Apache Kafka — A Streaming Data Platform
A presentation at San Francisco JUG in in San Francisco, CA, USA by Viktor Gamov

@ Apache Kafka A Streaming Data Platform and #javapuzzlersng @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc Who am I?

@ @gamussa @sfjava @confluentinc Solutions Architect Who am I?

@ @gamussa @sfjava @confluentinc Solutions Architect Developer Advocate Who am I?

@ @gamussa @sfjava @confluentinc Solutions Architect Developer Advocate @gamussa in internetz Who am I?

@
@gamussa @sfjava @confluentinc
Solutions Architect
Developer Advocate
@gamussa
in internetz
Hey you, yes, you,
go follow me in twitter ©
Who am I?

@ @gamussa @sfjava @confluentinc Kafka & Confluent

@ @gamussa @sfjava @confluentinc We are hiring! https://www.confluent.io/careers/

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc A company is build on

@ @gamussa @sfjava @confluentinc A company is build on DATA FLOWS but All we have is DATA STORES
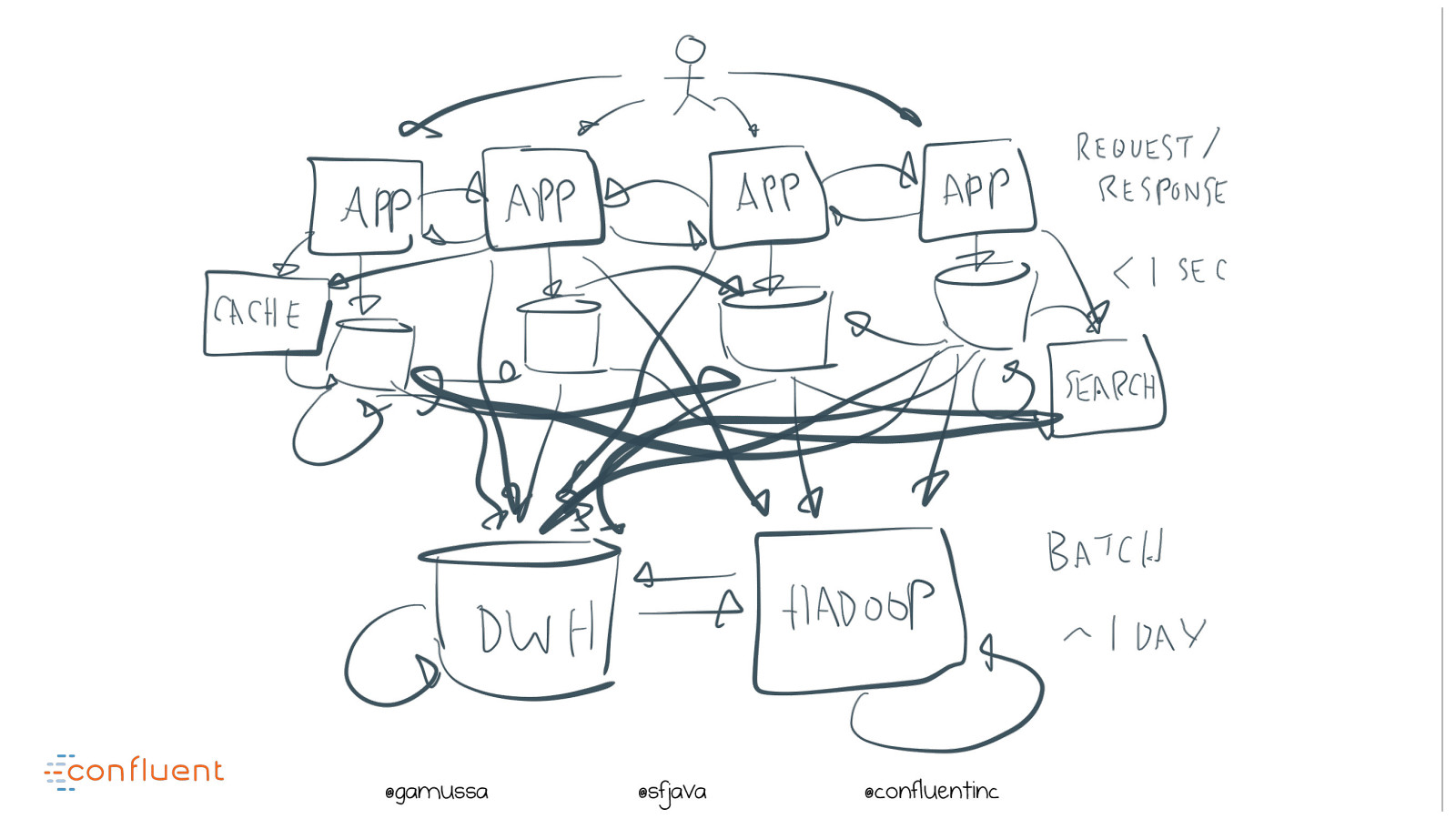
@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc
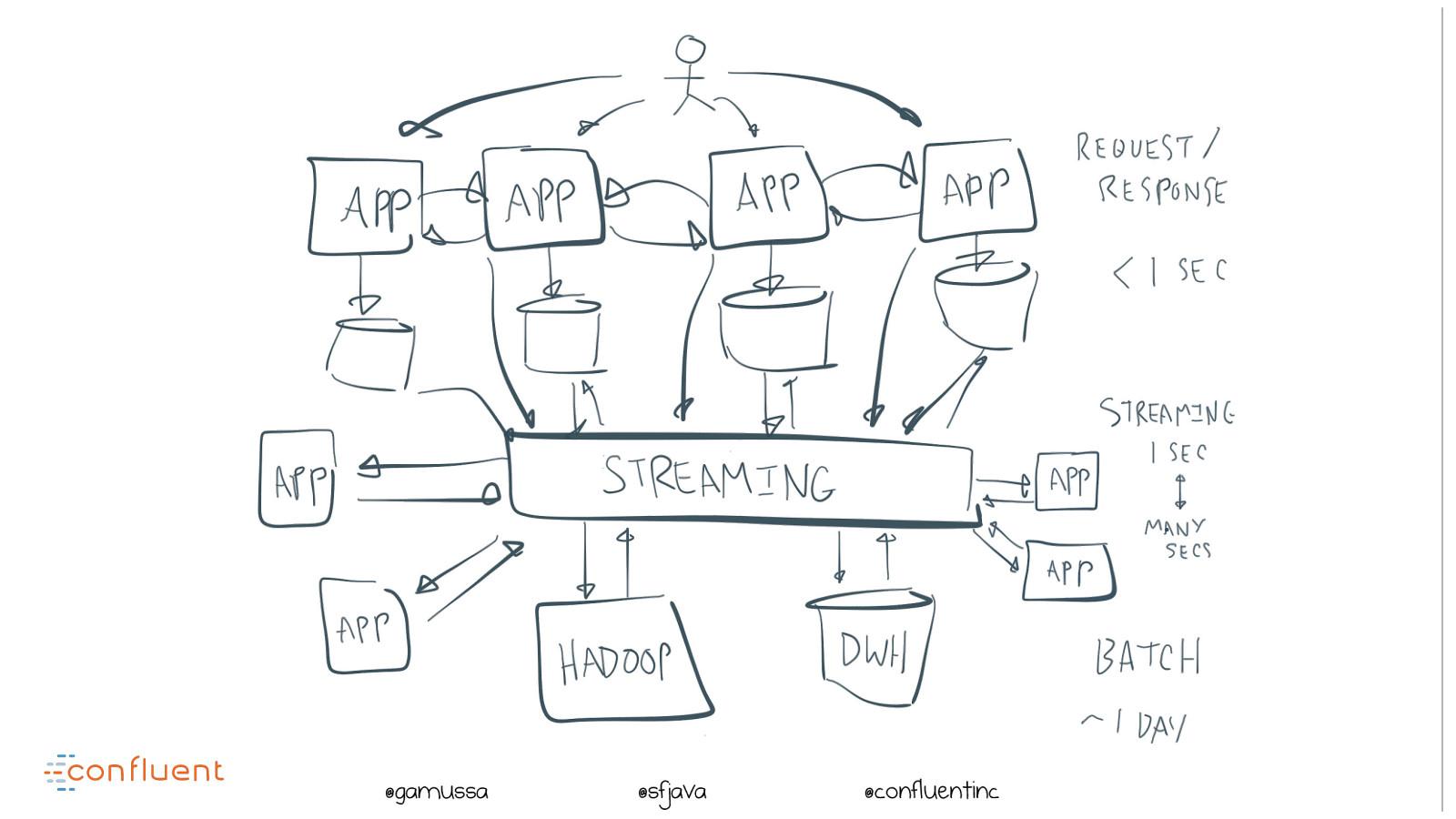
@ @gamussa @sfjava @confluentinc
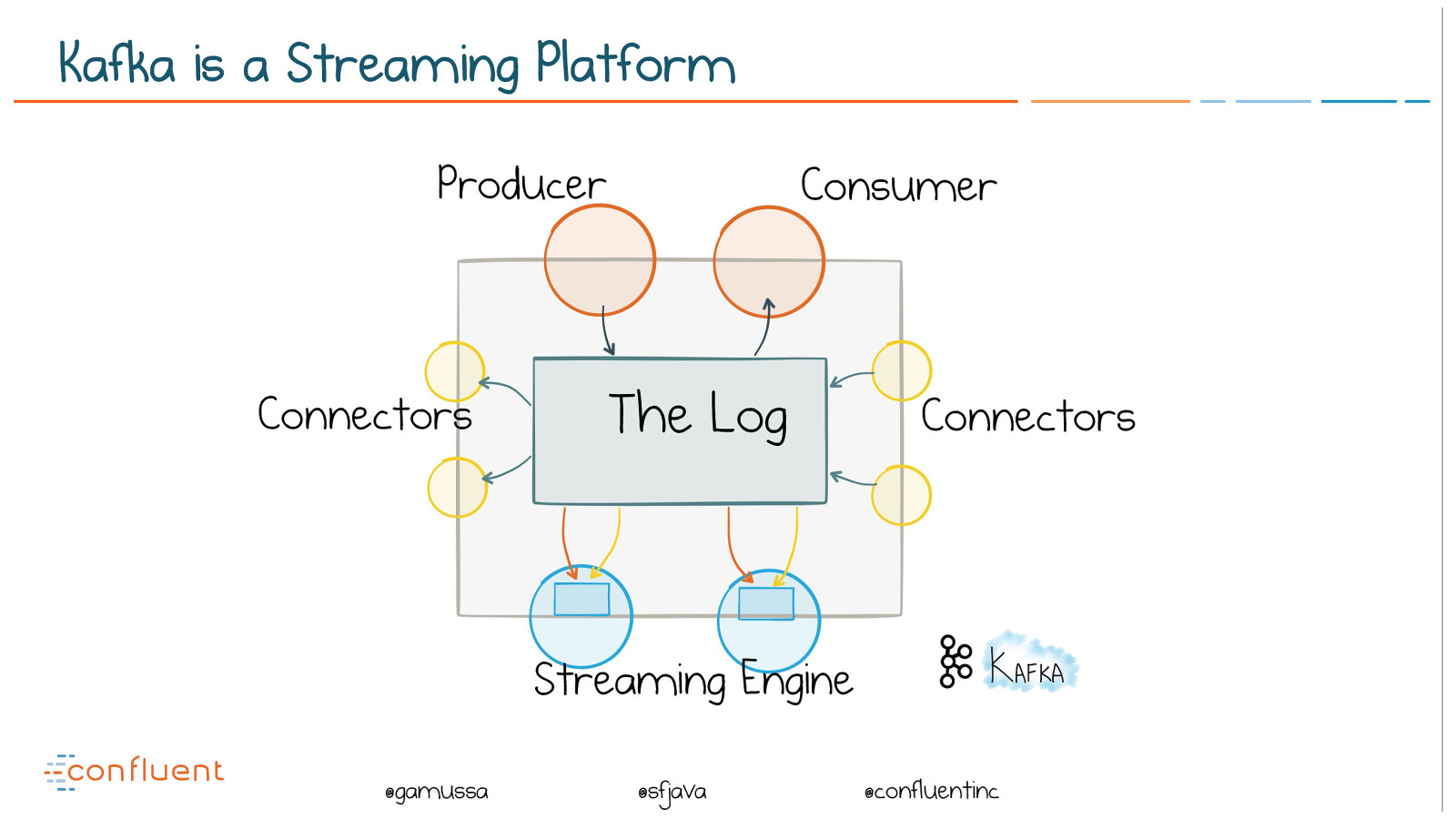
@ @gamussa @sfjava @confluentinc Kafka is a Streaming Platform The Log Connectors Connectors Producer Consumer Streaming Engine
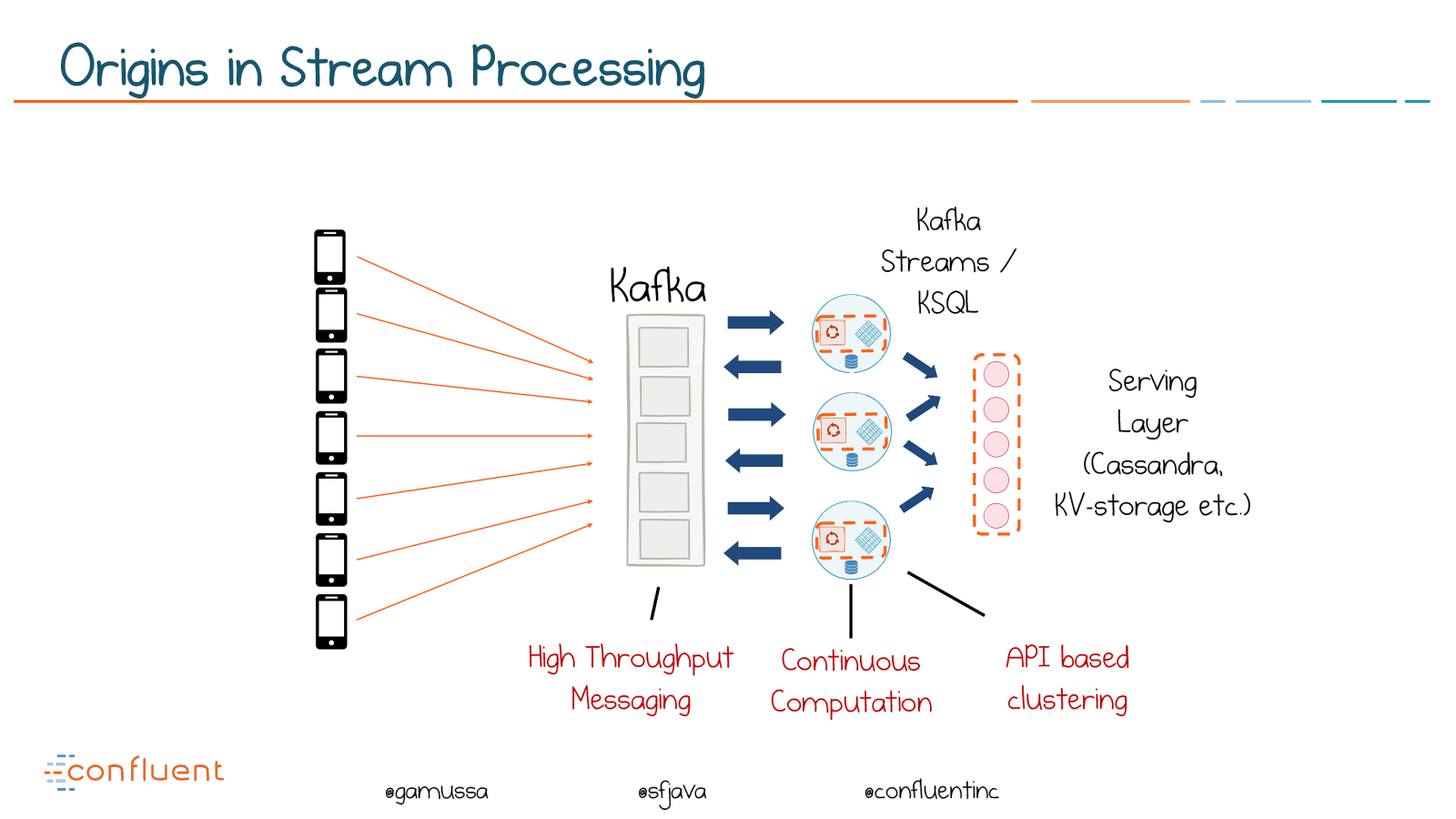
@
@gamussa @sfjava @confluentinc
Kafka
Serving
Layer
(Cassandra,
KV-storage etc.)
Kafka
Streams /
KSQL
Continuous
Computation
High Throughput
Messaging
API based
clustering
Origins in Stream Processing
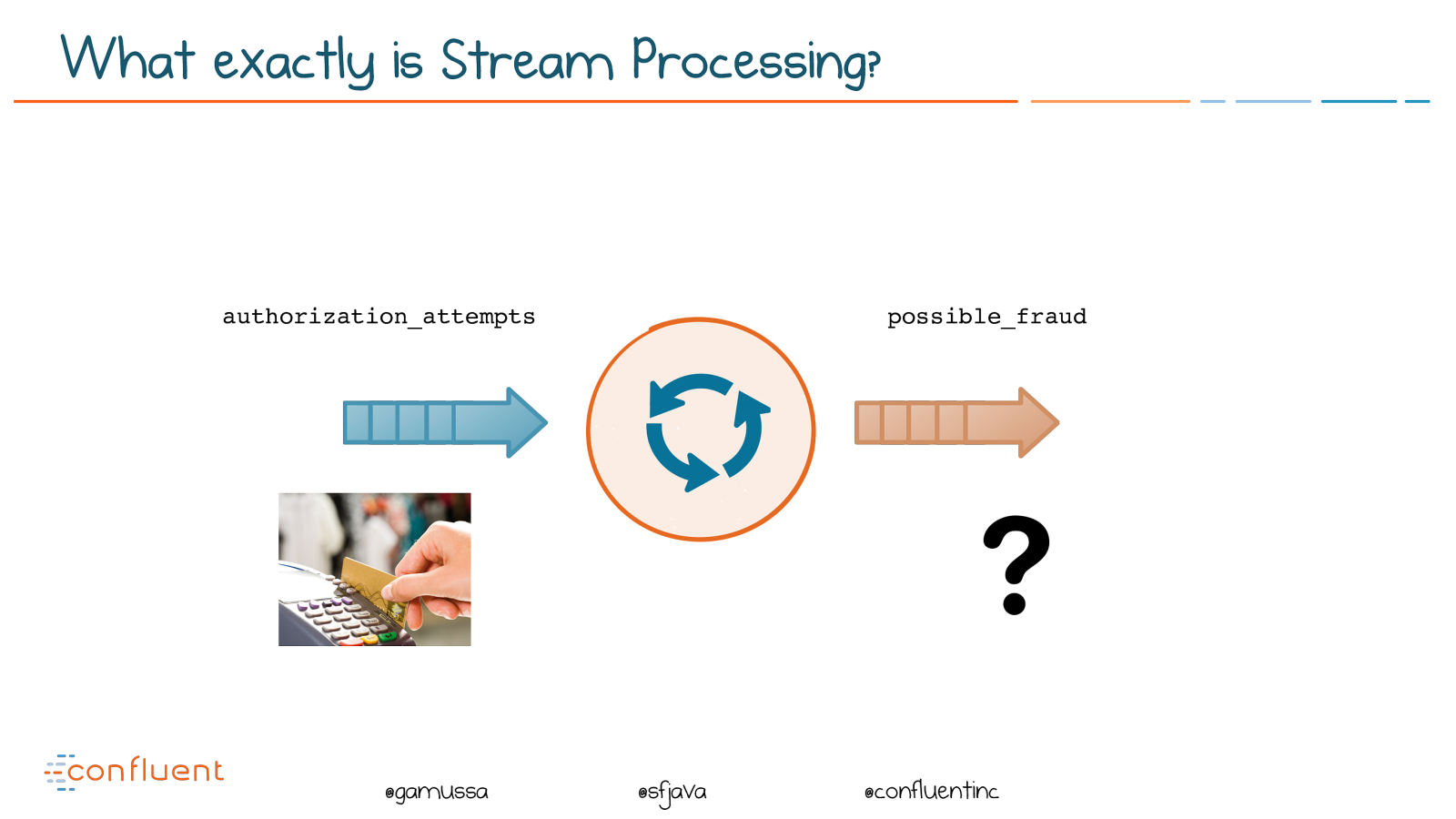
@ @gamussa @sfjava @confluentinc authorization_attempts possible_fraud What exactly is Stream Processing?

