driver and rider location tracking Rider hails a ride and the driver drives towards the rider Real time location events powered by Kafka on Kubernetes Rider @gamussa | #ImCloudNative | @ConfluentINc Driver

28 Demo @gamussa | #ImCloudNative | @ConfluentINc

29 DO KAFKA ON KUBERNETES DEMO AND EVERYONE LOOSES THEIR MIND @gamussa | #ImCloudNative | @ConfluentINc

30 Confluent Operator - Automated Security Configuration SASL PLAIN and Mutual TLS Authentication Automate configuration of truststores and keystores with secret objects Automate configuration of Kafka and all Confluent Platform Components @gamussa | #ImCloudNative | @ConfluentINc

31 Be like Justin! @gamussa | #ImCloudNative | @ConfluentINc

Rolling Upgrade Kafka Broker Upgrades: 1. Stop the broker, upgrade Kafka 2. Wait for Partition Leader reassignment 3. Start the upgraded broker 4. Wait for zero underreplicated partitions 5. Upgrade the next broker @gamussa | #ImCloudNative | @ConfluentINc 32
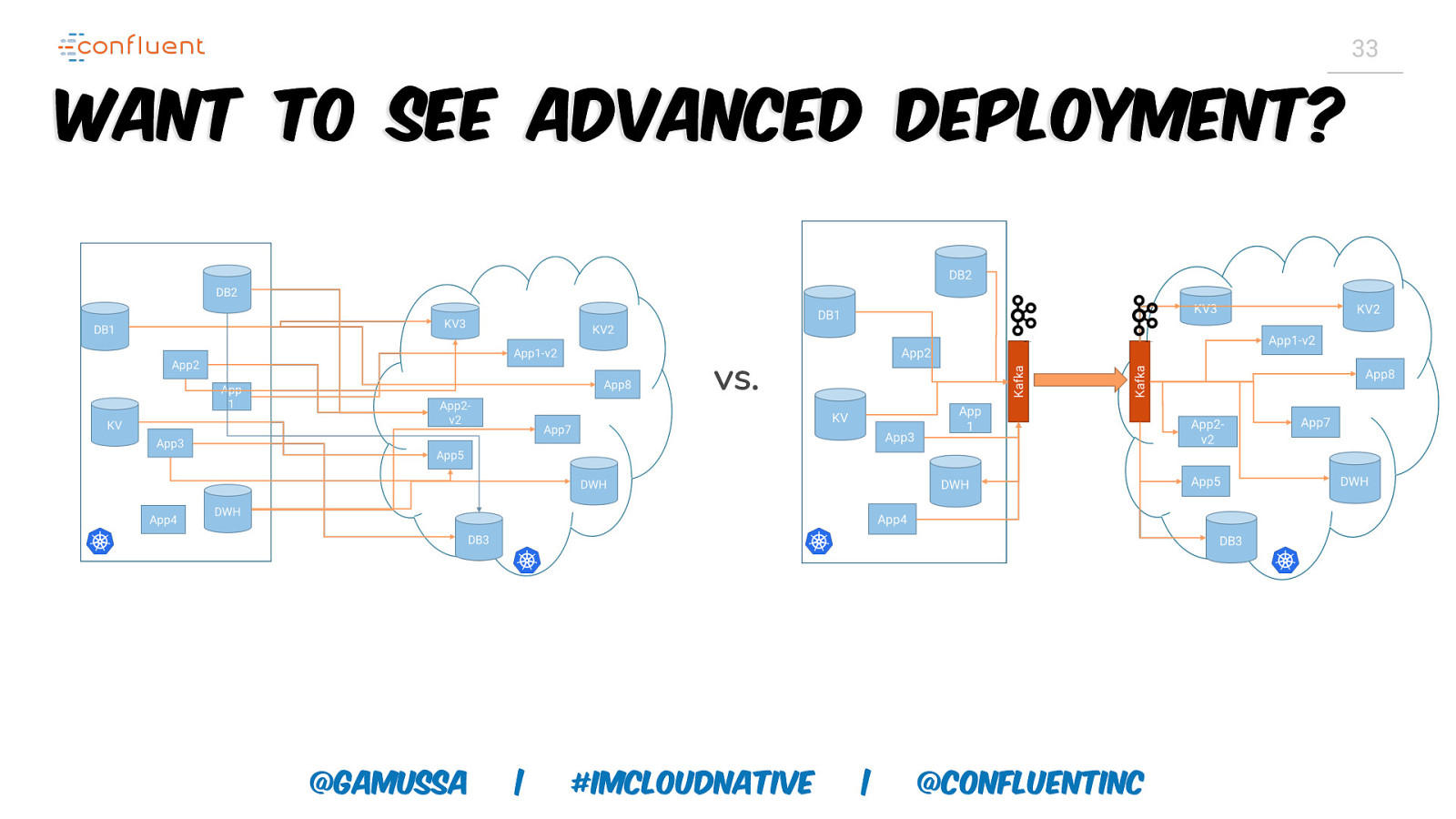
33 Want to see advanced deployment? vs. @gamussa | #ImCloudNative | @ConfluentINc

34 http://gamov.dev/ksummit_nyc19_k8s @gamussa | #ImCloudNative | @ConfluentINc

35 ● We are in private Preview GA Plans Release is over! ● 24 customers testing the Operator in Preview: ● Global customers ● Banks, Fin Tech, Retailers, Consumer Tech ● We are in the final stages of Preview and about to launch soon @gamussa | #ImCloudNative | @ConfluentINc

Thanks! @gamussa viktor@confluent.io https://slackpass.io/confluentcommunity #kubernetes @gamussa | @ #ImCloudNative | @ConfluentINc

37

When it comes to choosing a distributed streaming platform for real-time data pipelines, everyone knows the answer: Apache Kafka! And when it comes to deploying applications at scale without needing to integrate different pieces of infrastructure yourself, the answer nowadays is increasingly Kubernetes. However, with all great things, the devil is truly in the details. While Kubernetes does provide all the building blocks that are needed, a lot of thought is required to truly create an enterprise-grade Kafka platform that can be used in production. In this technical deep dive, Michael and Viktor will go through challenges and pitfalls of managing Kafka on Kubernetes as well as the goals and lessons learned from the development of the Confluent Operator for Kubernetes.
Video
Resources
The following resources were mentioned during the presentation or are useful additional information.
Buzz and feedback
Here’s what was said about this presentation on social media.