@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?

@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?

@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?

@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?
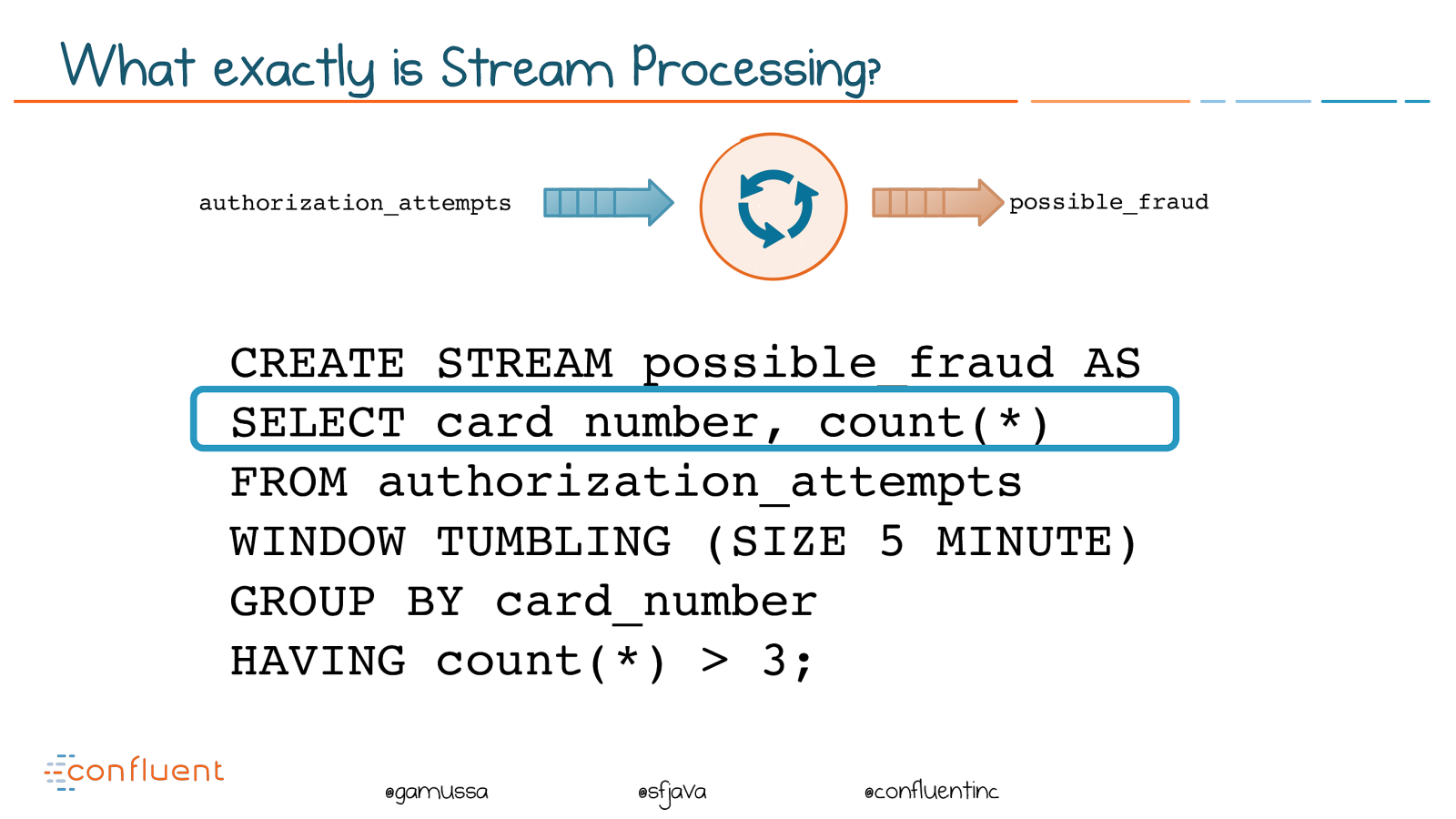
@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?
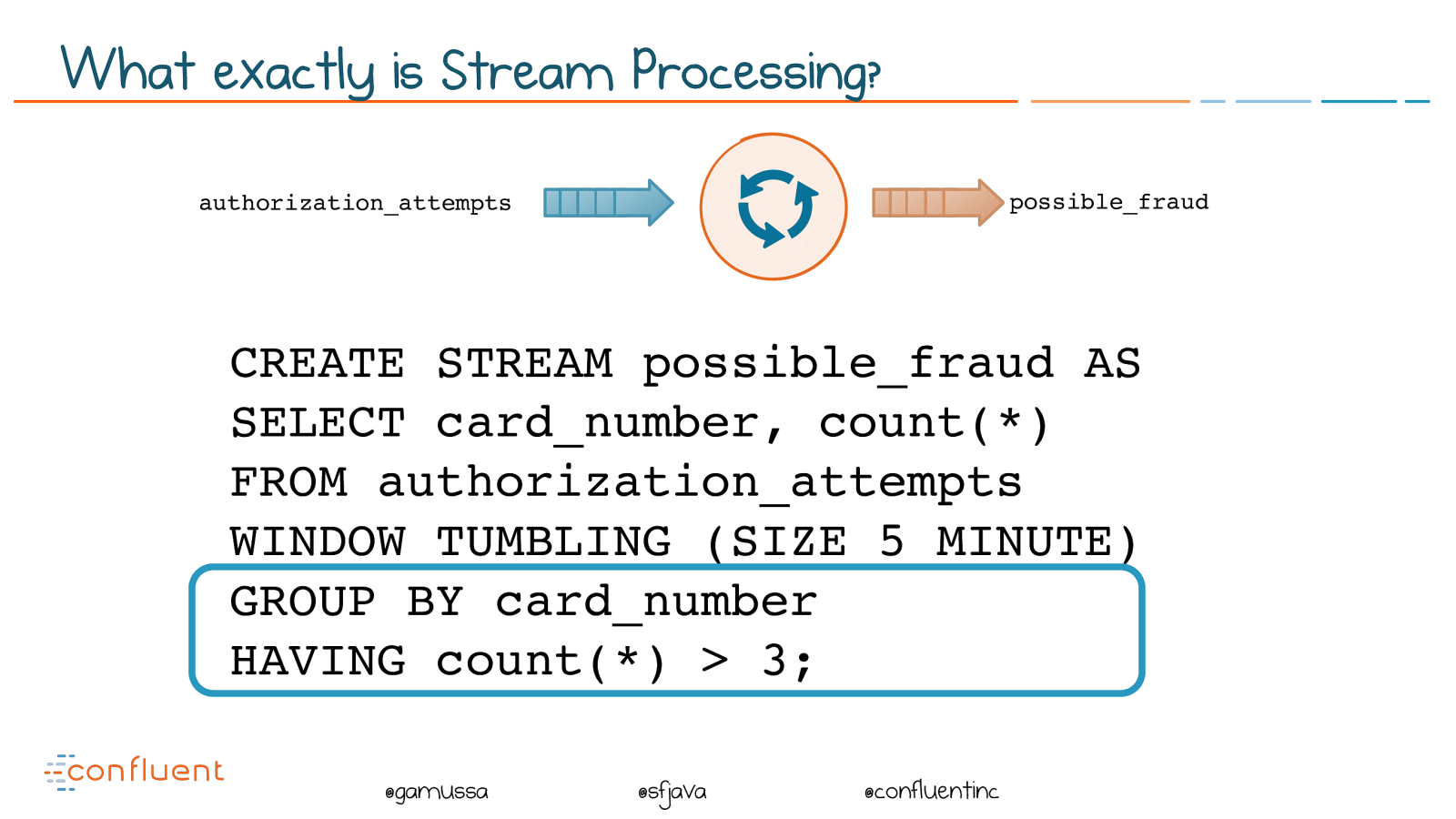
@ @gamussa @sfjava @confluentinc CREATE STREAM possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 MINUTE) GROUP BY card_number HAVING count() > 3; authorization_attempts possible_fraud What exactly is Stream Processing?

@ @gamussa @sfjava @confluentinc Streaming is the toolset for dealing with events as they move!
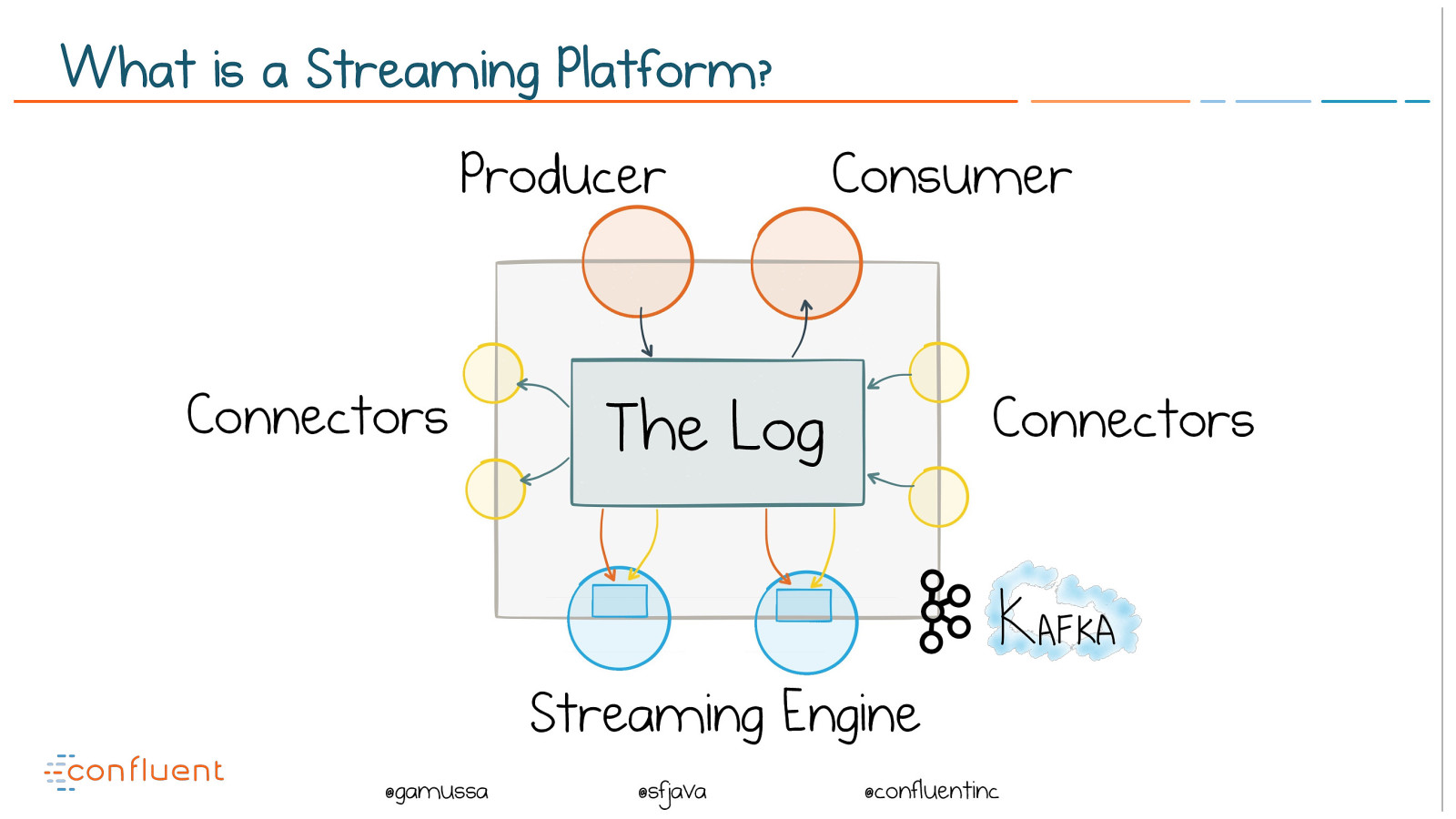
@ @gamussa @sfjava @confluentinc What is a Streaming Platform? The Log Connectors Connectors Producer Consumer Streaming Engine
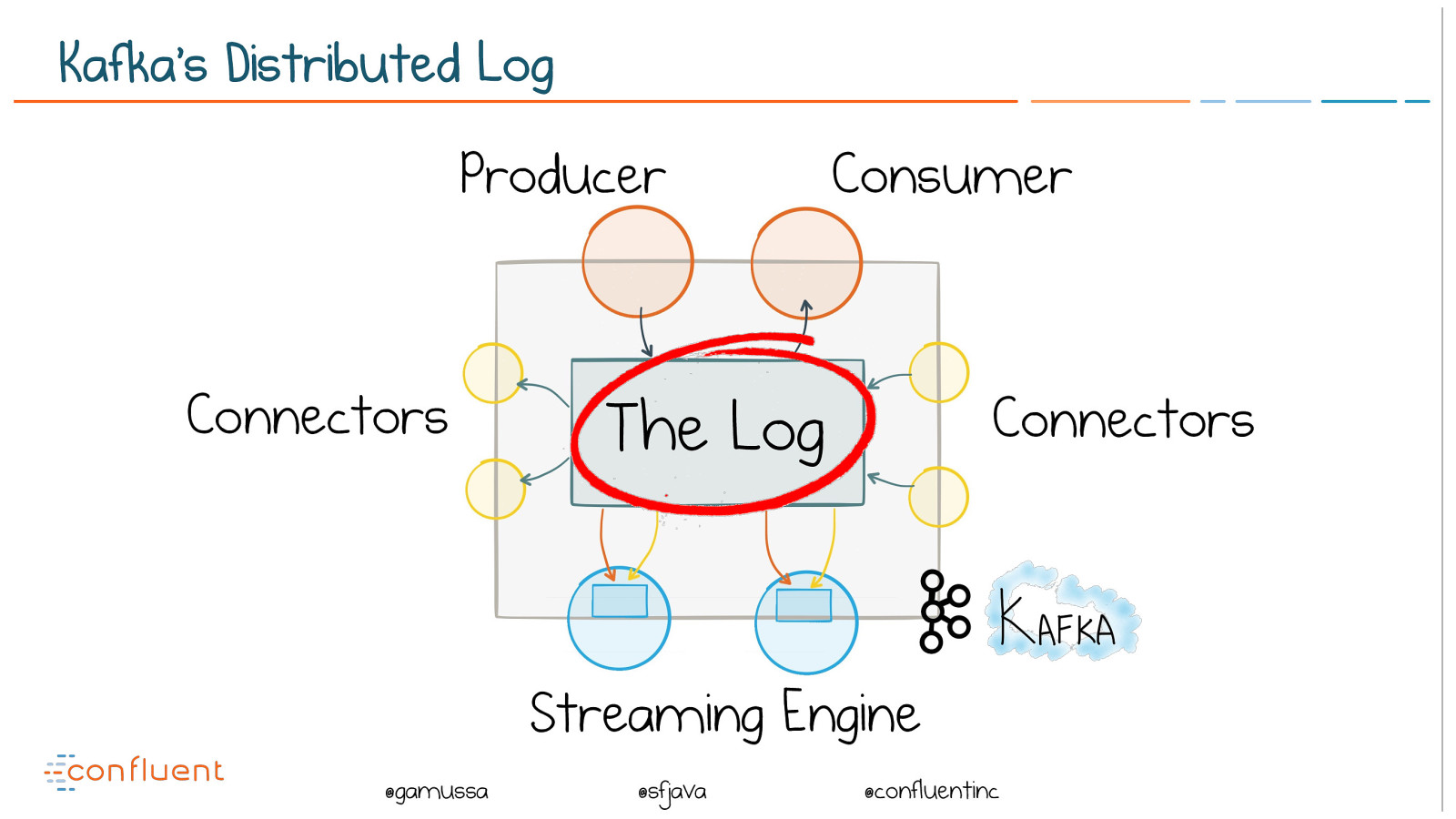
@ @gamussa @sfjava @confluentinc Kafka’s Distributed Log The Log Connectors Connectors Producer Consumer Streaming Engine

@ @gamussa @sfjava @confluentinc The log is a type of durable messaging system

@ @gamussa @sfjava @confluentinc Similar to a traditional messaging system (ActiveMQ, Rabbit etc) but with: (a) Far better scalability (b) Built in fault tolerance / HA (c) Storage The log is a type of durable messaging system

@
@gamussa @sfjava @confluentinc
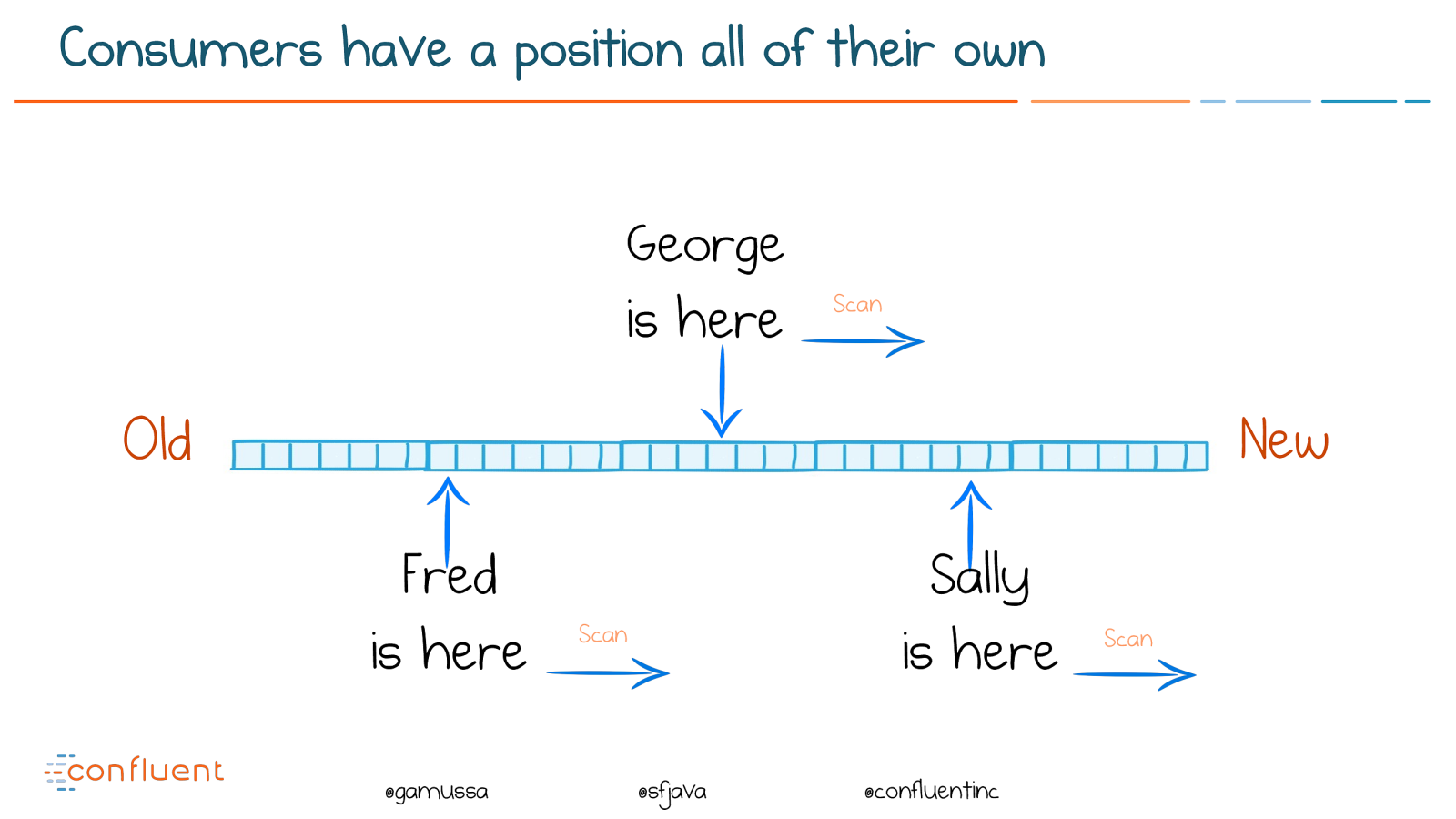
The log is a simple idea
Messages are added
at the end of the log
Old
New
@ @gamussa @sfjava @confluentinc Consumers have a position all of their own Sally is here George is here Fred is here Old New Scan Scan Scan

@ @gamussa @sfjava @confluentinc Only Sequential Access Old New Read to offset & scan
@ @gamussa @sfjava @confluentinc Scaling Out
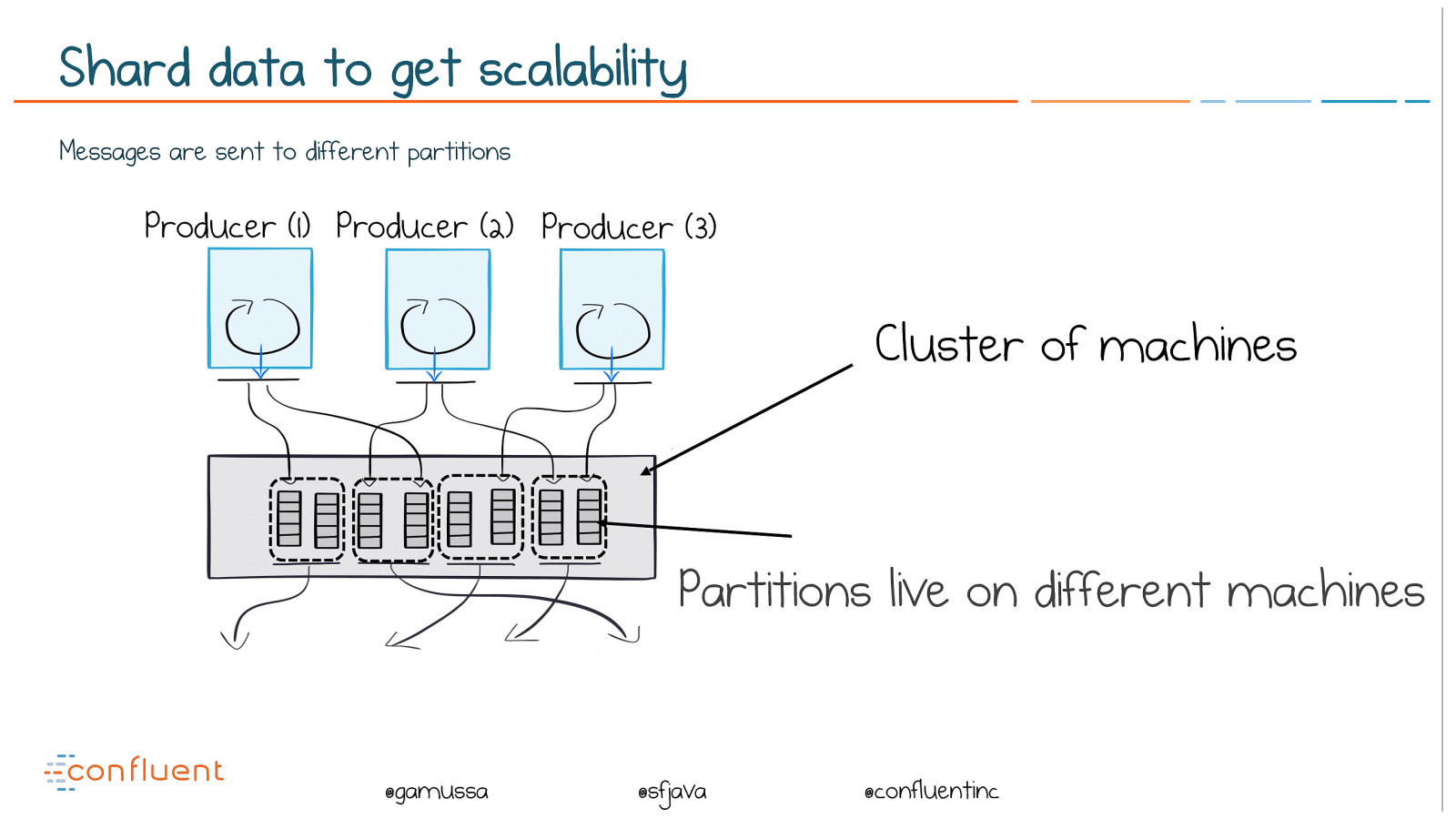
@ @gamussa @sfjava @confluentinc Shard data to get scalability Messages are sent to different partitions Producer (1) Producer (2) Producer (3) Cluster of machines Partitions live on different machines

@ @gamussa @sfjava @confluentinc Replicate to get fault tolerance replicate msg msg leader Machine A Machine B
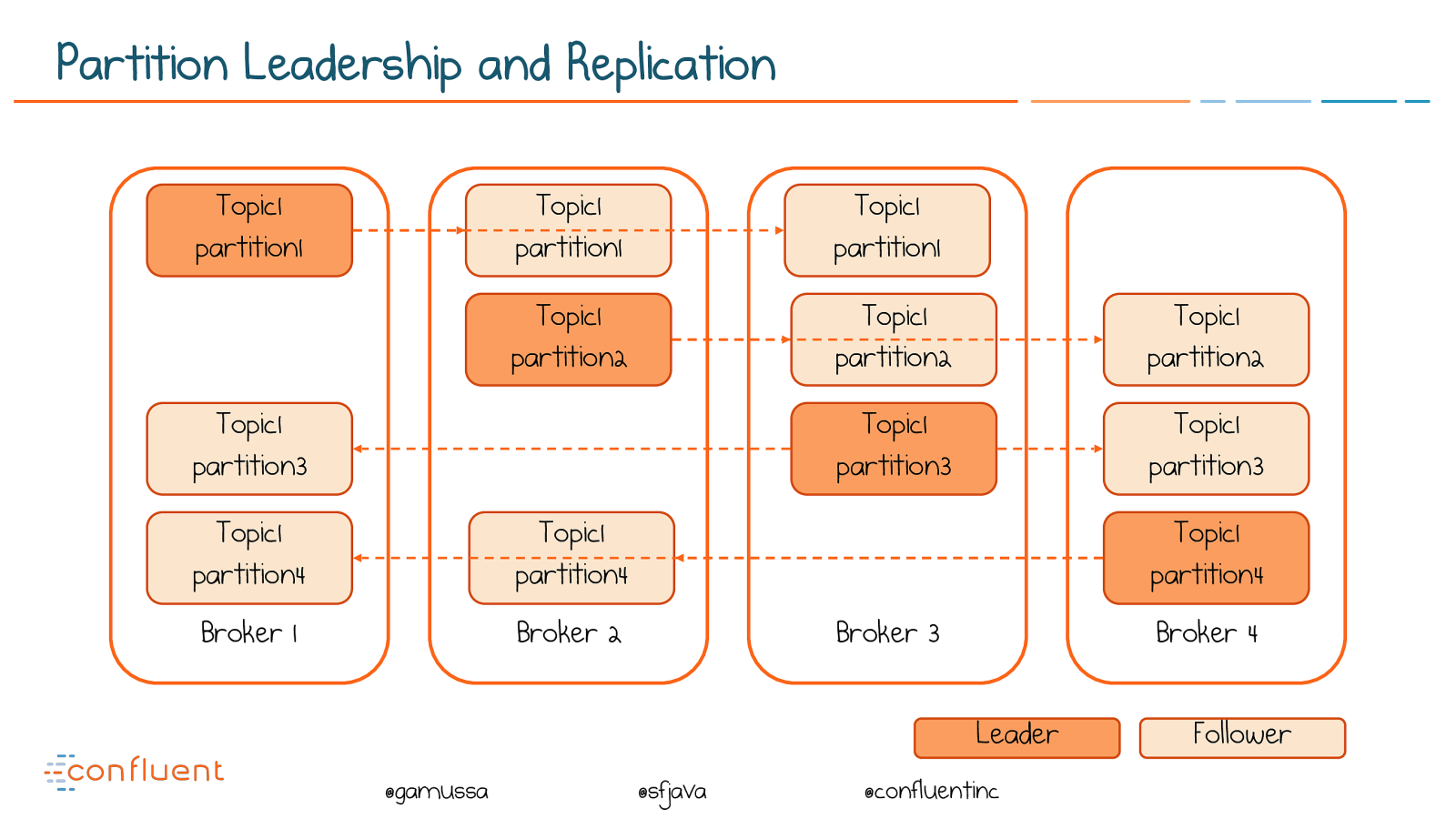
@ @gamussa @sfjava @confluentinc Partition Leadership and Replication Broker 1 Topic1 partition1 Broker 2 Broker 3 Broker 4 Topic1 partition1 Topic1 partition1 Leader Follower Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition4 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4

@ @gamussa @sfjava @confluentinc Replication provides resiliency A ‘replica’ takes over on machine failure
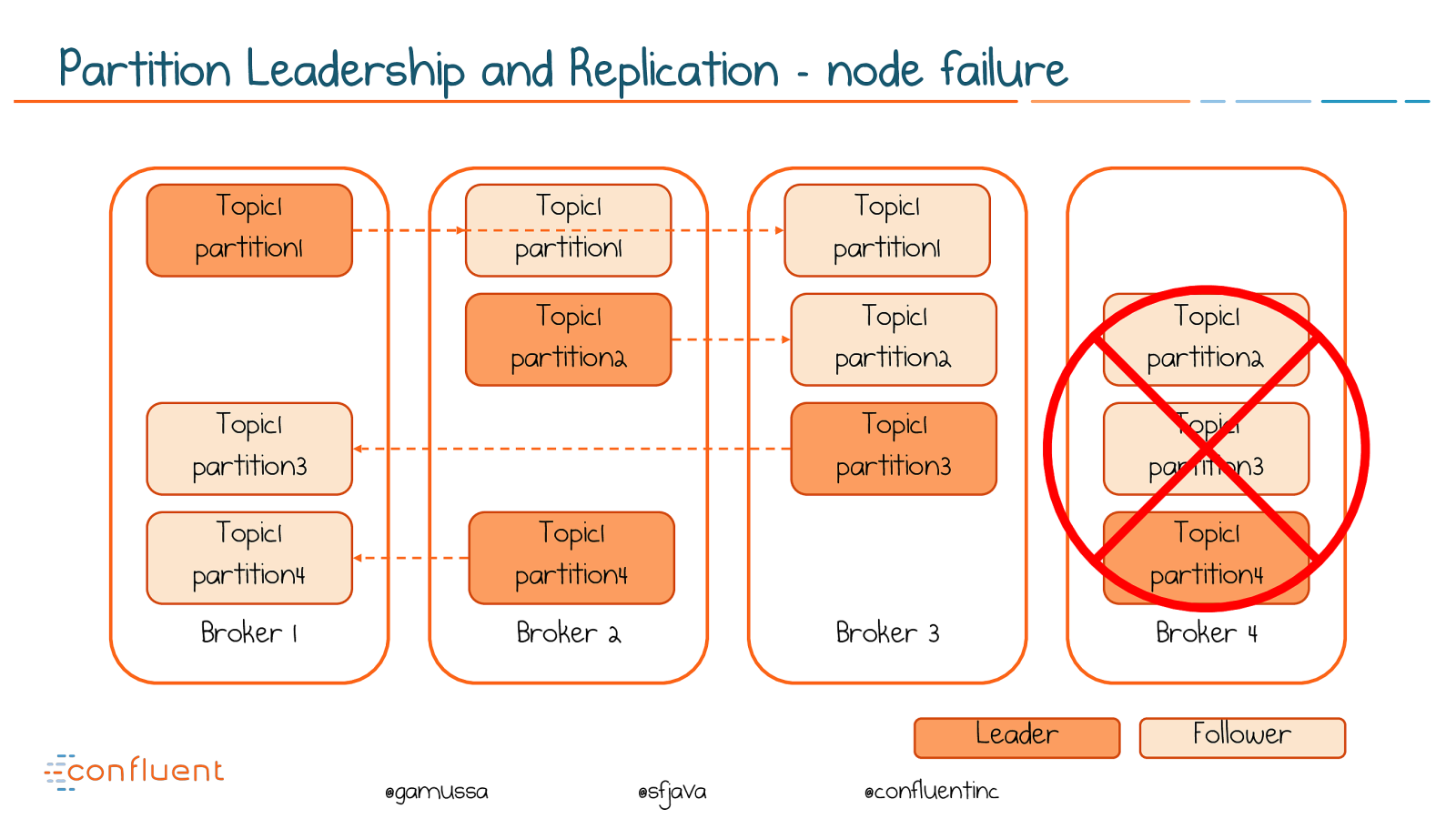
@ @gamussa @sfjava @confluentinc Partition Leadership and Replication - node failure Broker 1 Topic1 partition1 Broker 2 Broker 3 Broker 4 Topic1 partition1 Topic1 partition1 Leader Follower Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition4 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4
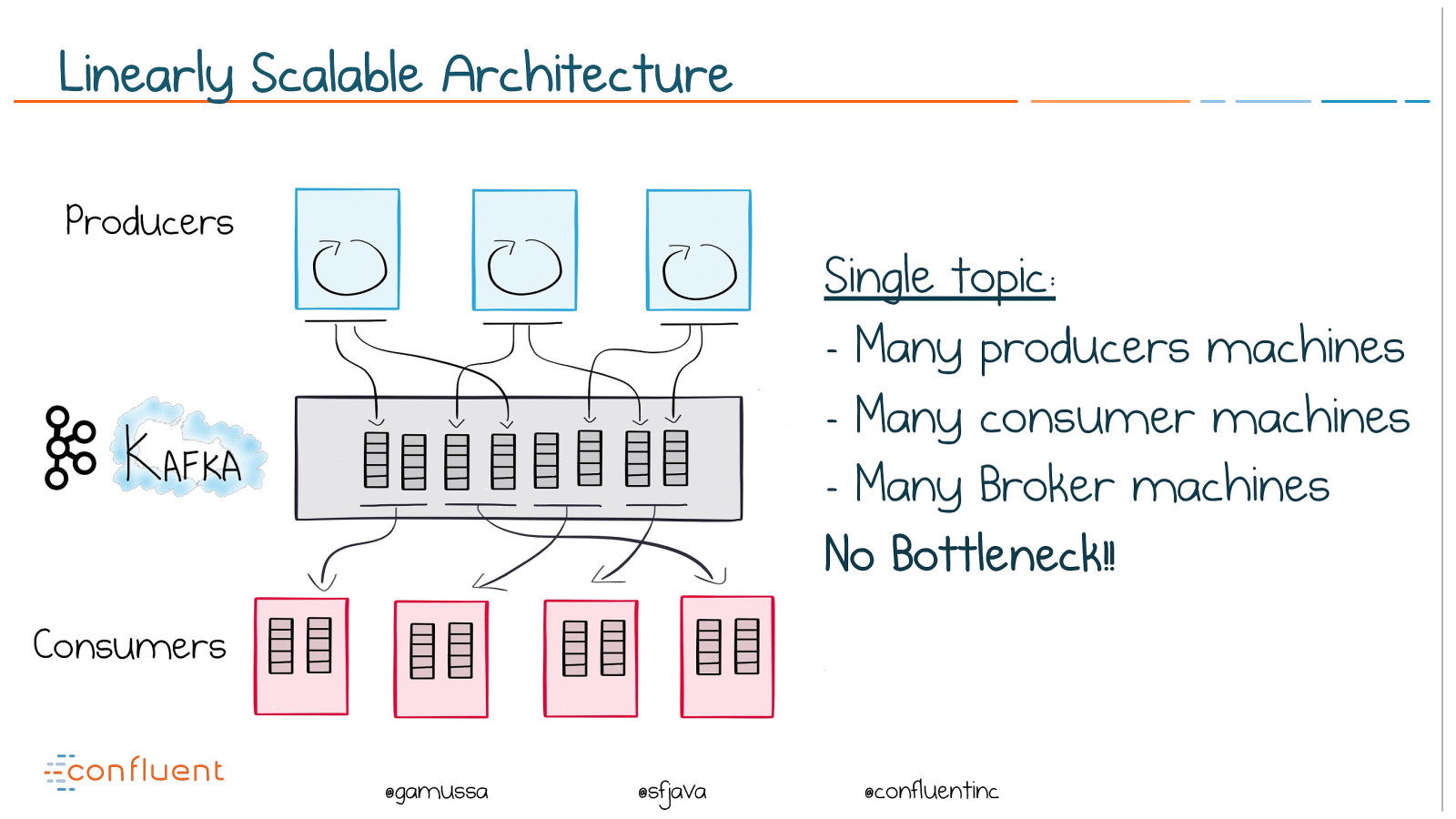
@ @gamussa @sfjava @confluentinc Linearly Scalable Architecture Single topic:
- Many producers machines
- Many consumer machines
- Many Broker machines No Bottleneck!! Consumers Producers
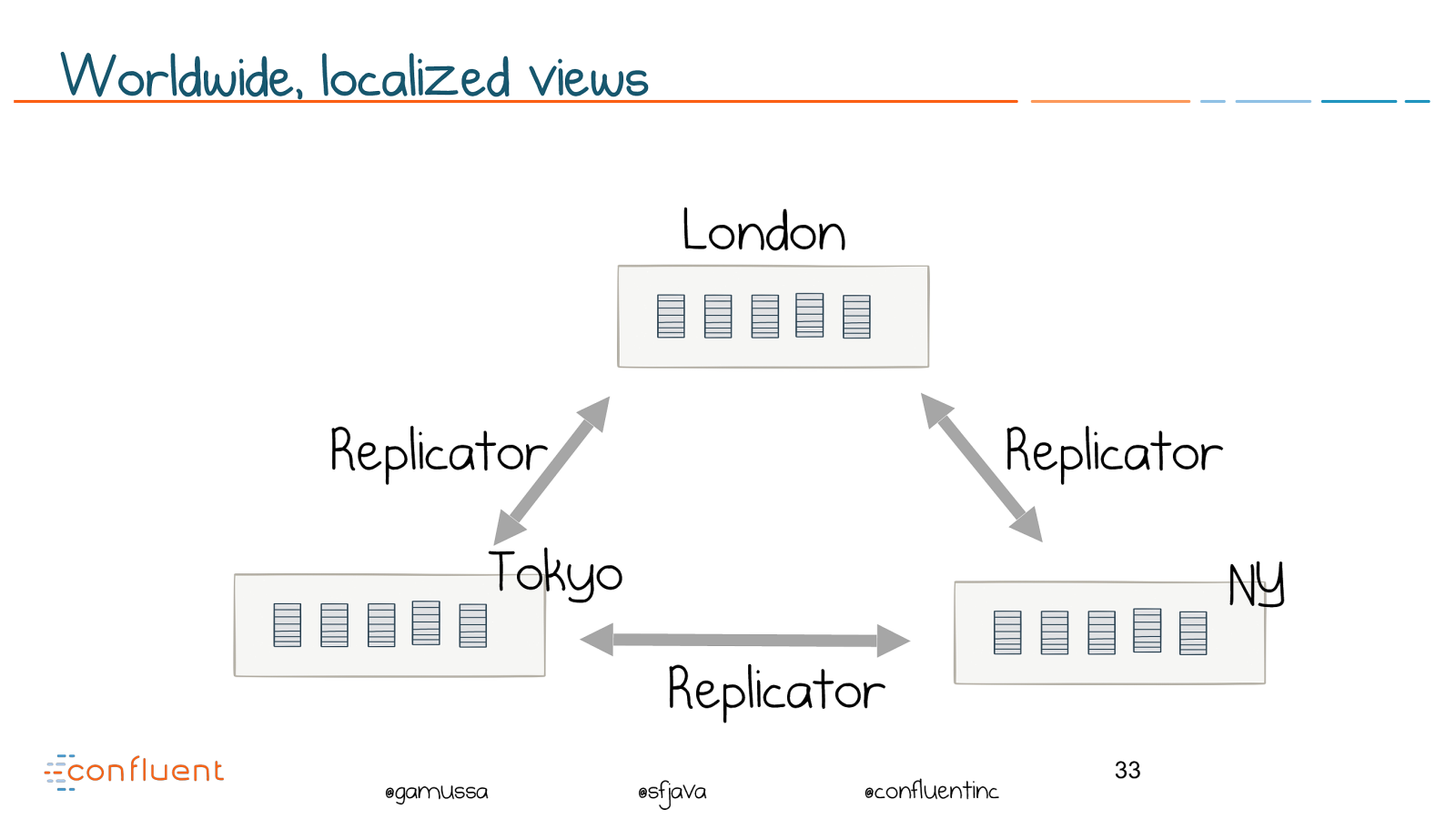
@ @gamussa @sfjava @confluentinc Worldwide, localized views ! 33 NY London Tokyo Replicator Replicator Replicator
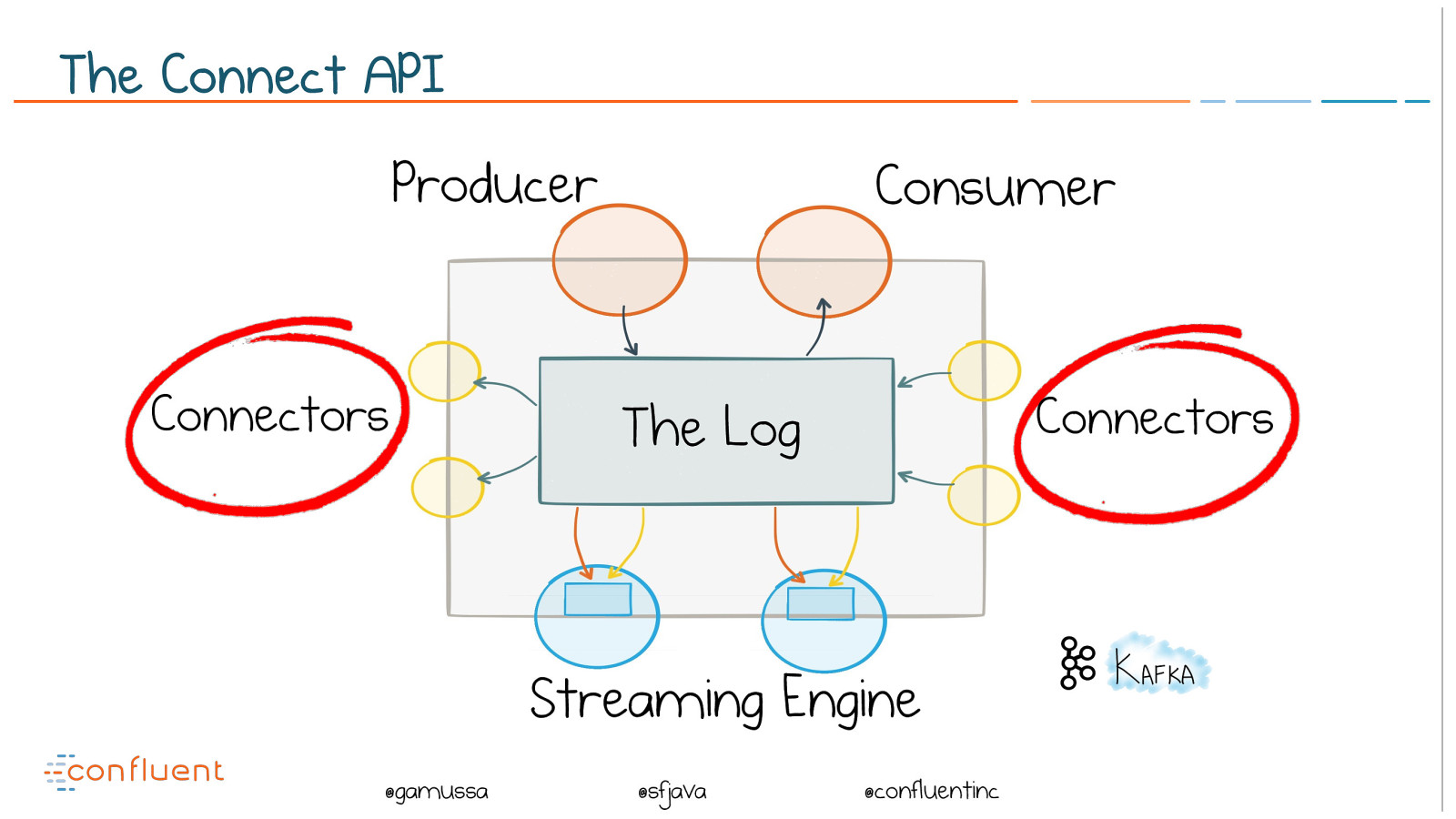
@ @gamussa @sfjava @confluentinc The Connect API The Log Connectors Connectors Producer Consumer Streaming Engine
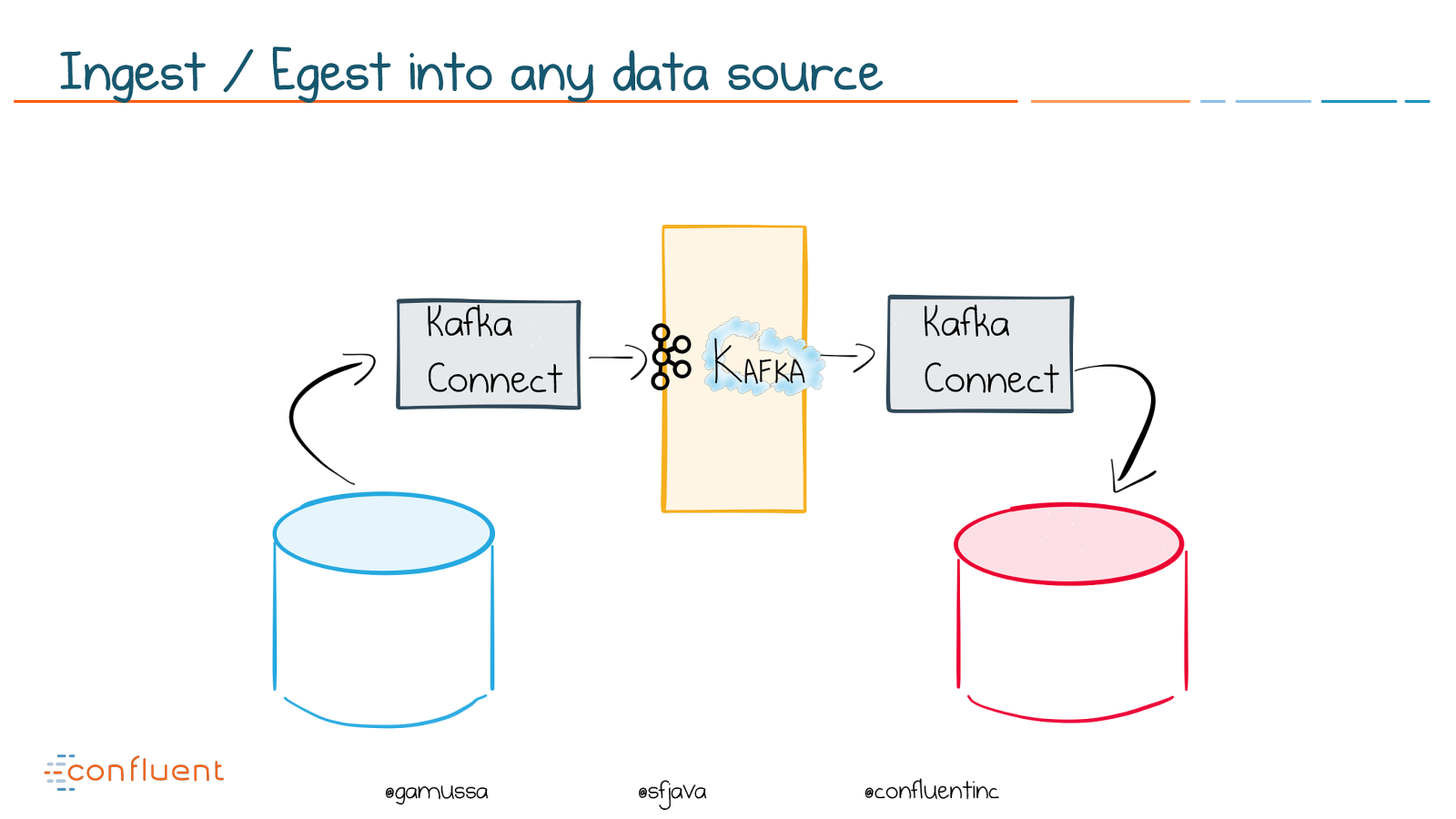
@ @gamussa @sfjava @confluentinc Ingest / Egest into any data source Kafka
Connect Kafka
Connect
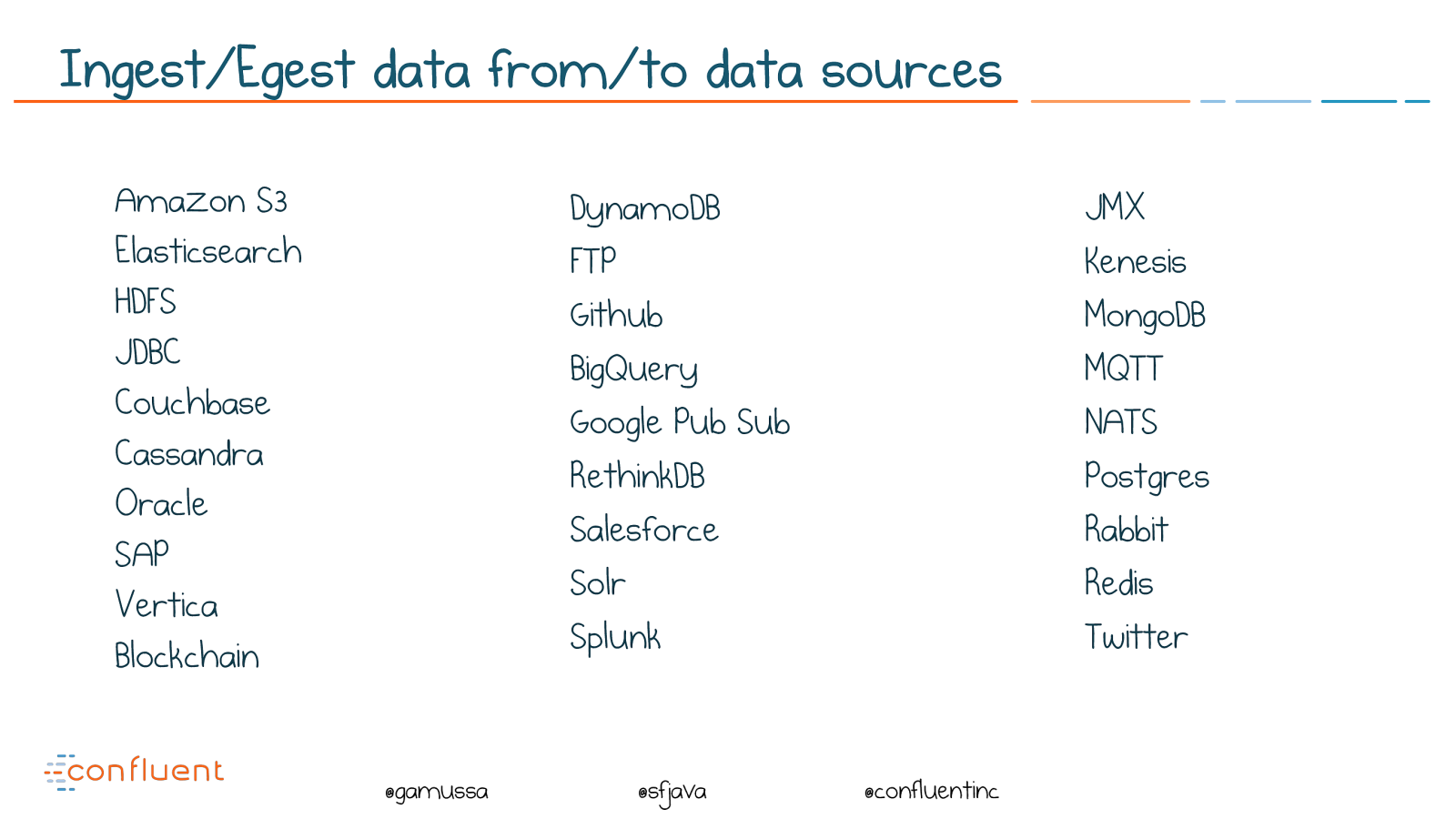
@ @gamussa @sfjava @confluentinc Ingest/Egest data from/to data sources Amazon S3 Elasticsearch HDFS JDBC Couchbase Cassandra Oracle SAP Vertica Blockchain JMX
Kenesis MongoDB
MQTT
NATS
Postgres
Rabbit
Redis Twitter
DynamoDB FTP
Github BigQuery Google Pub Sub
RethinkDB Salesforce
Solr Splunk
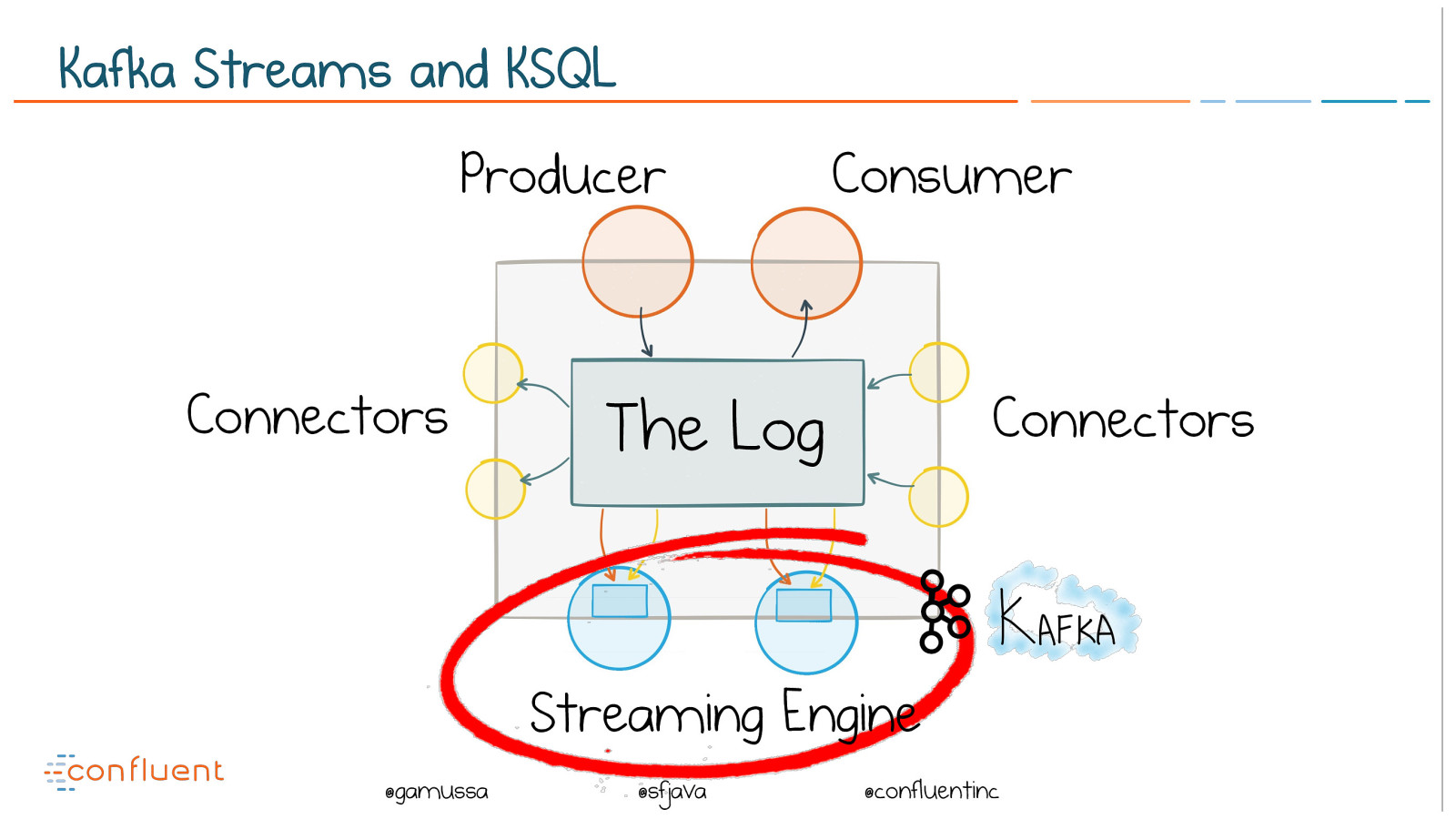
@ @gamussa @sfjava @confluentinc Kafka Streams and KSQL The Log Connectors Connectors Producer Consumer Streaming Engine
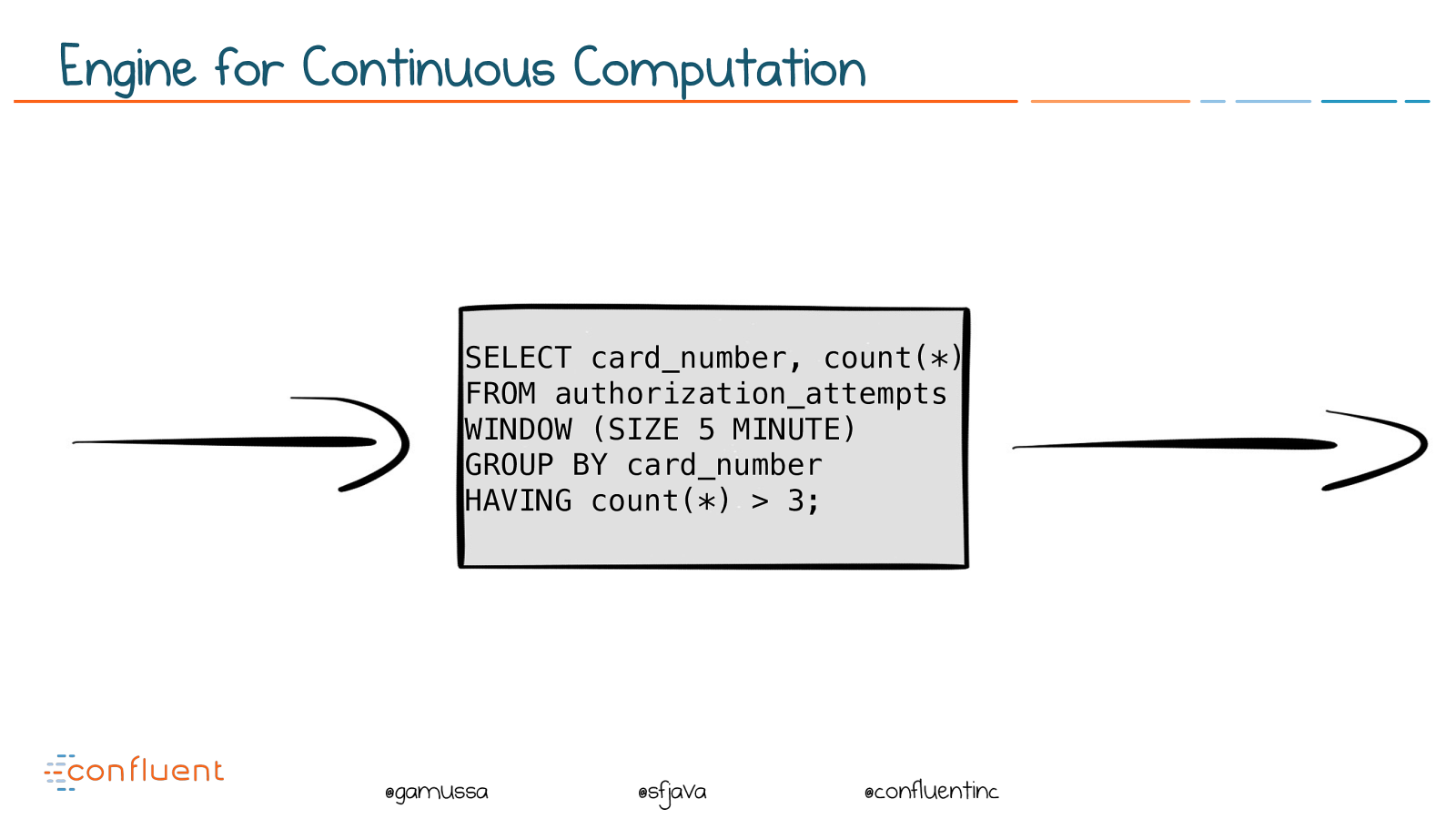
@ @gamussa @sfjava @confluentinc SELECT card_number, count(*)
FROM authorization_attempts
WINDOW (SIZE 5 MINUTE)
GROUP BY card_number
HAVING count(*) > 3;
Engine for Continuous Computation

@ @gamussa @sfjava @confluentinc But it’s just an API public static void main(String[] args) { StreamsBuilder builder = new StreamsBuilder(); builder.stream( "caterpillars" ) .map(StreamsApp !" coolTransformation) .to( "butterflies" );
new KafkaStreams(builder.build(), props()).start(); }
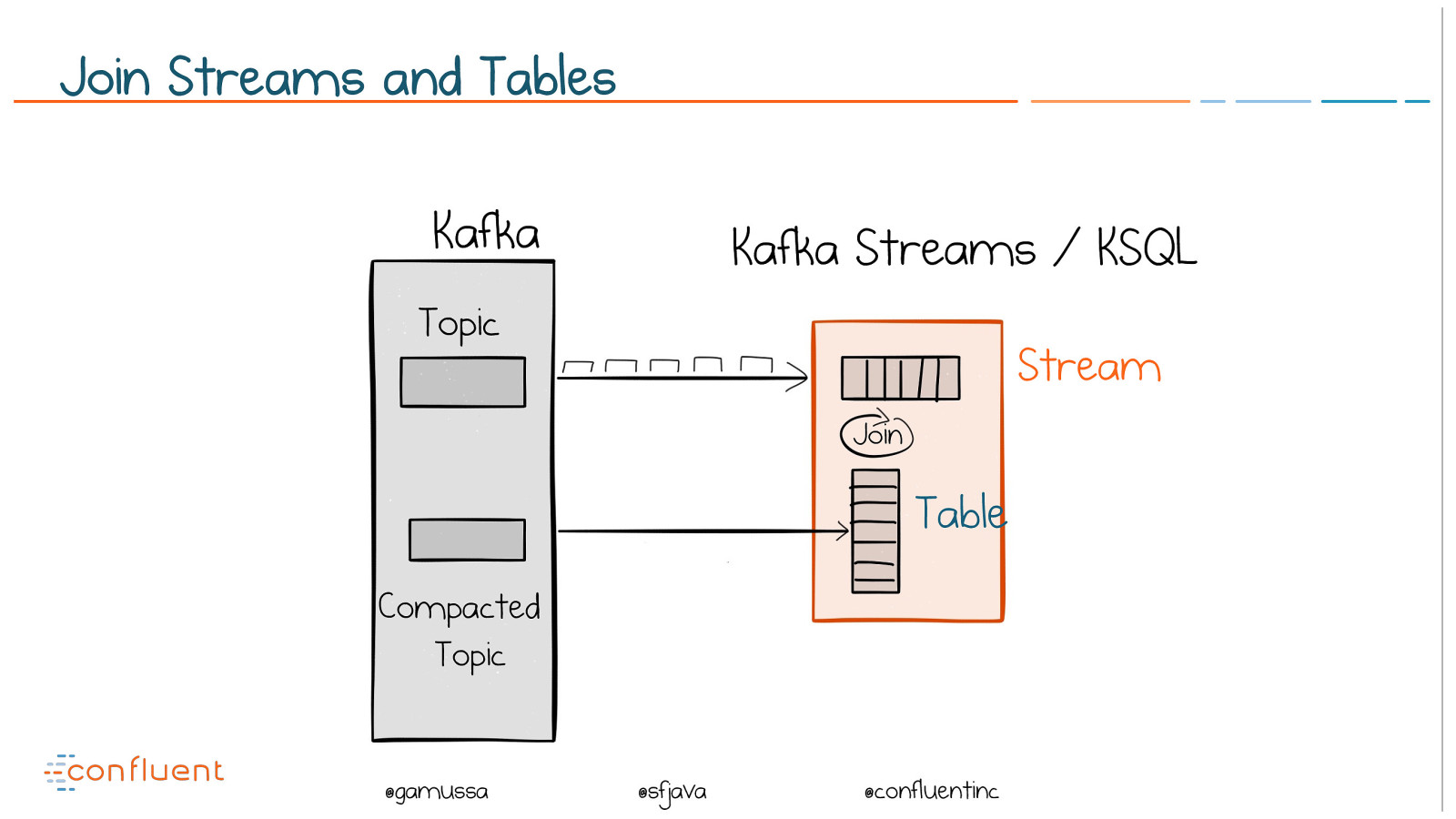
@ @gamussa @sfjava @confluentinc Compacted
Topic Join Stream Table Kafka Kafka Streams / KSQL Topic Join Streams and Tables
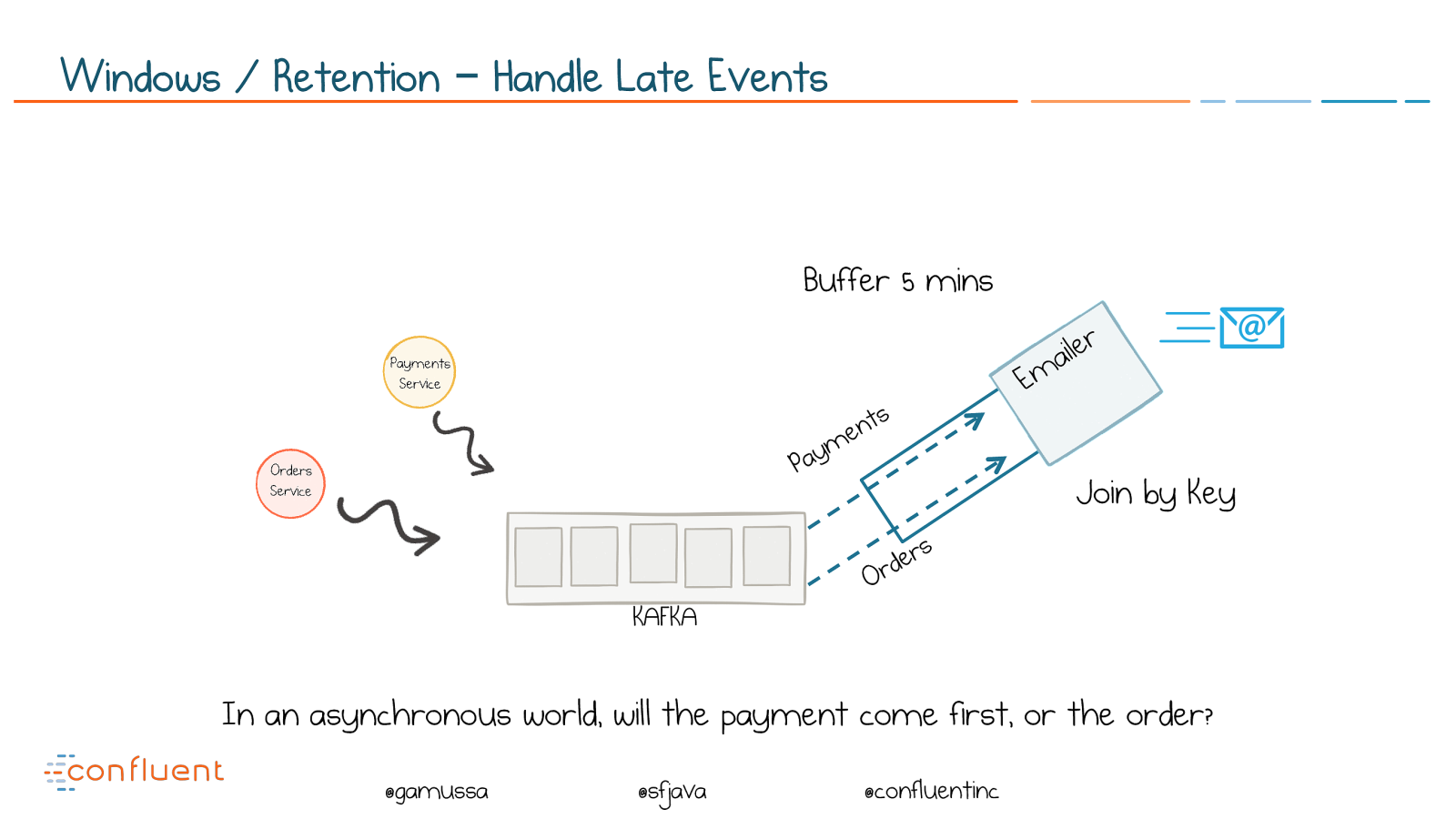
@ @gamussa @sfjava @confluentinc KAFKA Payments Orders Buffer 5 mins Emailer Windows / Retention – Handle Late Events In an asynchronous world, will the payment come first, or the order? Join by Key
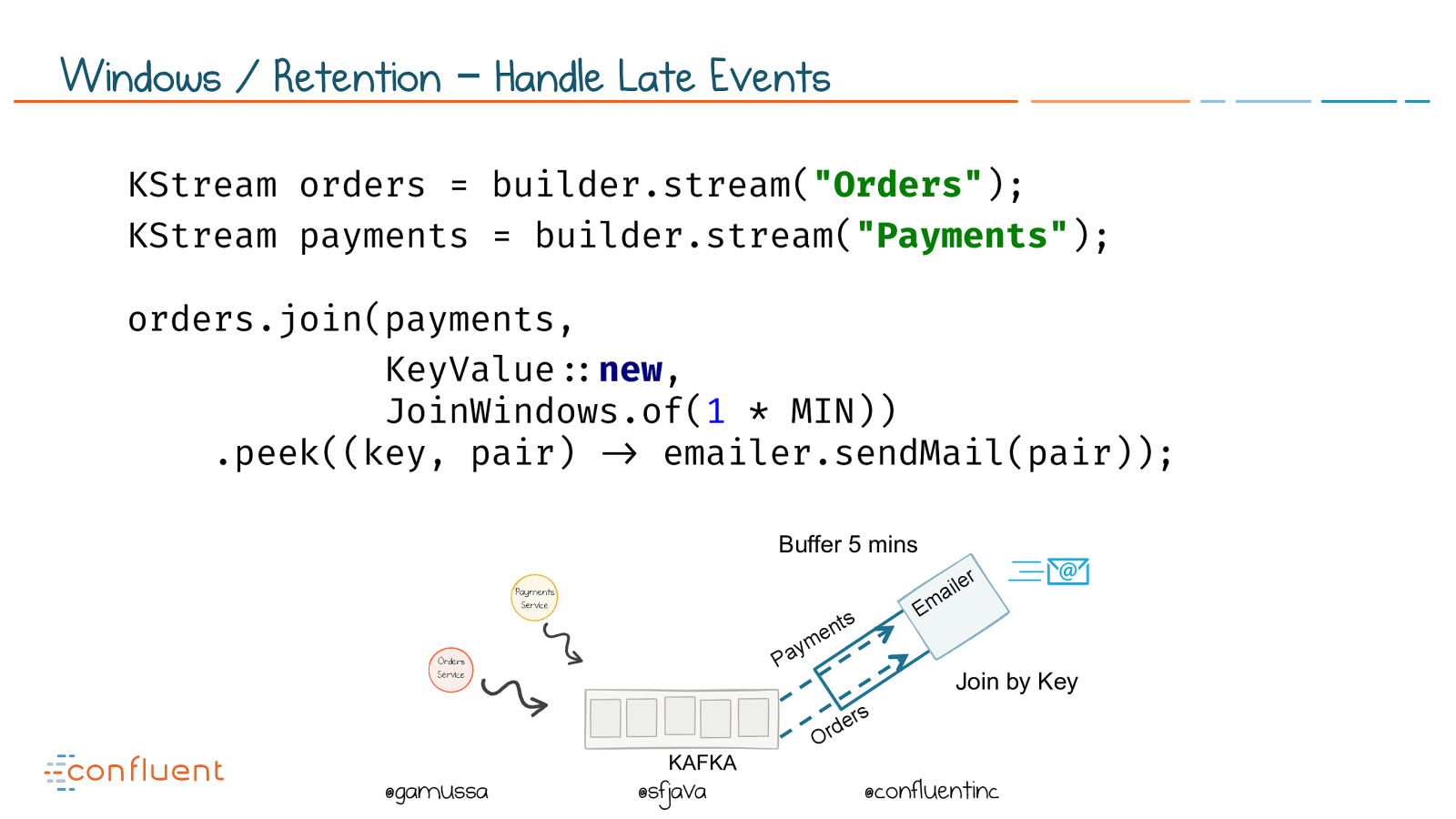
@ @gamussa @sfjava @confluentinc Windows / Retention – Handle Late Events KAFKA Payments Orders Buffer 5 mins Emailer Join by Key KStream orders = builder.stream( "Orders" ); KStream payments = builder.stream( "Payments" ); orders.join(payments, KeyValue !" new , JoinWindows.of( 1
- MIN)) .peek((key, pair) !# emailer.sendMail(pair));
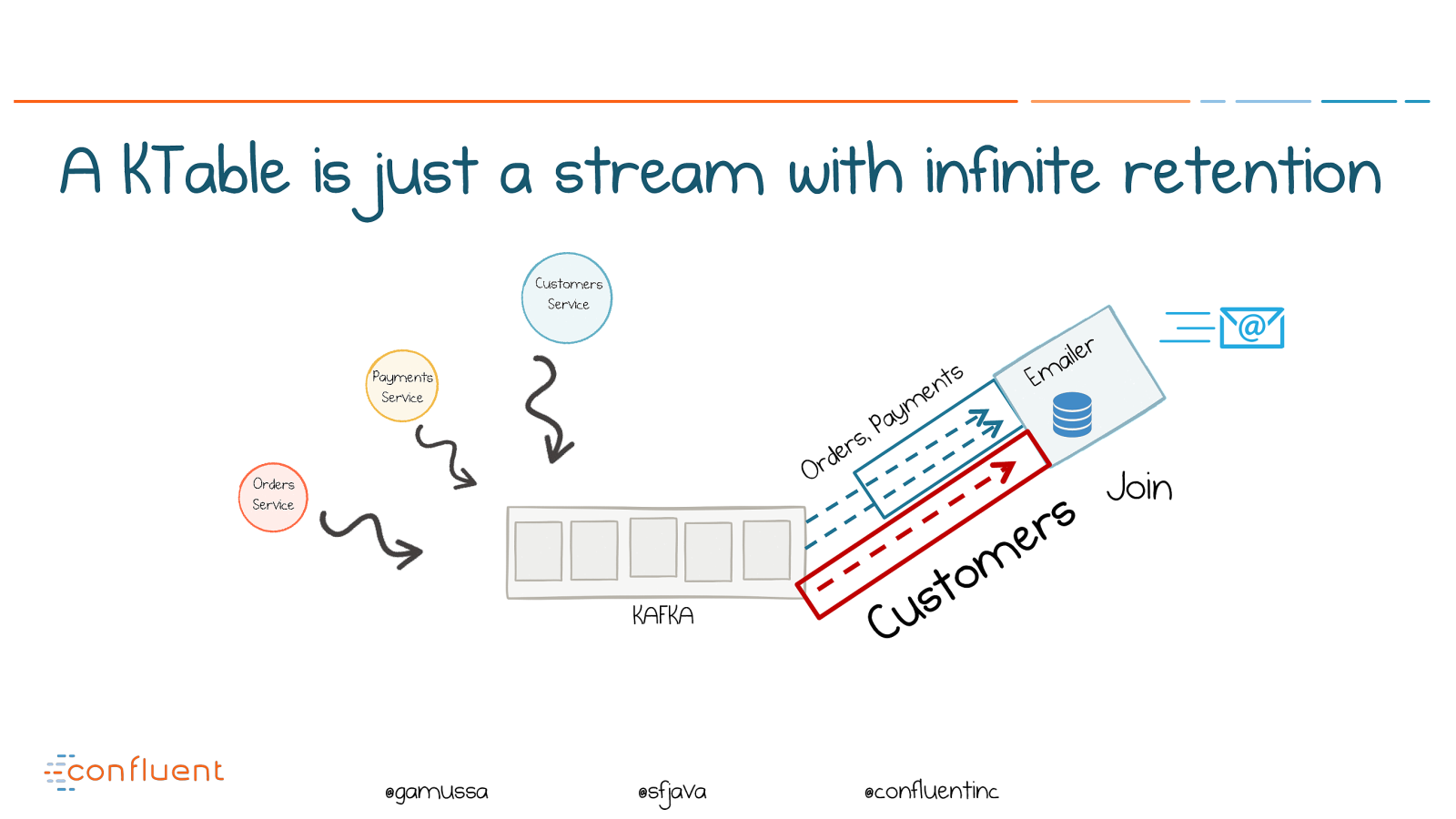
@ @gamussa @sfjava @confluentinc A KTable is just a stream with infinite retention KAFKA Emailer Orders, Payments Customers Join

@ @gamussa @sfjava @confluentinc A KTable is a stream with infinite retention KAFKA Emailer Orders, Payments Customers Join Materialize a table in two lines of code! KStream orders = builder.stream( "Orders" ); KStream payments = builder.stream( "Payments" ); KTable customers = builder.table( "Customers" ); orders.join(payments, EmailTuple !" new , JoinWindows.of( 1 *MIN)) .join(customers, (tuple, cust) !# tuple.setCust(cust)) .peek((key, tuple) !# emailer.sendMail(tuple));
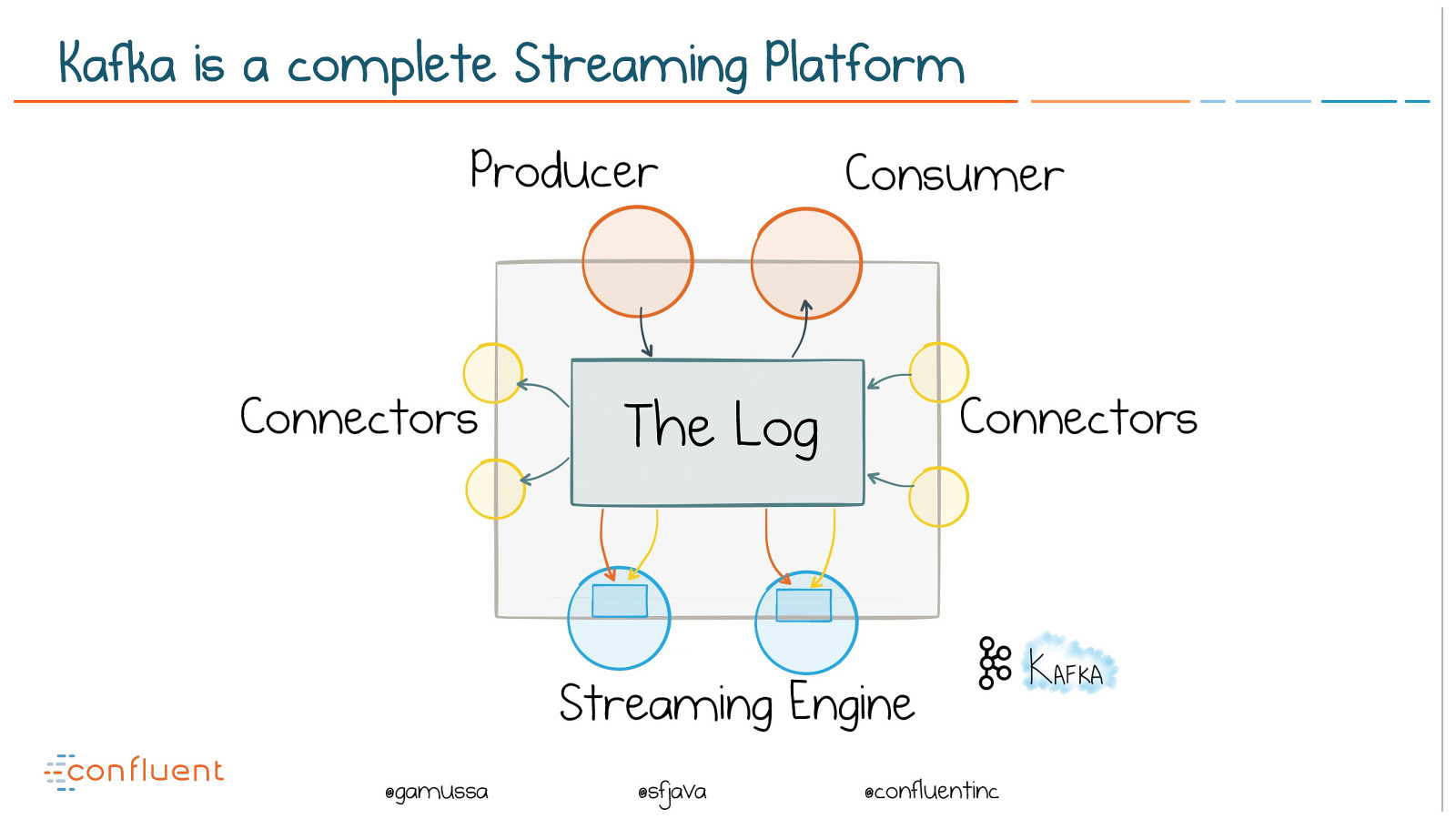
@ @gamussa @sfjava @confluentinc The Log Connectors Connectors Producer Consumer Streaming Engine Kafka is a complete Streaming Platform
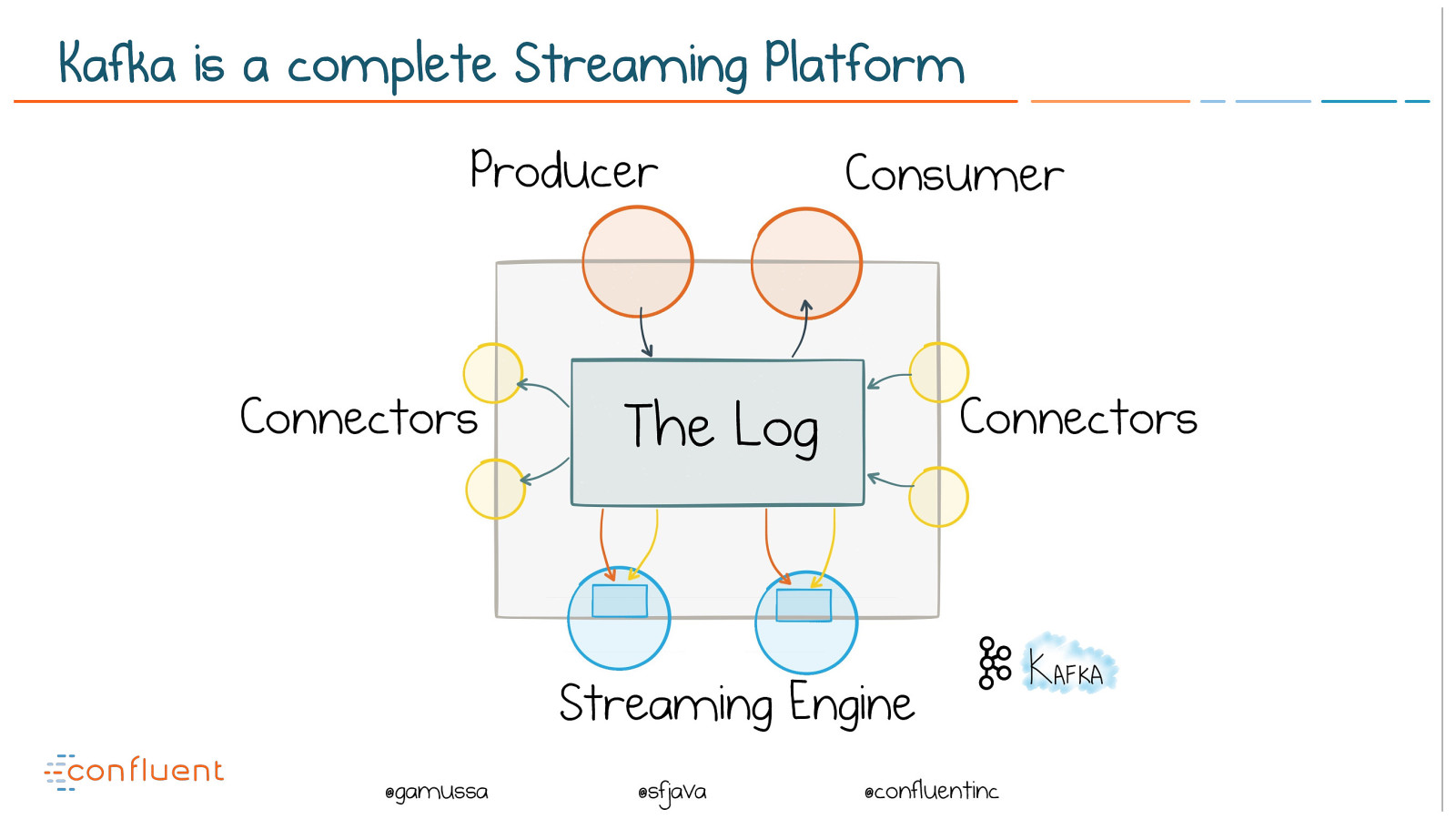
@ @gamussa @sfjava @confluentinc The Log Connectors Connectors Producer Consumer Streaming Engine Kafka is a complete Streaming Platform
@ @gamussa @sfjava @confluentinc https://www.confluent.io/download/

@ @gamussa @sfjava @confluentinc We are hiring! https://www.confluent.io/careers/

@ @gamussa @sfjava @confluentinc One more thing …

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc

@ @gamussa @sfjava @confluentinc
@ @gamussa @sfjava @confluentinc A Major New Paradigm

@ @gamussa @sfjava @confluentinc Thanks ! Stay for #javapuzzlersng!!! @gamussa viktor@confluent.io We are hiring! https://www.confluent.io/careers/

When it comes time to choose a distributed messaging system, everyone knows the answer: Apache Kafka. But how about when you’re on the hook to choose a world-class, horizontally scalable stream data processing system? When you need not just publish and subscribe messaging, but also long-term storage, a flexible integration framework, and a means of deploying real-time stream processing applications at scale without having to integrate a number of different pieces of infrastructure yourself? The answer is still Apache Kafka.
In this talk, we’ll make a rapid-fire review of the breadth of Kafka as a streaming data platform. We’ll look at its internal architecture, including how it partitions messaging workloads in a fault-tolerant way. We’ll learn how it provides message durability. We’ll look at its approach to pub/sub messaging. We’ll even take a peek at how Kafka Connect provides code-free, scalable, fault-tolerant integration, and how the Streams API provides a complete framework for computation over all the streaming data in your cluster.